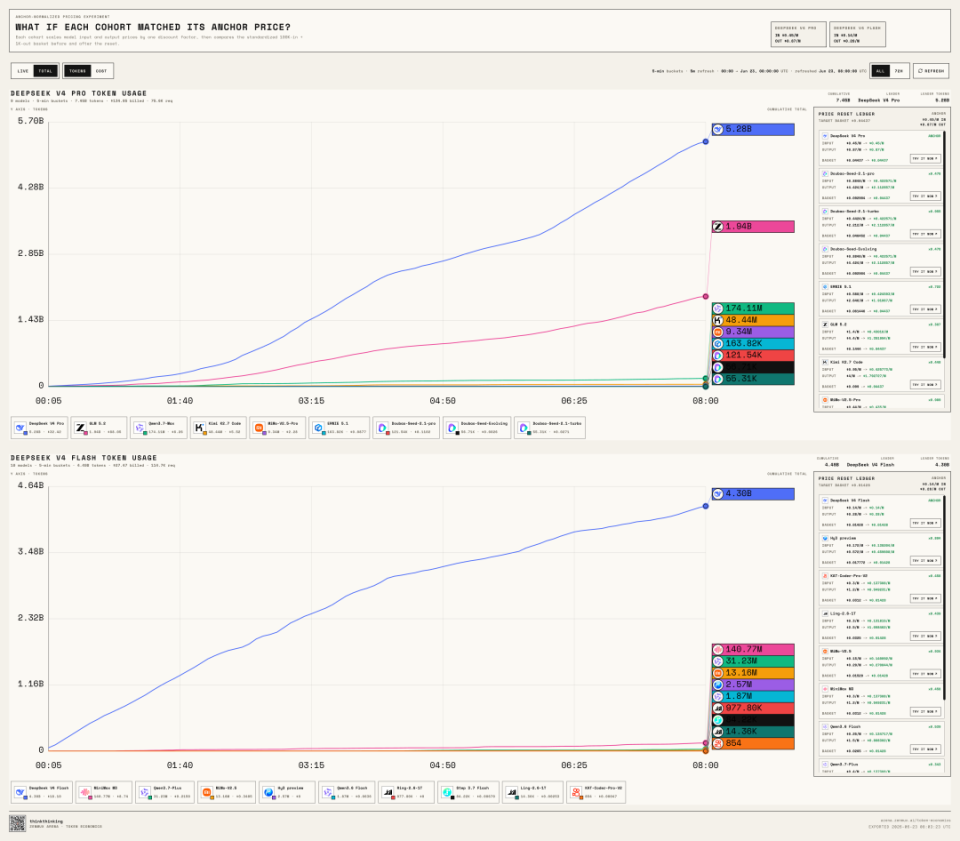
DeepSeek斩杀线:当模型价格归一化,开发者真实选择大揭秘
价格迷雾下的真实较量
在人工智能模型飞速迭代的今天,市场往往被发布会上的性能参数和Benchmark排名所主导。然而,对于身处一线的开发者而言,决定一个模型生死的往往不是论文里的准确率,而是真实的API调用量和账单金额。DeepSeek V4 Pro的出现,不仅以其卓越的推理能力撼动了市场,更以其极具侵略性的定价策略,在开发者社区中树立了一个新的参照系。这种现象被形象地称为“DeepSeek斩杀线”——当一个模型同时具备可用效果、极低价格和稳定工程接入时,它便形成了一道新的价格锚点,迫使其他所有模型直面“贵得是否值得”的灵魂拷问。
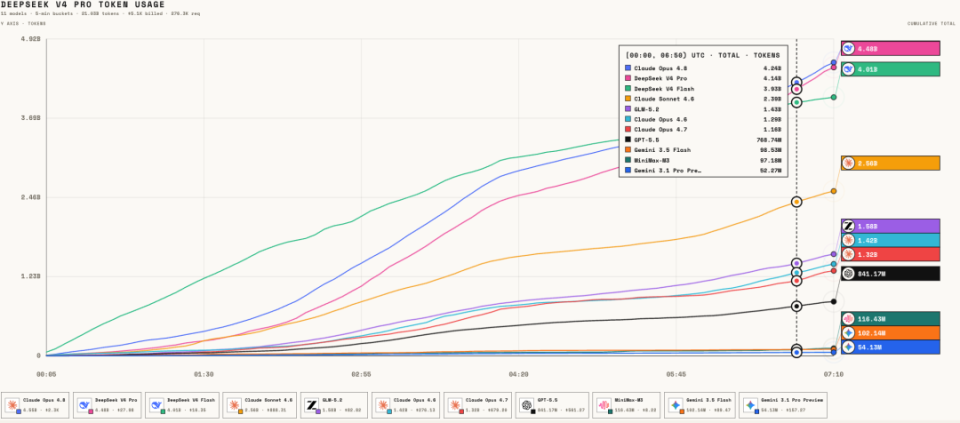
为了探究在剥离价格因素后,模型市场的真实生态,ZenMux平台启动了一项名为“Token经济学”的深度研究。这项研究的核心假设极其朴素:如果我们将各大厂旗舰模型的价格强行拉平至DeepSeek V4 Pro的水平,开发者会如何选择?是继续忠诚于原有品牌,还是转向那些可能更具潜力的新势力?这不仅仅是一次价格模拟,更是一场关于开发者信任、工具链依赖模型能力的压力测试。
后验主义视角:用量即真理
传统的模型评价往往陷入“先验主义”的陷阱,即过度依赖官方公布的理论性能。但在实际的软件开发、Agent构建和复杂Coding场景中,这些指标往往与真实体验存在偏差。本研究采用了一种“后验主义”的方法论,将复杂的模型能力、品牌光环、营销噪音收敛为两个最核心的可观测变量:价格与用量。
这种视角的转变至关重要。在ZenMux这样一个多模型聚合平台上,开发者每一次点击“运行”,实际上都是一次真金白银的投票。如果一个模型足够好用、稳定且易于集成,其价值最终会体现在Token的消耗曲线中。因此,我们不再争论谁在发布会上更厉害,而是关注谁在用户的真实工作流中被反复调用。这种基于市场选择的观察视角,虽然受限于平台样本,但却更贴近开发者日常使用的微观真相。
构建价值天平:归一化方法论
为了公平地比较不同发布时间、不同计费模式的模型,研究构建了一套严谨的归一化算法体系。首先,针对累计用量的时间偏差,我们采用“有实际用量工作日”的中位数来计算模型的归一化日用量。这一方法有效规避了新模型发布初期的尖峰数据干扰,更真实地反映了模型在常规工作日中的承载能力。
其次,鉴于AI Coding和Agent场景中输入Token占比极高的特点(通常输入输出比例约为100:1),我们定义了一个标准价格篮子:100K Input Tokens + 1K Output Tokens。通过将输入价格和输出价格加权合并,计算出每个模型的归一化价格 $P_m$。这一处理使得输入端的价格权重被合理放大,符合当前开发者在高并发、长上下文场景下的成本敏感特征。
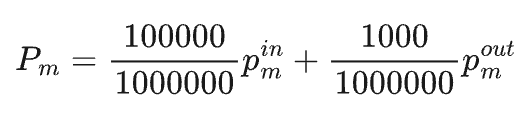
最终,通过计算“用量除以价格”的比值,我们得出了衡量模型综合竞争力的核心指标——Value。这个指标并非简单的性价比排行,而是反映了“每投入1美元成本,模型在真实工作流中能产生的Token价值”。它兼顾了价格优势与市场认可度,一个便宜但无人问津的模型,其Value值不会高;而一个昂贵但被广泛使用的模型,其Value值依然强劲。
四大象限:模型市场的生态位分析
基于Value Map模型,我们将各大厂旗舰模型划分为四个象限,揭示了截然不同的市场策略与命运。
DeepSeek:斩杀线的定义者
DeepSeek V4 Pro和V4 Flash牢牢占据了“低价格+高用量”的第一象限。这并非偶然,而是其技术架构与定价策略高度协同的结果。DeepSeek的成功在于它不仅提供了极具竞争力的价格,更提供了极高的缓存命中率(Cache Hit)和工程稳定性。对于开发者而言,这意味着在长上下文和复杂Agent循环中,实际账单远低于名义价格。DeepSeek由此确立了一条新的行业基准线,迫使整个市场重新审视价值定义。
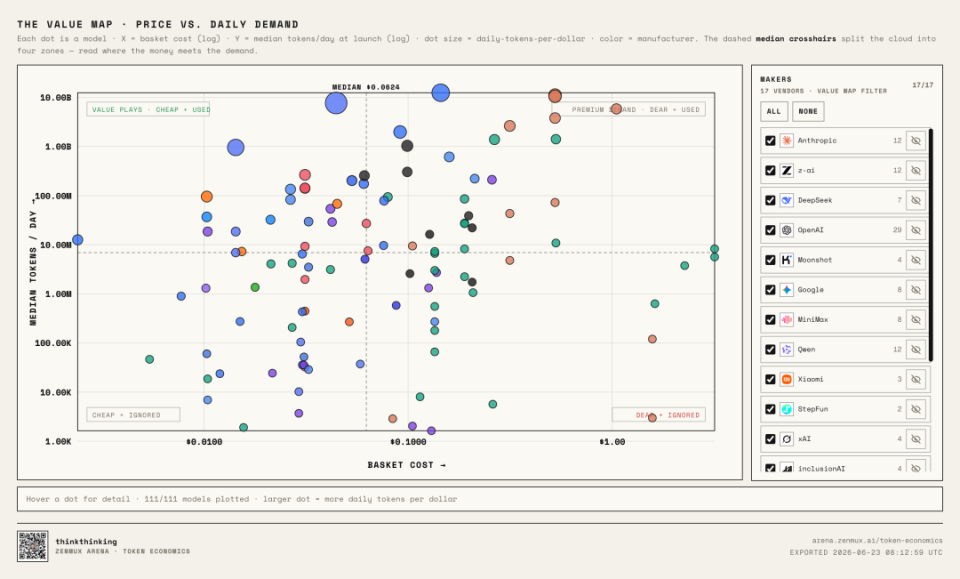
Anthropic:奢侈品的胜利
Anthropic的Claude系列(特别是Opus 4.8/4.7/4.6)则完美诠释了“高价格+高用量”的奢侈品路线。尽管价格高昂,但Claude在复杂推理、长任务处理和工具调用方面的稳定性,使其成为关键业务场景的首选。开发者愿意为这种“确定性”支付溢价。这证明了在模型市场,只要能力上限足够高,价格并非不可逾越的障碍。Claude的策略清晰而坚定:我不拼低价,我拼的是不可替代的专业价值。
OpenAI:在两者之间摇摆
OpenAI的GPT系列呈现出复杂的分布特征。虽然拥有GPT-5 Nano等低价模型,但其在真实工作流中的用量并未形成压倒性优势。相反,其旗舰模型GPT-5.4/5.5正逐渐向Anthropic的高价高用量区间靠拢。这表明OpenAI的策略正在调整:低价模型用于覆盖长尾场景,而旗舰模型用于证明技术上限。然而,在ZenMux的数据中,“便宜”并不自动等同于“被选择”,开发者最终依然流向那些在Coding和逻辑推理上表现更稳健的模型。
智谱GLM:中国模型的突围
在国产模型中,智谱GLM 5.2的表现尤为亮眼。它正在摆脱“中国模型=低价平替”的刻板印象,向高用量旗舰模型的位置发起冲击。GLM 5.2的出现,标志着中国大模型厂商开始尝试在保持竞争力的同时,追求更高的品牌溢价和技术认可。这与OpenAI的双轨制策略不谋而合,预示着未来中国模型市场的竞争将从单纯的价格战转向价值战。
价格归一化实验:谁是下一个赢家?
为了验证价格因素对开发者选择的真实影响,我们发起了一场名为“DeepSeek斩杀线挑战”的实时实验。我们将包括GLM 5.2、Kimi K2.7 Code、Qwen3.7 Max、MiniMax M3等在内的主流东方模型,其归一化价格强制对齐至DeepSeek V4 Pro或V4 Flash的水平。
例如,Qwen3.7 Max的归一化价格从0.2575美元大幅降至0.04437美元,降幅高达82.8%。在这一“公平起跑线”上,我们观察开发者是否会因价格优势而转向这些模型,或者他们是否依然忠诚于原有的技术偏好。
这一实验的核心目的在于剥离价格噪音,检验模型本身的吸引力。如果某些模型在价格降至DeepSeek水平后,依然无法获得相应的用量增长,则说明其竞争力不仅在于价格,更在于生态位、工具链集成度或品牌信任度。反之,如果用量激增,则验证了价格确实是阻碍其大规模普及的关键瓶颈。
结论:用量是最终的投票
模型市场的竞争逻辑正在发生深刻变革。价格不再是唯一的护城河,甚至不是最重要的护城河。DeepSeek V4 Pro所设立的“斩杀线”,本质上是对模型综合效能的一次极致拷问:当技术差距缩小,成本成为主要变量时,谁能提供更高的人效比?
研究表明,未来的赢家必须具备三种特质:极致的成本控制能力、稳定可靠的工程表现,以及在特定垂直领域(如Coding、Agent)的不可替代性。无论是Anthropic的“高价高值”还是DeepSeek的“低价高量”,其成功本质都是对用户需求的精准响应。
对于开发者而言,选择模型不再是一个非黑即白的单选题,而是一个动态平衡的过程。对于厂商而言,单纯的降价促销已不足以赢得市场,必须通过技术创新降低推理成本,同时提升模型在真实工作流中的有效产出。Token曲线上的每一次跳动,都是开发者用脚投出的最诚实一票。在这场Token经济学的博弈中,唯有真正理解用户痛点、优化成本结构并持续提升核心能力的模型,才能穿越周期,成为行业的新标杆。