智能进化的速度质变:从季更到月更的必然
人工智能领域的竞争节奏正在经历一场前所未有的加速。过去,大模型厂商的迭代周期往往以季度甚至半年为单位,每一次重大版本发布都伴随着长时间的打磨与等待。然而,进入 2026 年,这一规律被彻底打破,全球主流模型公司——包括 Anthropic、OpenAI、腾讯以及曾沉寂许久的 DeepSeek——纷纷将迭代周期压缩至月度级别。
这种“月更时代”的到来并非偶然,而是技术积累与市场需求双重作用的结果。当 AI 开始加速 AI,即利用人工智能技术本身来优化模型训练、代码生成与架构设计时,研发效率呈指数级提升。过去两周的高密度发布潮便是明证:Anthropic 推出 Opus 4.7,OpenAI 迭代 GPT-5.5 并升级 Image 2.0,腾讯发布 Hy3 preview,DeepSeek 则以 V4 强势回归。这些模型不再是简单的参数堆砌,而是在架构逻辑、推理效率与任务规划能力上发生了质的飞跃。
这种高频迭代对行业生态产生了深远影响。一方面,技术红利的释放速度加快,开发者能够迅速获得更强大的工具;另一方面,这也给算力基础设施、数据治理以及产品落地带来了巨大的挑战。模型能力的快速跃迁,使得旧有的技术栈迅速过时,企业和个人开发者必须保持极高的敏捷度,才能在新一轮的智能竞赛中占据主动。
核心模型实测:能力边界的重新定义
在最新的模型浪潮中,Opus 4.7、GPT-5.5 与 DeepSeek V4 代表了当前技术路线的三种不同探索方向,它们在实际应用中的表现呈现出鲜明的特点。
Opus 4.7 展现了 Anthropic 在长程任务(Long Horizon Task)规划上的显著进步。实测数据显示,该模型在处理复杂任务时,能够保持更长的思考链,且不再单纯依赖 token 的无节制消耗,而是通过高效的 token 配比将任务推至极致。其多模态理解能力也已追平主流水平,这为解锁设计类垂直场景奠定了基础。然而,这一版本也暴露出文字表达能力的退步,相比前代 Opus 4.6,其在抓重点和语言简洁性上略显不足。这很可能是一次战略性的权衡(Trade-off):Anthropic 正在通过 RL 迭代和 Tokenizer 更换,刻意引导用户在不同任务场景下分流使用不同模型——Coding 用 Opus,文字表达用 Sonnet,从而优化整体算力资源的分配效率。
OpenAI 的 GPT-5.5 则展现了另一种进化路径。不同于此前版本仅依靠后训练(Post-training)压榨 Codex 能力,GPT-5.5 在预训练(Pre-training)层面实现了实质性突破,验证了 OpenAI 构建复杂智能体(Agentic)任务的能力。其最直观的体感是推理速度的显著提升。对于 Coding Agent 而言,速度即能力,快速的试错、运行与修正闭环能极大放大实际开发效率。尽管在美国工作时间后速度会略有波动,但其作为狙击 Opus 系列的核心产品,意图十分明显。不过,目前业界共识仍认为,在 Brainstorm 和 Planning 的深度上,Opus 4.7 保持着核心优势,特别是在探索性任务中,其对用户意图的理解更为透彻。
DeepSeek V4 的登场则带来了性价比的极致革命。作为开源模型中的 SOTA,其在 Agentic 和 Coding 领域的能力已与闭源头部模型差距缩小至六个月以内。DeepSeek 通过极致的 FLOPs 优化和 KV Cache 压缩,实现了性能与成本的平衡。更为关键的是,它成功跑通了华为 950 集群,这不仅是一次国产替代的实践,更意味着其架构对国产算力的适配能力,为后续其他厂商降低了迁移门槛。DeepSeek 的历史意义不仅在于模型本身,更在于它推动了中国大模型行业从单纯模仿转向独立探索新架构,带动了整个产业链的升级。
模型吞噬脚手架:开发范式的根本性迁移
随着模型能力的爆发式增长,一个显著的趋势正在形成:模型正在“吞噬”原本需要外部脚手架(Harness)支持的复杂能力。过去,开发者需要搭建一系列外部工具来辅助模型完成长程任务,如文件管理、代码调试、环境配置等。而现在,新一代模型已经将部分脚手架功能内化,能够自主组织完整的开发流程。
在 GPT-5.4 发布后,开发者观察到一种全新的行为模式。当面对一个 iOS App 开发需求时,模型不再仅仅输出代码片段,而是主动识别运行环境(如手机与电脑的网络连接),直接部署应用并挂载调试进程。它在后台观察用户日志、定位 Bug、修改代码并重新部署,形成闭环。这意味着,模型本身正在从“辅助工具”进化为“全能软件工程师”。
然而,这种能力的迁移也带来了新的挑战。对于未搭建脚手架的开发者,Opus 4.7 等新版模型带来了能力的飞跃;但对于那些精心定制了旧版模型脚手架的用户,效果反而可能下降。具体表现为 Token 消耗激增、频繁触发上下文压缩、甚至无视预设指令。这是因为新版模型在 RL 训练中采用了团队协同(Team Coordination)的模式,要求主 Agent 以协调员身份指挥子 Agent 协作,而非单兵作战。
这一趋势对 Harness 领域的创业公司发出了预警信号:如果你的系统是基于上一代模型的能力缺陷设计的,那么随着模型能力的内化,这些系统瞬间就会变成技术债务。除非 Harness 能进化为随模型自动生成、编译和适配的动态系统,否则每次模型升级都将带来巨大的重构成本。同样,Skills 领域的商业模式也面临重构,能力型 Skills 的保鲜期极短,而偏好型 Skills 则受限于分发效率,未来的核心在于如何构建能够伴随模型共同进化的动态生态。

算力瓶颈与商业逻辑的重塑
随着模型迭代速度的加快,数据已不再是唯一的卡点,算力成为了制约行业发展的核心瓶颈。头部模型公司进入“AI 加速 AI"的自循环后,模型迭代越快,对算力的需求呈非线性增长,而供给端往往只能线性扩张,导致供需缺口日益扩大。
最新发布的 Myths 超大参数模型,其 Serving 需求已指向 NVIDIA GB200/GB300 NVL72 或 Google TPU7x/Ironwood 级别的硬件集群。对于国产模型而言,缩小与海外顶尖水平的差距,不仅需要构建十万卡级的高性能集群,更需突破 GPU 互联技术和自主软件栈的壁垒。虽然短期内国产芯片在产能和生态上仍面临压力,但随着 AI 辅助设计能力的提升,手搓 Kernel 和架构迁移的难度正在大幅下降,中国芯片设计的追赶速度可能被低估。
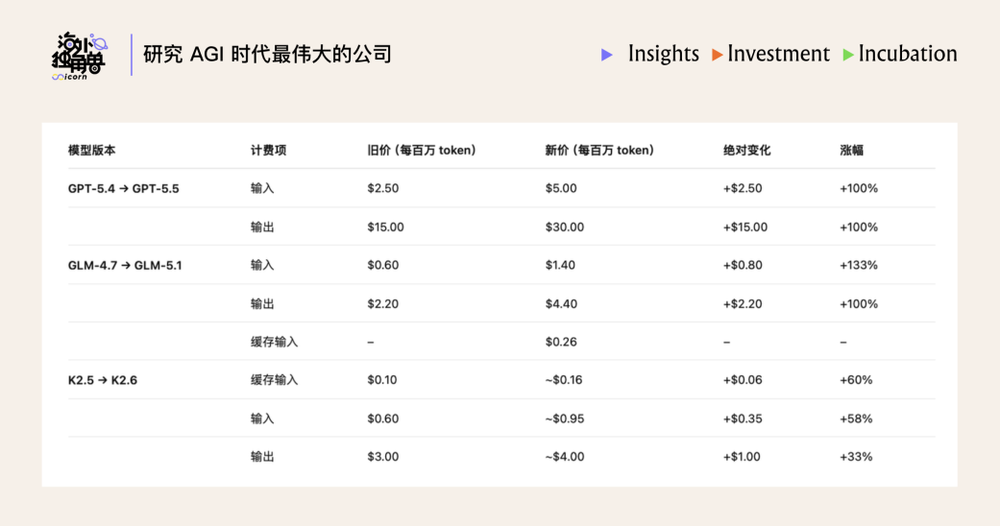
在商业层面,Token 涨价已成为确定性趋势。中美市场同步进入“性能定价”模式,OpenAI、智谱、Kimi 等厂商的头部模型价格在过去几个月内大幅上涨。这背后的逻辑是供需关系的根本性变化:需求呈指数级增长,而供给受限于硬件稀缺、运维成本上升以及模型变大带来的计算量激增。
更深层次的商业逻辑正在发生逆转。与互联网时代不同,AI 时代的单客价值几乎没有上限。Power Law 分布特征明显,头部 10% 的用户贡献了绝大部分营收。随着 Agentic 和 Coding 场景解锁真实 ROI,用户将愿意为能带来巨大效率提升的模型支付更高对价。然而,高利润率能否维持仍是未知数,Google DeepMind 曾言“我们没有防御护城河,OpenAI 也没有”,这一观点在技术快速迭代的今天依然成立。未来的竞争将不仅是模型能力的竞争,更是生态构建、数据飞轮与商业可持续性的综合较量。
人的价值重构:从执行者到决策者
当模型能力跨越拐点,竞争的主战场已从模型智能本身转移到了上下文管理和外部能力的对接上。对于企业而言,这是整个经营体系在数字世界的映射;对于个人而言,则是个人知识体系的深度整合。
在具体的应用场景中,如 AI 辅助投研,模型的作用更多是提供“宽搜索”能力。一位资深投研人员构建了多轮筛选的 Agent 工作流,利用结构化数据筛选财务健康度,利用非结构化数据抓取行业关键人物动态,结合“聪明钱”持仓进行验证。这一过程在 2-3 天内完成了对万余家标的的初筛,最终锁定个位数优质标的。在这个过程中,模型是发动机,而数据的质量和 Workflow 的设计才是护城河。真正决定最终效果的,依然是人类的深度思考、直觉判断和对异常信号的敏锐感知。
中国企业在数字化基础和组织权限上的短板,成为了用好 AI 的最大瓶颈。即便在大厂内部,代码权限的割裂也阻碍了系统级的逻辑对接。最高效的 AI 协作方式往往是让 AI 通读两边代码,但在现实组织中,这往往难以实现。因此,谁能率先打破组织壁垒,将上下文和权限打通,谁的“组织转速”就会更快,谁就能在 AI 时代获得真正的竞争优势。
未来,AI 时代的商业逻辑将不再是简单的工具替代,而是人机协作模式的深度重构。模型负责处理海量数据和复杂计算,人类负责定义问题、整合资源和做出最终决策。这种杠杆效应的放大,将重新定义各行各业的价值创造方式。在这个月更的时代,唯有拥抱变化,不断调整自身定位,才能在智能浪潮中找到属于自己的锚点。