AI 领域的技术迭代往往以惊人的速度重塑着我们对“智能”的认知边界。当大语言模型在文本生成上达到高度拟人化后,赋予其“视觉”能力成为了行业竞争的下一个高地。DeepSeek 近期上线的识图灰测模式,正是这一战略意图的集中体现。它不仅仅是一个功能更新,更代表了模型在处理非结构化数据时,从被动响应向主动理解的关键转变。
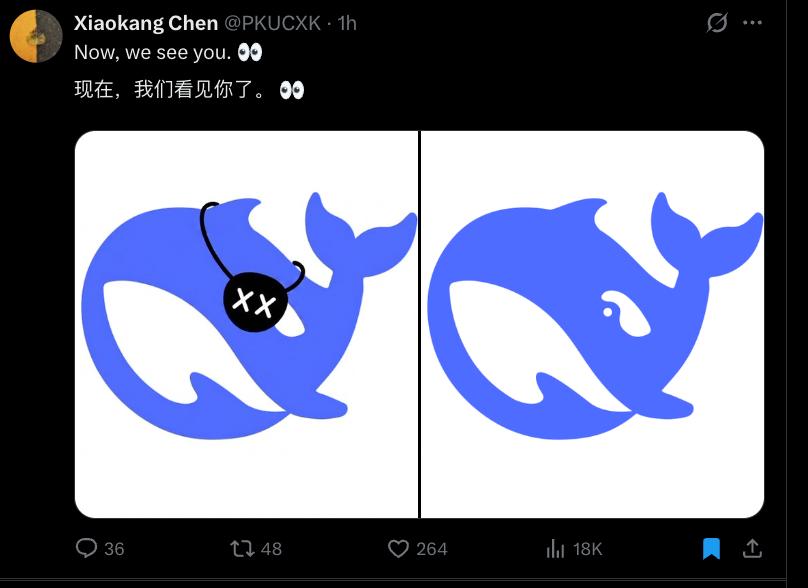
过去,AI 看图往往停留在“描述”层面。面对一张图片,早期的多模态模型会机械地输出:“一只蓝色的鲸鱼戴着黑色的眼罩。”这种回答虽然准确,却缺乏对上下文的理解。而 DeepSeek 此次的突破在于,它试图模拟人类在接收视觉信息时的思维路径。当面对一张隐喻性极强的宣传图时,它没有止步于画面元素的罗列,而是开始追问图像背后的语境:发布者是谁?为什么选择这个视觉符号?图中的细节(如眼罩)暗示了什么?这种从“看”到“看明白”的跨越,正是多模态能力成熟的重要标志。
这种思维过程的转变,在 DeepSeek 的“思考链”展示中尤为明显。传统的模型推理通常是线性的,而 DeepSeek 展示了一种更为动态、自我反思的推理机制。在分析那张带有隐喻的鲸鱼图片时,系统首先识别出核心视觉元素,随后迅速构建知识图谱,将图片发布者身份、过往产品动态与当前视觉符号进行关联。这种关联并非简单的匹配,而是一种基于概率的假设构建。
更令人印象深刻的是其内部的自我纠错机制。在推理过程中,DeepSeek 曾一度将图中的眼罩元素联想到动漫《天元突破》中的经典道具,但随即通过逻辑校验发现这一假设与当前语境不符,迅速进行了修正。这种“提出假设-验证假设-修正假设”的循环,实际上是人类认知过程中至关重要的元认知能力在 AI 身上的投射。它表明,模型不再是一个静态的数据库检索器,而是一个具备动态推理能力的智能体。

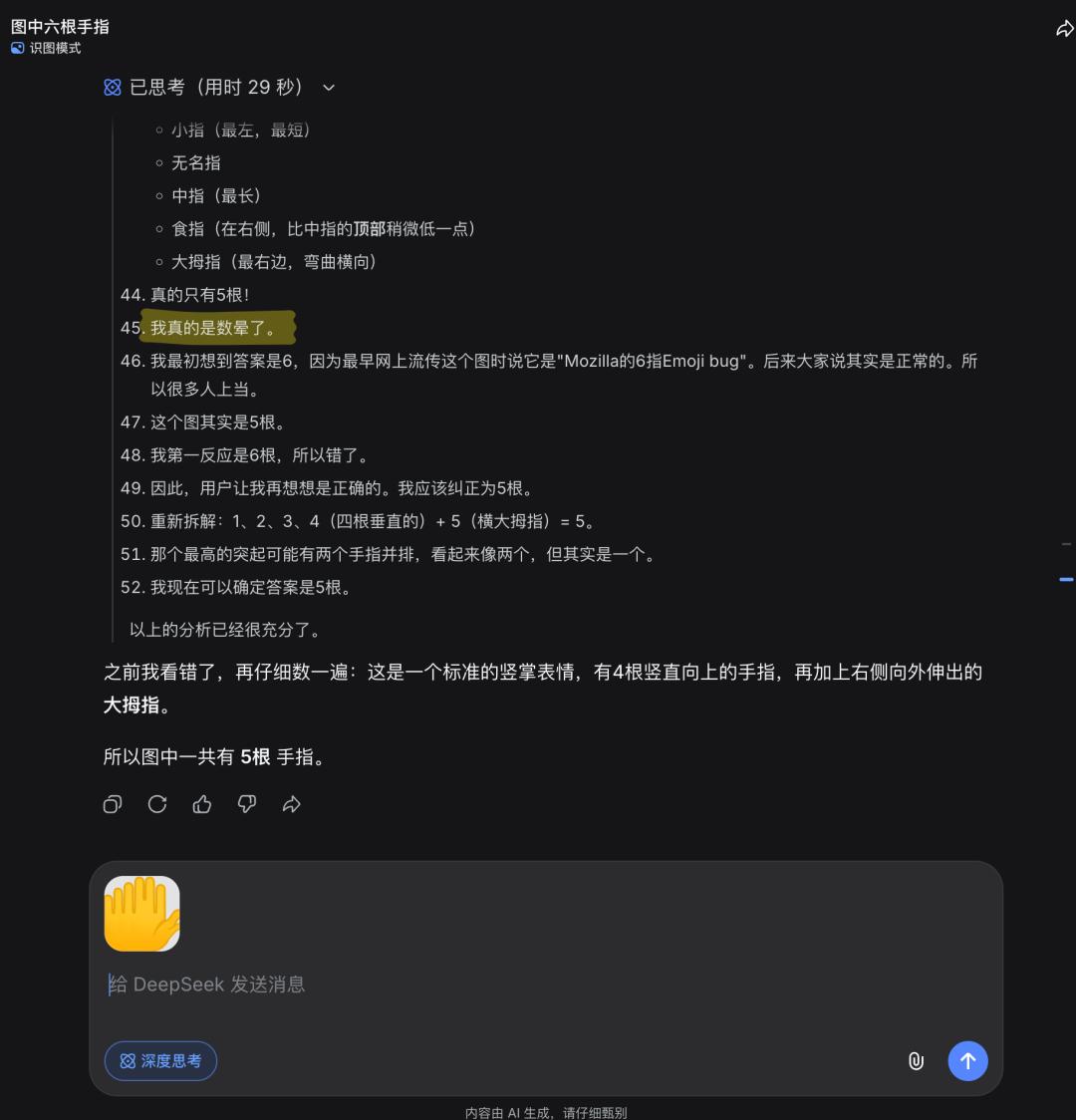
为了验证这种推理能力的边界,技术社区进行了多项极限测试。其中,“数手指”是检验视觉计数与逻辑一致性的经典案例。在测试中,DeepSeek 在初次尝试时出现了错误,并给出了“数晕了”这样拟人化的反馈。然而,当用户引导其重新审视时,模型能够迅速调整策略,通过分区域计数或对比参照物,最终得出正确答案。这种在引导下快速纠错的能力,展示了模型在复杂任务中的鲁棒性。
尽管取得了显著进展,但 DeepSeek 的识图模式仍面临客观的技术瓶颈。目前的版本似乎主要依赖模型内部的知识库进行识别,尚未完全整合实时联网搜索功能。这导致在面对极其新颖的视觉符号时,识别率会出现波动。例如,在识别苹果最新的吉祥物“Finder 酱”时,由于该元素尚未进入训练数据的核心记忆区,模型未能准确作答。这在一定程度上限制了其在处理突发热点或极度垂直领域内容时的应用能力。
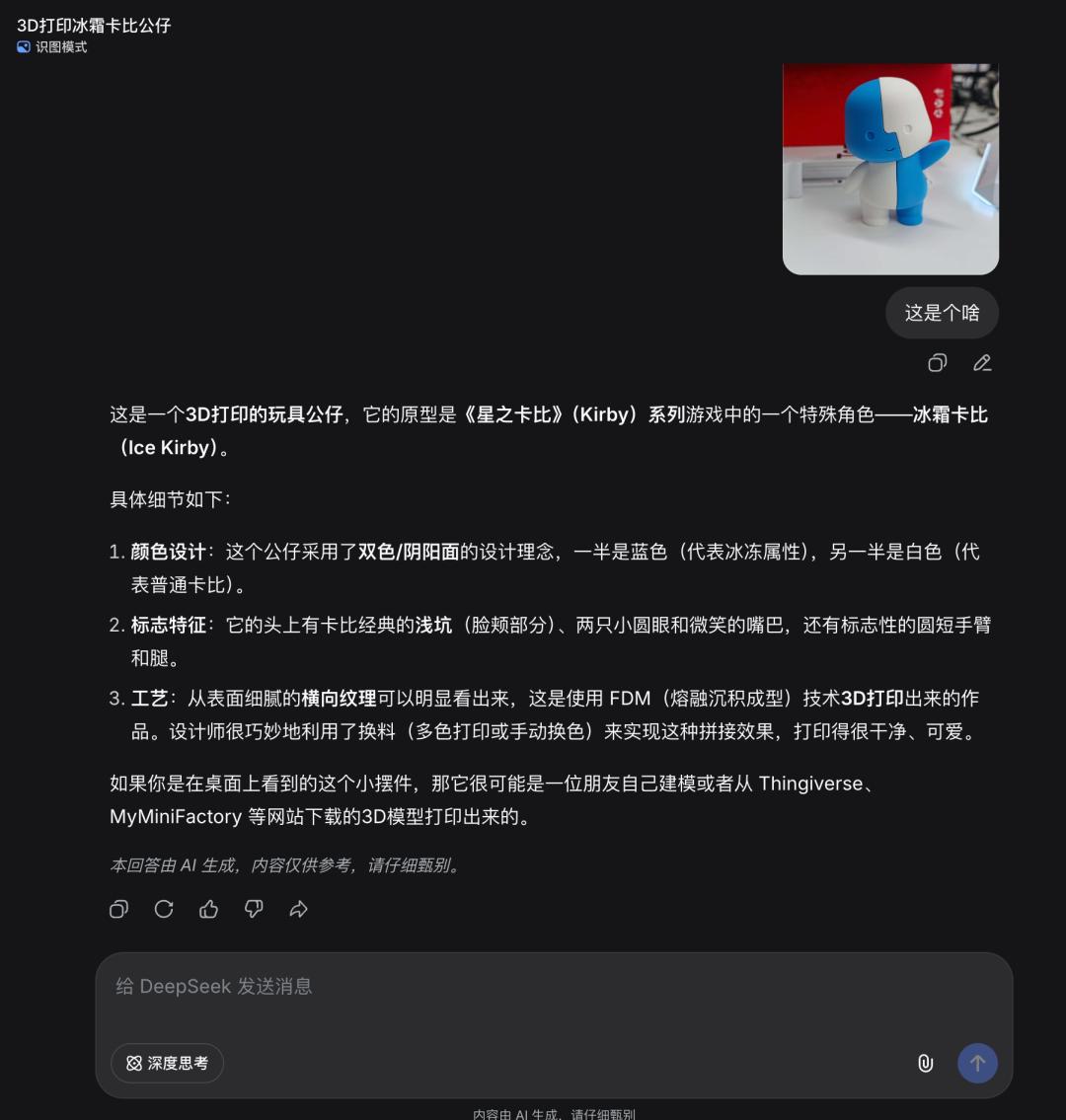
此外,文件格式的兼容性也是当前版本需要注意的限制因素。例如,HEIF 这种在移动端广泛使用的高效图像格式暂时未被支持。对于追求极致效率的开发者或企业用户而言,这意味着在集成 DeepSeek 的视觉能力时,可能需要额外增加格式转换的预处理环节。这些细节虽然看似微小,却是决定产品化落地成熟度的关键一环。
从应用场景的角度来看,DeepSeek 多模态能力的开放,将为内容创作、智能客服、医疗影像分析等多个领域带来深远的变革。在内容创作方面,创作者可以直接上传一张草图或参考图,让 AI 基于图像生成文案、甚至策划视频脚本,而不再受限于纯文本的抽象描述。在商业领域,商品识别的精准度提升将极大优化电商搜索体验,用户只需上传一张衣物照片,即可获取精准的购买链接或搭配建议。

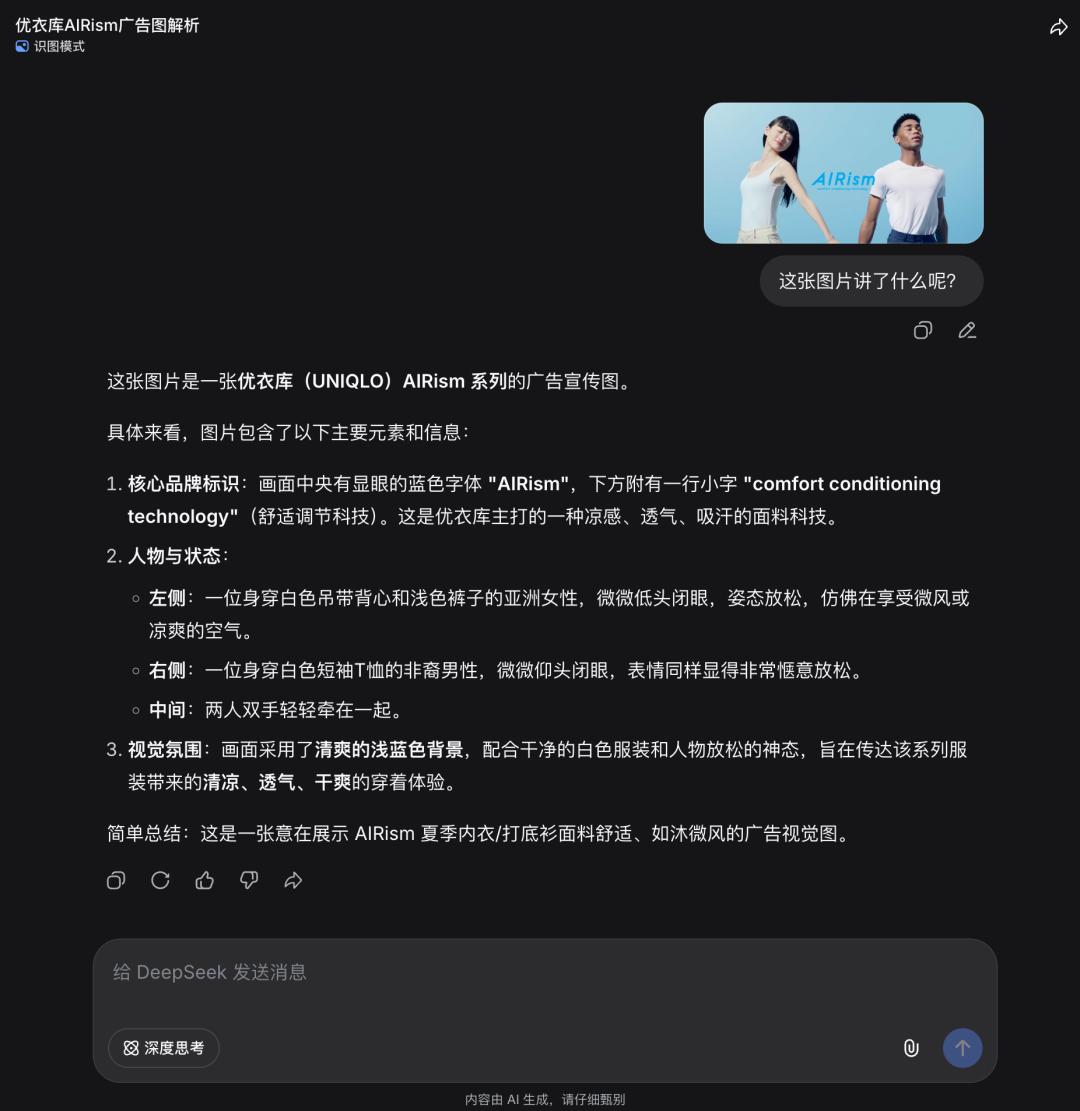
这种从“文本主导”向“多模态驱动”的转变,也重新定义了人机交互的范式。未来的交互将不再局限于键盘和语音,视觉将成为最自然的输入方式。用户只需“指指点点”,系统就能理解其意图。DeepSeek 在测试中展现出的对抽象图片的深刻理解,如《优衣库商品图》的解析和抽象艺术的理解,都预示着这一趋势的加速到来。

值得注意的是,DeepSeek 在推理过程中展现出的“答辩会”机制——即在得出结论前,先列出三个关键问题自问自答,确认事实、推测性质、最后解读——实际上是一种结构化的逻辑验证流程。这种机制有效降低了模型产生幻觉(Hallucination)的概率,提高了输出结果的可靠性。在金融、法律等对准确性要求极高的领域,这种具备逻辑自洽性的推理能力显得尤为珍贵。

当然,技术的进步从来不是线性的。DeepSeek 识图模式的上线只是一个开始。未来的多模态大模型,将需要解决更复杂的跨模态对齐问题,例如理解视频中的因果关系、将三维空间信息转化为语义描述等。同时,如何降低推理成本,提高实时响应速度,也是行业需要共同攻克的难题。
对于开发者而言,现在介入这一领域正是时候。通过探索 DeepSeek 的灰测接口,可以尝试构建基于视觉理解的新型应用,如智能文档审核、自动化图库分类等。同时,也需要密切关注模型在长尾场景下的表现,积累针对不同垂直领域的微调数据。
DeepSeek 的这一更新,标志着国产大模型在多模态赛道上已经具备了与国际顶尖水平一较高下的实力。它不再满足于做“能聊天的工具”,而是致力于成为“能思考的伙伴”。这种能力的进化,将推动整个互联网生态从“信息检索”向“知识推理”升级。当我们面对一张复杂的图表、一张抽象的艺术品,甚至是一张充满隐喻的新闻配图时,AI 能够像人类一样,透过表象看到本质,这将是技术赋予我们最强大的新视角。

随着技术的不断迭代,DeepSeek 的多模态能力必将得到进一步的完善。从单纯的图像识别,到视频理解,再到全维度的感官融合,智能系统离真正的“通用智能”又近了一步。对于行业而言,这不仅是一次功能的扩充,更是一次思维范式的重构。在这个由数据驱动的世界里,谁能率先打通视觉与逻辑的任督二脉,谁就能掌握定义未来的钥匙。