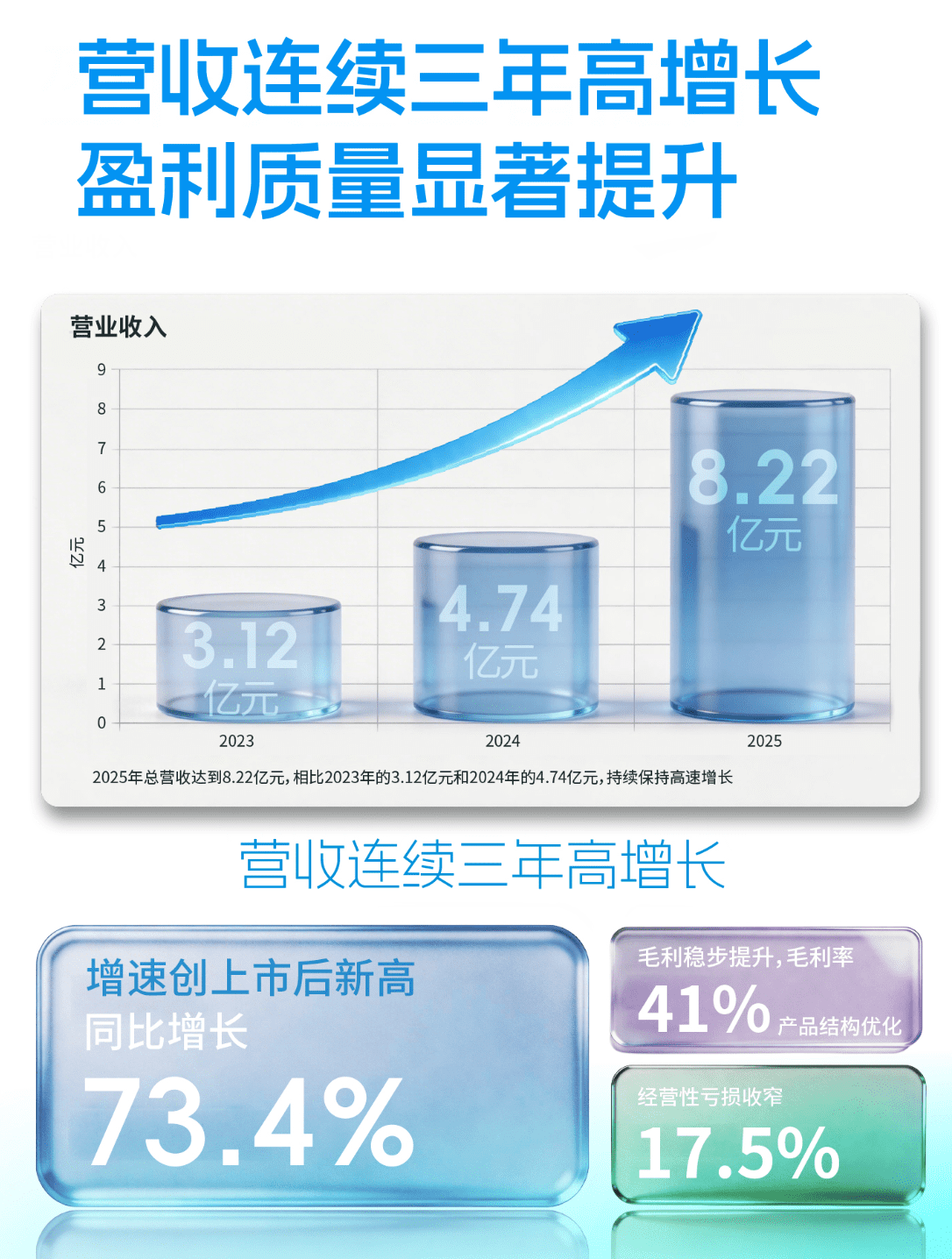
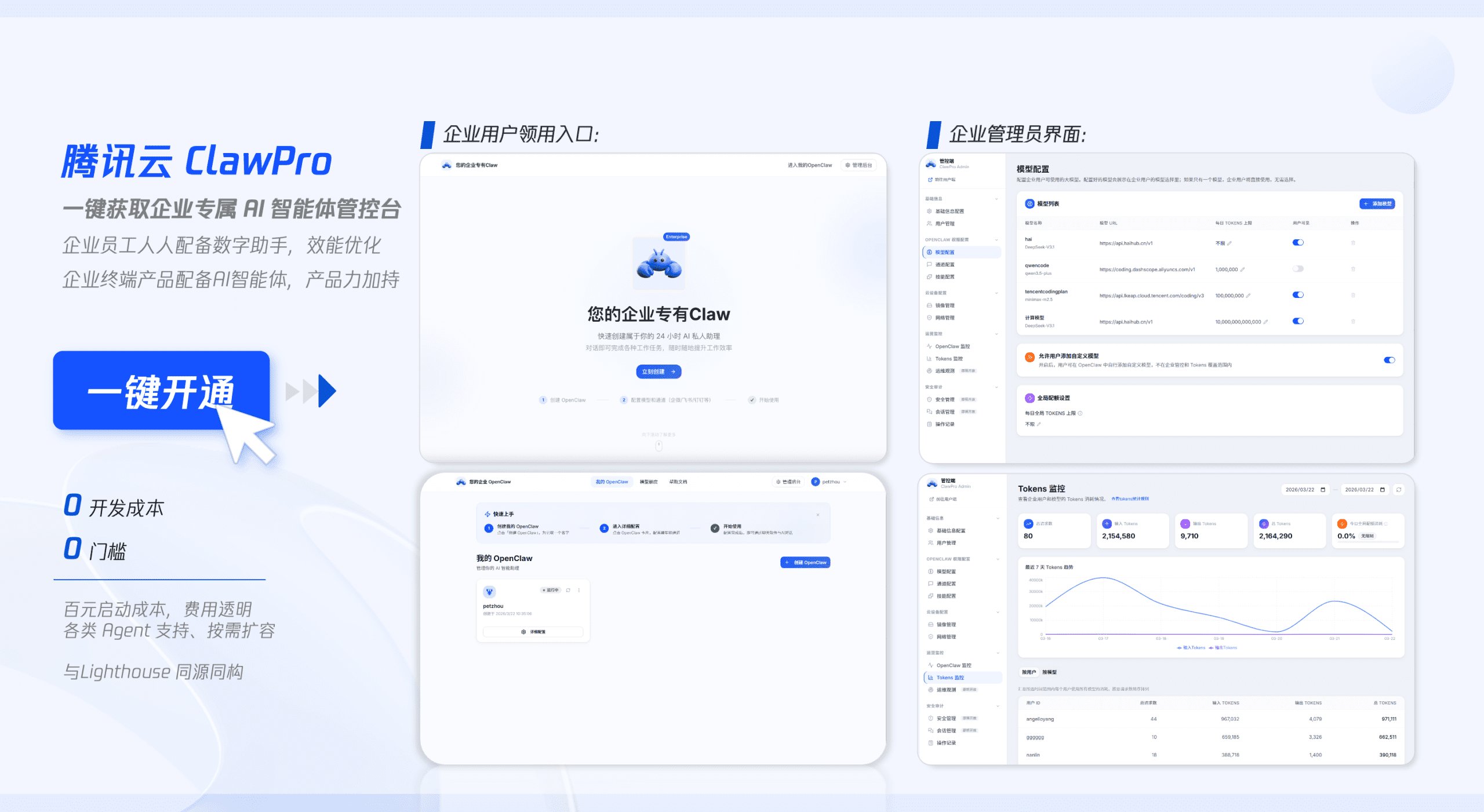
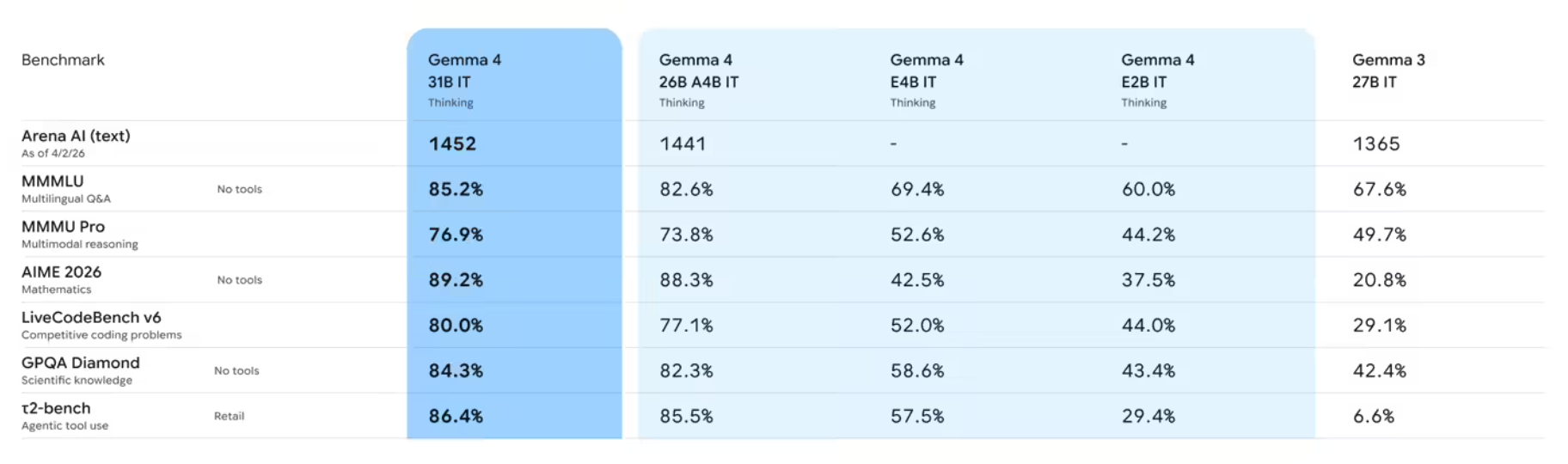
语音生成技术正在经历前所未有的变革,阿里通义实验室推出的Fun-AudioGen-VD模型代表了这一领域的最新进展。该模型不仅在技术架构上实现了重要突破,更在应用层面为声音创作带来了全新的可能性。
技术架构的创新设计
Fun-AudioGen-VD基于阿里通义语音大模型技术栈构建,采用深度学习的生成式架构,支持端到端的文本到音频生成。与传统语音合成系统相比,该模型最大的创新在于实现了多维度声学特征的解耦建模。这意味着音色、情绪、语速、音质等声学属性可以被独立控制并进行灵活组合,从而生成更加丰富多样的语音输出。
在场景化音频融合方面,模型采用了先进的多轨音频合成机制。这种机制将人声、环境音、空间混响、设备滤镜等元素进行分层处理后再进行融合输出,确保了最终音频的自然度和真实感。这种分层处理方式不仅提高了音频质量,还为后续的编辑和调整提供了更大的灵活性。
物理声学模拟的精确实现
模型在物理声学模拟方面表现出色,通过算法精确模拟真实空间的声波反射、混响衰减和介质传播等物理特性。例如,当需要模拟大教堂环境时,模型能够准确计算声波在大型空间内的传播规律,生成符合实际听觉体验的混响效果。同样,水下场景的模拟也考虑了水介质对声音传播的影响,实现了真实的水下听觉效果。
设备失真建模是另一个技术亮点。模型对老式广播、对讲机等设备的频响特性、压缩失真和噪声底噪进行了精细建模。这种建模不仅限于简单的频率响应调整,而是深入模拟了设备特有的声音特性,使得生成的音频具有真实的复古听感。
动态交互引擎的技术优势
Fun-AudioGen-VD的动态交互引擎支持实时环境参数变化,能够生成具有时序变化的自然音频。这一特性使得模型能够模拟风噪强度变化、回声延迟调整等动态效果,大大增强了音频的真实感和沉浸感。与传统静态音频生成系统相比,这种动态交互能力为音频创作带来了更多可能性。
自然语言理解模块的加入进一步提升了模型的易用性。该模块能够将抽象的情感描述(如"表面镇定但内心颤抖")映射为具体的声学参数组合,使得用户无需具备专业的音频知识就能生成高质量的语音内容。
应用场景的广泛拓展
在影视动画配音领域,Fun-AudioGen-VD能够快速生成符合角色设定的配音素材。模型支持复杂情绪与场景氛围的同步生成,显著降低了专业配音的制作成本和时间。特别是在需要大量配音内容的动画制作中,该技术能够大幅提升制作效率。
游戏开发是另一个重要应用领域。模型可以为游戏中的NPC和主角生成个性化语音,支持不同情绪状态与场景的实时切换。这种能力对于提升游戏的沉浸感和玩家体验具有重要意义。
有声书制作方面,模型能够根据小说情节自动匹配角色音色与场景环境音。这种智能匹配不仅提高了制作效率,还能为听众创造更加丰富的听觉体验。
技术实现的挑战与突破
实现如此复杂的语音生成系统面临诸多技术挑战。首先是计算资源的优化问题,模型需要在保证音频质量的同时控制计算成本。阿里团队通过流式生成优化技术,针对实时应用场景进行了推理效率的专门优化,支持低延迟的API调用响应。
另一个挑战是训练数据的质量要求。高质量的语音生成模型需要大量标注准确的多维度语音数据。阿里团队通过创新的数据增强技术和半监督学习方法,有效解决了训练数据不足的问题。
模型的可控性也是技术实现的重点。Fun-AudioGen-VD通过精细的参数控制接口,使得用户能够对生成结果进行多层次的调整。这种可控性不仅体现在基础的声音属性上,还包括情绪表达强度和场景效果的细微调节。
行业影响与发展前景
Fun-AudioGen-VD的推出将对语音技术行业产生深远影响。首先,它降低了专业音频制作的技术门槛,使得更多创作者能够参与高质量音频内容的制作。其次,该技术为个性化语音服务提供了新的可能性,特别是在智能助手和虚拟角色领域。
从技术发展角度看,Fun-AudioGen-VD代表了语音生成技术向更智能、更自然方向发展的趋势。未来,随着模型能力的进一步提升,我们有望看到更加智能化和个性化的语音生成解决方案。
在商业化应用方面,该技术具有广阔的市场前景。除了传统的娱乐和媒体行业,在教育、医疗、客服等领域的应用也值得期待。特别是在需要大量个性化语音内容的场景中,Fun-AudioGen-VD的技术优势将更加明显。
技术局限性与改进方向
尽管Fun-AudioGen-VD在技术上取得了显著进展,但仍存在一些局限性。例如,在极端情感表达和特殊语音效果的生成方面,模型的表现还有提升空间。此外,对于某些特定方言和口音的模拟精度也需要进一步优化。
未来的改进方向包括提升模型的多语言支持能力,增强对复杂语音交互场景的适应性,以及进一步提高生成音频的自然度和真实感。同时,模型的可解释性和可控性也是重要的研究方向。
从用户体验角度,简化操作界面和降低使用门槛将是未来的重点。虽然当前的FreeStyle指令输入已经大大简化了操作流程,但如何让非专业用户更容易地获得理想的结果仍然需要持续优化。
行业标准与规范考量
随着语音生成技术的快速发展,相关的行业标准和规范也需要同步建立。特别是在音频版权、声音身份保护等方面,需要建立完善的技术规范和法律法规。Fun-AudioGen-VD作为领先的技术方案,有责任推动相关标准的制定和完善。
在技术伦理方面,如何防止技术滥用、保护个人声音权益等问题也需要认真考虑。阿里团队在模型设计中已经考虑了这些因素,但行业整体的规范建设仍需共同努力。
技术生态建设
Fun-AudioGen-VD的成功不仅依赖于技术本身,还需要健全的技术生态支持。这包括开发者社区的建设、第三方工具的集成、以及相关培训资源的提供。阿里通过开放API接口和详细的开发文档,为生态建设奠定了良好基础。
未来,随着更多开发者和企业的参与,Fun-AudioGen-VD的技术生态将更加丰富。这将进一步推动技术创新和应用拓展,形成良性的发展循环。
语音生成技术正处于快速发展的阶段,Fun-AudioGen-VD的出现标志着这一领域进入了新的发展阶段。随着技术的不断成熟和应用场景的持续拓展,我们有理由相信,智能语音生成技术将为各行各业带来更多创新可能性。