AI、ML与DL:深度拆解三者本质差异与演进逻辑
厘清概念:技术金字塔的层级逻辑
在当前的科技语境中,人工智能(AI)、机器学习(ML)与深度学习(DL)这三个术语频繁出现在媒体头条、技术论坛乃至日常对话中。尽管它们经常被交替使用,但从技术架构和逻辑层级来看,它们并非同义重复,而是构成了一个严谨的包含与演进关系。理解这三者的本质区别,是洞察整个智能技术体系的基础。
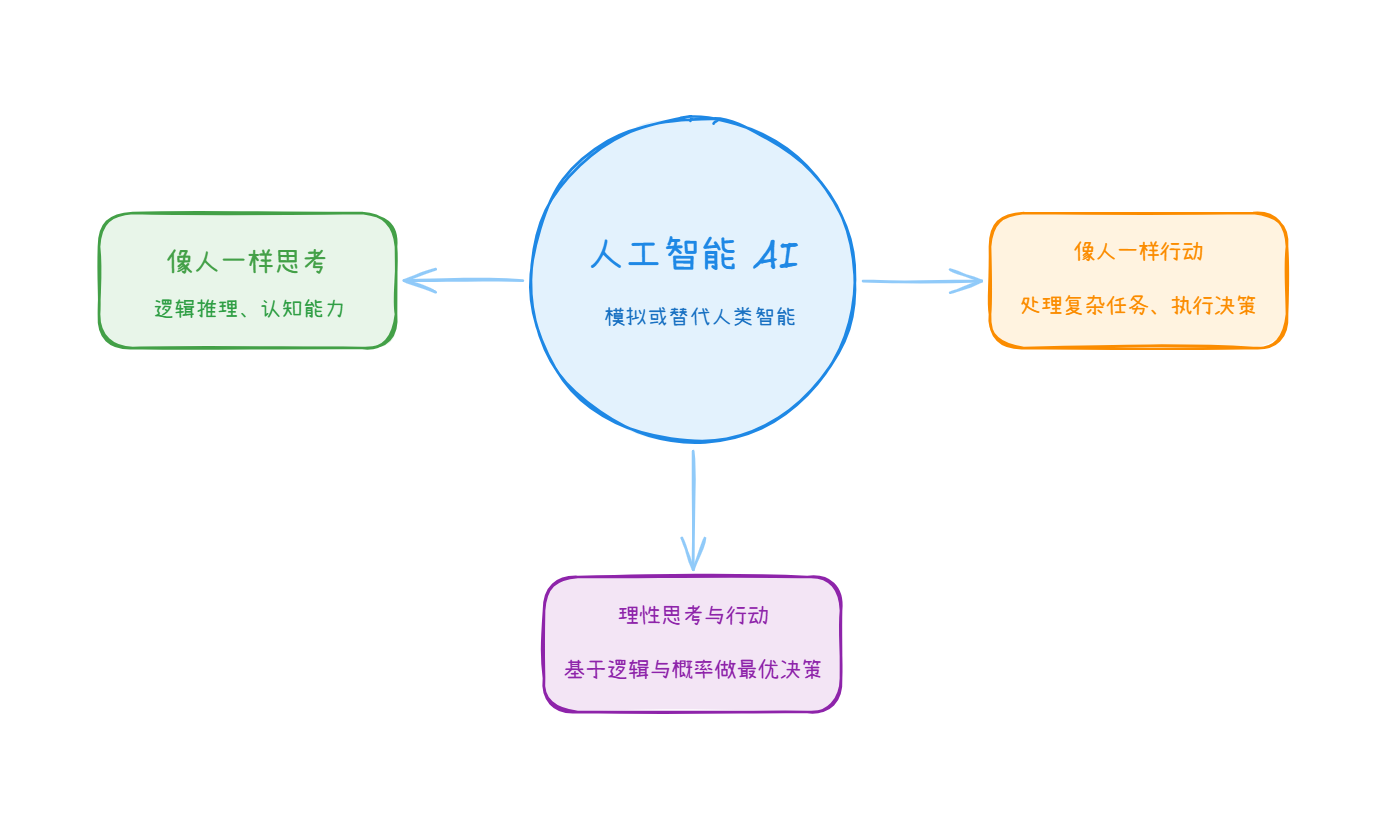
人工智能是一个宏大的计算机科学分支,其终极目标在于研发能够模拟、延伸和扩展人类智能的理论、方法及应用系统。一个理想的人工智能系统,应当具备像人一样思考、像人一样行动,并且能够理性地思考与行动的能力。它不仅仅局限于某一种具体的算法,而是一套涵盖感知、认知、决策和执行的完整技术愿景。
相比之下,机器学习是实现人工智能的一种核心手段或子集。它不依赖于人工编写的显式规则,而是通过算法让计算机系统从数据中学习规律,从而对未知的数据做出预测或判断。如果说AI是我们要攀登的高峰,那么机器学习就是攀登者手中那根最有力的登山杖。
深度学习则是机器学习的一个特定子集,也是近年来引发技术爆发的关键流派。它受到人类大脑神经元结构的启发,通过构建包含多层隐藏层的神经网络(即深度神经网络),自动从原始数据中提取高维特征并进行复杂模式的识别。深度学习之所以在近年来取得突破性进展,很大程度上归功于它在处理非结构化数据(如图像、音频、文本)时表现出的卓越能力。
范式转移:从规则驱动到模型驱动
要深刻理解机器学习的价值,必须将其与传统编程范式进行对比。传统软件开发主要依赖“规则驱动”的模式。在这种模式下,程序员是逻辑的绝对制定者。他们需要将业务逻辑拆解为细碎的 if-else 条件语句,明确告诉计算机:当输入为A且条件B满足时,输出C。
这种模式在处理边界清晰、逻辑固定的问题时极为高效,例如税务计算、银行账务处理等。然而,当面对复杂多变的现实世界问题时,这种方式的局限性便暴露无遗。以图像识别为例,如果要通过传统代码识别一辆汽车,程序员需要编写无数条规则:“如果检测到圆形物体”、“如果检测到矩形车窗”、“如果颜色为灰色”……
现实世界没有固定的模板。光照变化、拍摄角度、物体遮挡、背景干扰等因素会导致同一对象的视觉特征发生剧烈变化。试图通过穷举所有可能情况来覆盖规则,不仅工程复杂度呈指数级增长,而且根本无法保证鲁棒性。随着规则数量的增加,系统的维护成本将远远超过其带来的价值。
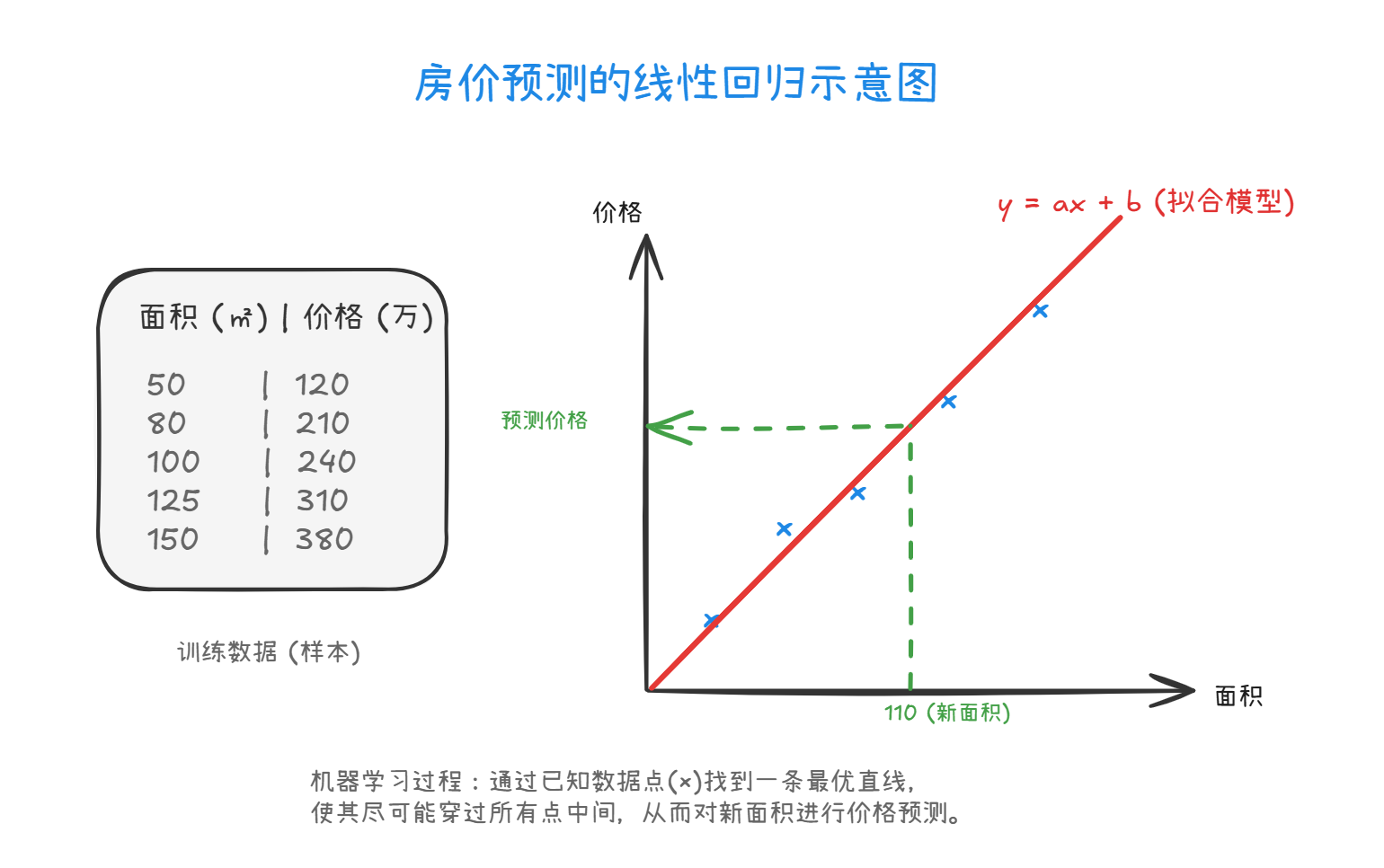
机器学习采用了一种截然不同的“模型驱动”范式,其核心在于归纳法。我们不再编写具体的规则,而是向算法提供大量的历史数据(输入特征与对应标签)。算法通过分析这些数据,自动寻找数据内部的统计规律,并构建出一个数学模型。
以房价预测为例,假设我们拥有某城市过去十年的房屋交易数据,包括面积、地段、房龄等特征,以及最终成交价。机器学习算法(如线性回归)会尝试找到一个函数关系 y = ax + b,使得这条直线尽可能拟合所有历史数据点。一旦确定了参数 a 和 b,这个模型就学会了“房价与面积及地段的关系”。当输入一个新的房屋数据时,模型便能基于学到的规律给出预测价格。这种从数据中自动学习规律的能力,正是机器学习的精髓所在。
历史脉络:AI发展的三次浪潮
人工智能并非凭空出现的新生事物,其发展历程充满了曲折与复兴。回顾过去七十多年,AI的发展主要经历了三次显著的浪潮,每一次浪潮都标志着技术范式的重大转变。
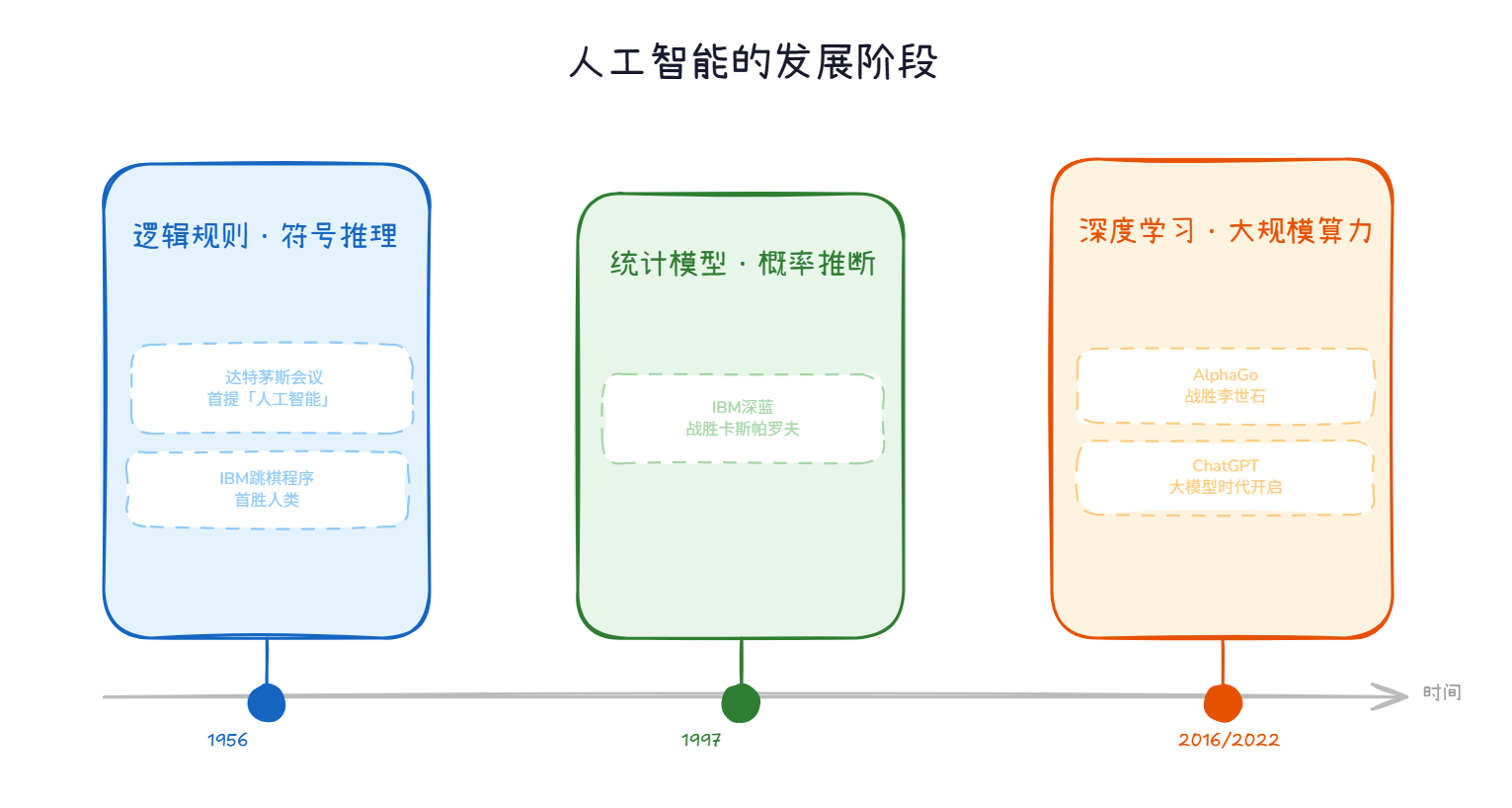
第一次浪潮(1950-1970年代):符号主义主导。 1956年达特茅斯会议正式提出了“人工智能”这一术语,标志着AI学科的诞生。这一阶段的研究主要集中在逻辑推理和符号处理上,试图通过编写规则让计算机模拟人类的逻辑推理过程。标志性事件包括IBM开发的跳棋程序战胜人类选手。然而,由于当时算力有限且缺乏有效的数据积累,符号主义在处理模糊、不确定和感知类问题时遭遇瓶颈,导致AI进入了一段低谷期。
第二次浪潮(1980-2000年代):统计主义兴起。 随着专家系统的局限性显现,研究者开始转向基于统计模型的方法。这一阶段,概率图模型、支持向量机等技术逐渐成熟,并被应用于语音识别、文本分类等实际任务。1997年,IBM的深蓝超级计算机在国际象棋比赛中战胜世界冠军卡斯帕罗夫,这是统计主义和方法论优化的一次巨大胜利,证明了计算机可以在特定博弈领域超越人类智能。
第三次浪潮(2010年至今):深度学习爆发。 这是当前我们所处的时代。随着互联网带来的海量数据积累、GPU等硬件算力的飞跃以及反向传播算法等理论突破,深度学习迎来了复兴。2016年,AlphaGo战胜围棋世界冠军李世石,展示了深度学习在复杂策略游戏中的统治力。随后,2022年ChatGPT的出现更是将大语言模型推向了高潮,标志着AI从感知智能向认知智能的跨越。
爆发基石:数据、算法与算力的三角共振
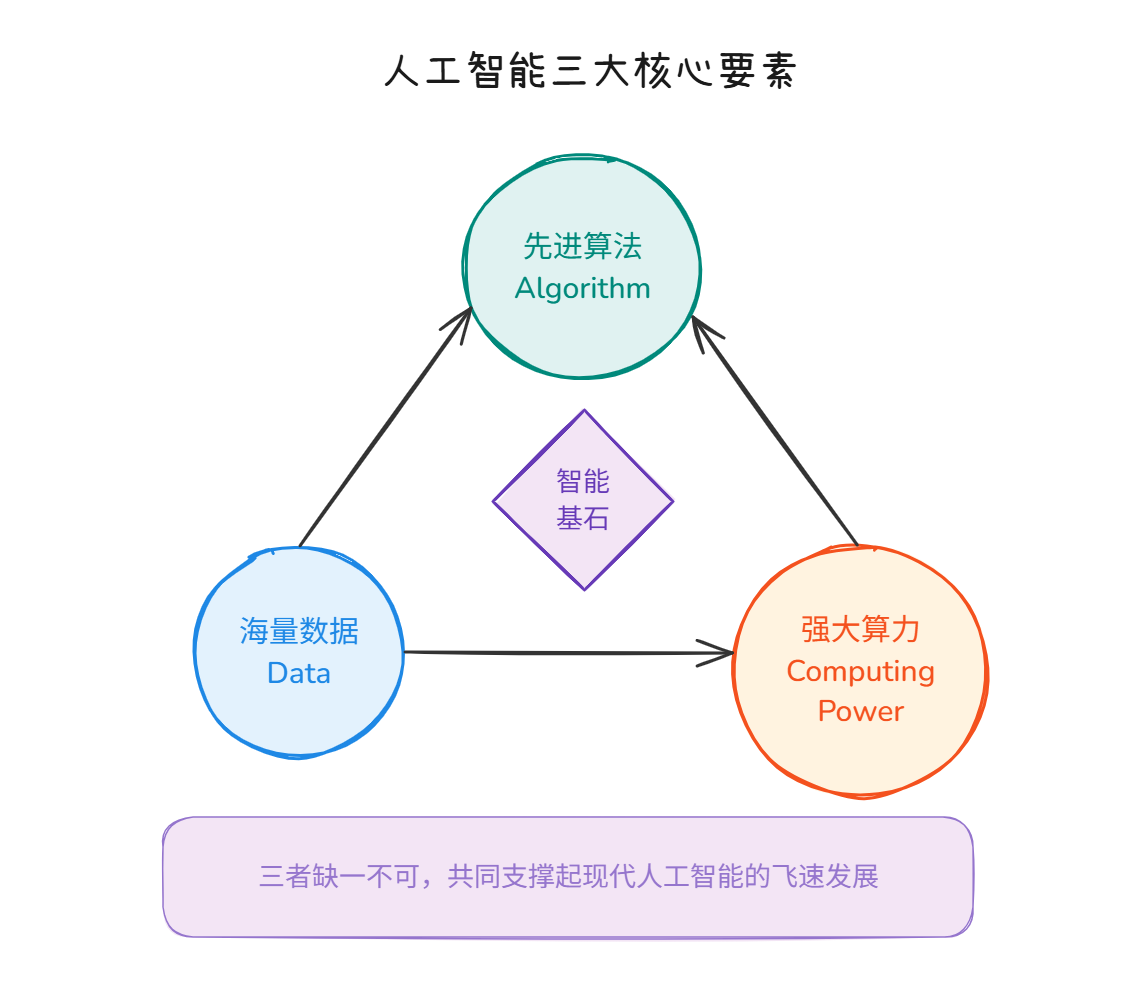
为什么人工智能在近年来才呈现出爆炸式的增长?这并非偶然,而是数据、算法和算力三大基础要素共同作用的结果。这三者构成了现代AI发展的“铁三角”,缺一不可。
首先是数据。在互联网时代,人类产生了前所未有的海量数据。无论是社交媒体上的文本、电商平台的交易记录,还是医疗影像、自动驾驶传感器采集的图像,这些数据成为了训练模型的“燃料”。没有高质量的大规模数据集,深度学习模型就无法捕捉到复杂的数据分布特征。
其次是算法。深度学习算法的突破是核心驱动力。卷积神经网络(CNN)在图像识别领域的成功,循环神经网络(RNN)及Transformer架构在自然语言处理中的革命,使得机器能够自动提取特征并进行端到端的学习。特别是注意力机制(Attention Mechanism)的引入,彻底改变了序列建模的方式,为大型语言模型奠定了基础。
最后是算力。神经网络的训练需要处理巨大的矩阵运算,这对硬件提出了极高要求。传统的CPU擅长逻辑控制和串行处理,但在这种大规模并行计算任务面前显得力不从心。GPU(图形处理器)凭借其强大的并行计算能力,成为训练深度学习模型的主力军。此外,专用芯片如TPU(张量处理单元)的出现,进一步加速了特定类型张量运算的效率,降低了训练成本。
核心术语解析:构建数据认知的基石
在深入机器学习的技术细节之前,掌握一些核心术语有助于我们更好地理解模型的工作机制。这些术语是连接现实世界问题与计算机可处理数据之间的桥梁。
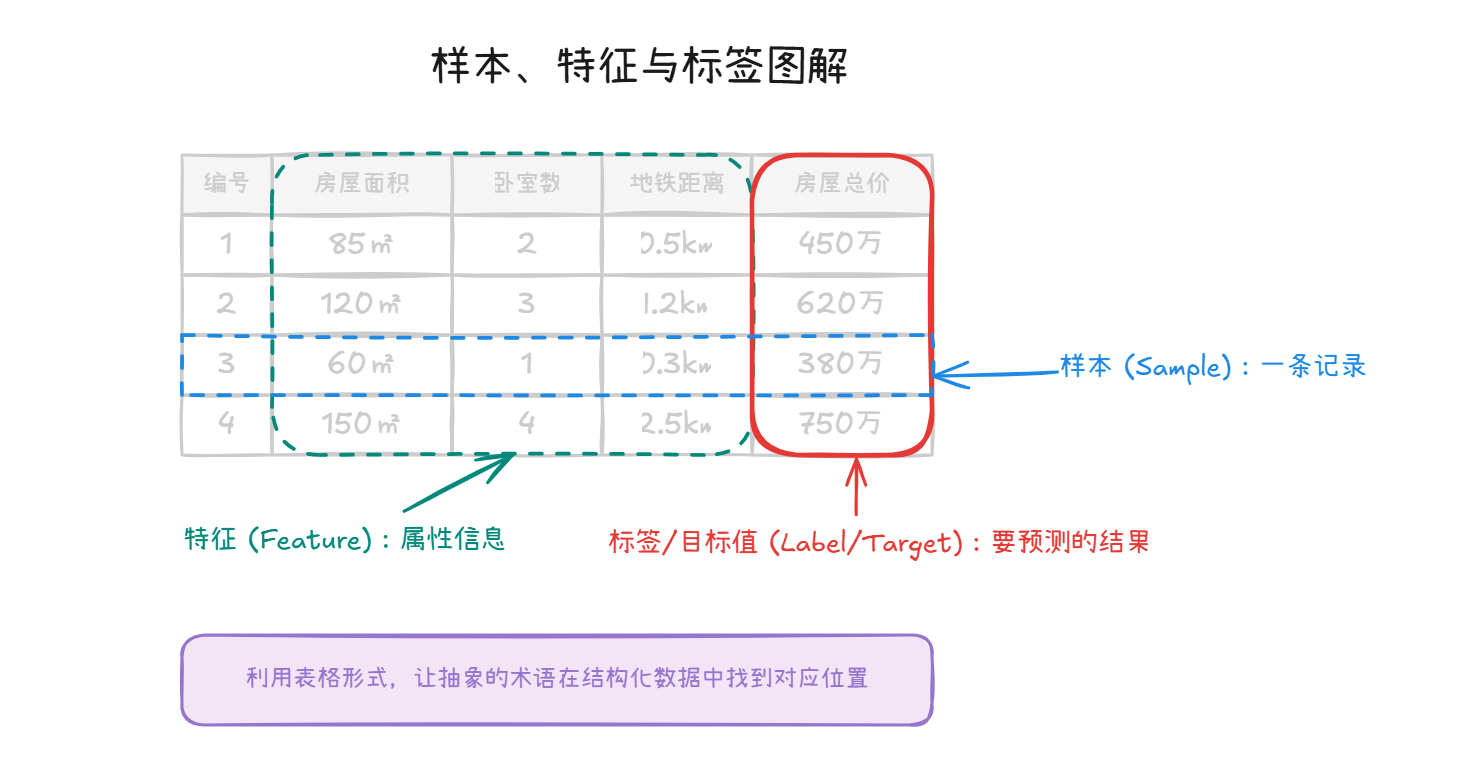
样本(Sample):样本代表现实世界中的一个实体或一条记录。在数据结构中,通常表现为一行数据。例如,在房价预测中,每一栋被记录的房屋就是一个样本。
特征(Feature):特征是从数据中抽取出来的、对预测结果有用的属性信息。在数据表中,特征通常表现为列。在房价预测中,房屋的面积、卧室数量、距市中心距离等都是特征。特征工程的质量往往直接决定了模型的上限。
标签/目标值(Label/Target):这是模型要预测的那一列数据,也是模型学习的最终答案。在监督学习中,我们提供带有标签的数据,让模型学习从特征到标签的映射关系。
数据集划分(Dataset Splitting):为了验证模型的有效性和泛化能力,我们不能使用所有数据进行训练。通常将数据集按比例(如8:2或7:3)划分为训练集和测试集。训练集用于让模型学习规律,调整参数;测试集则用于评估模型在未见过的数据上的表现,防止过拟合现象。
结语:回归本质,把握智能未来
人工智能、机器学习与深度学习,构成了当前智能技术体系的完整图谱。AI是顶层的目标与愿景,机器学习是实现这一目标的主流路径,而深度学习则是这条路径上目前最为强大的技术引擎。
通过理解传统规则驱动与模型驱动的本质区别,我们能看到技术从“硬编码”向“自适应”进化的必然趋势。通过回顾三次浪潮,我们理解了技术爆发背后的积累与突破。通过审视数据、算法、算力三大基石,我们看清了推动行业前进的核心动力。
在面对纷繁复杂的技术名词时,厘清层级关系比死记硬背概念更为重要。随着技术的不断演进,我们不仅需要关注前沿模型的参数规模,更应深入理解其背后的数学原理与应用逻辑。唯有如此,才能在智能时代的浪潮中,精准把握机遇,实现技术落地与商业价值的真正转化。
