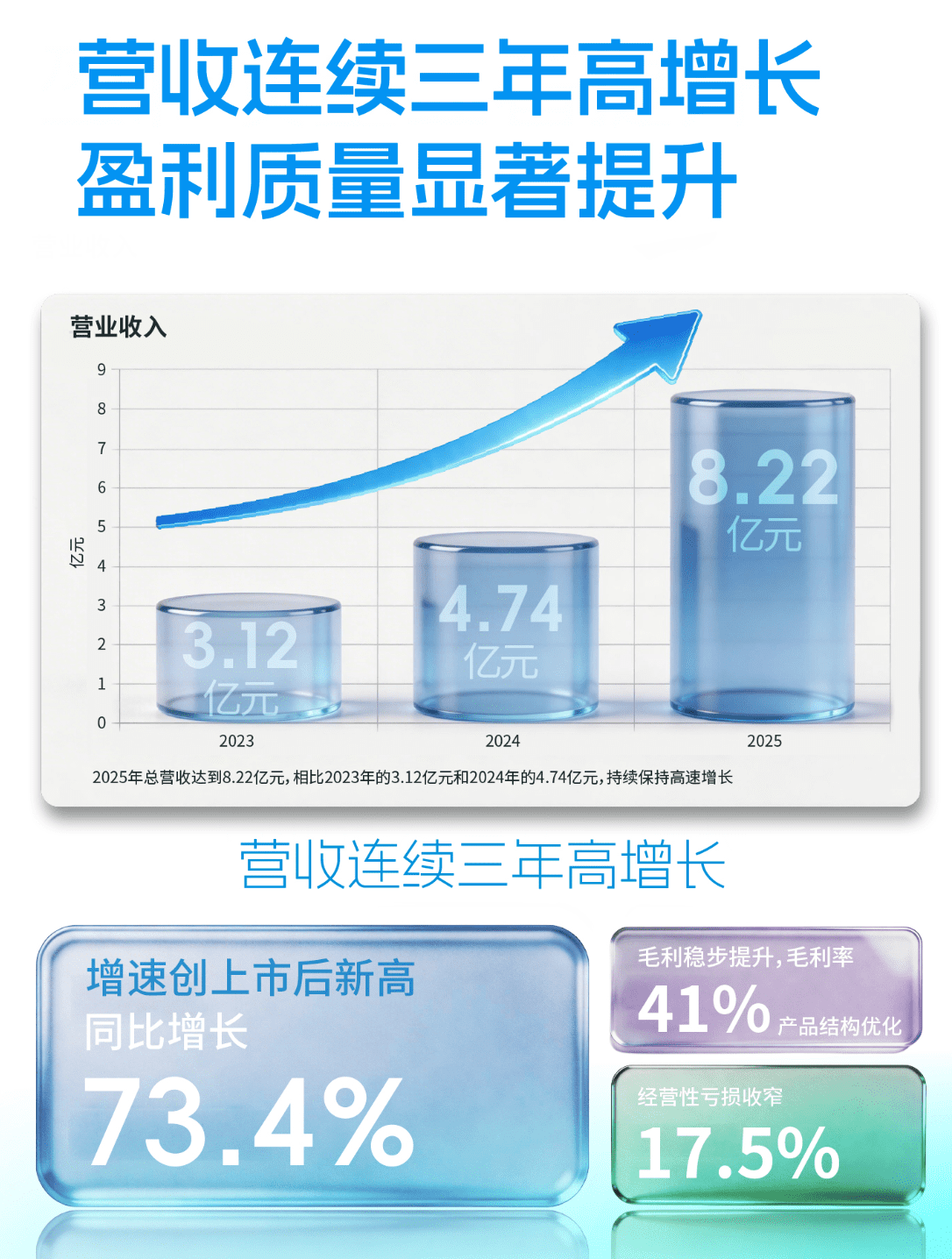
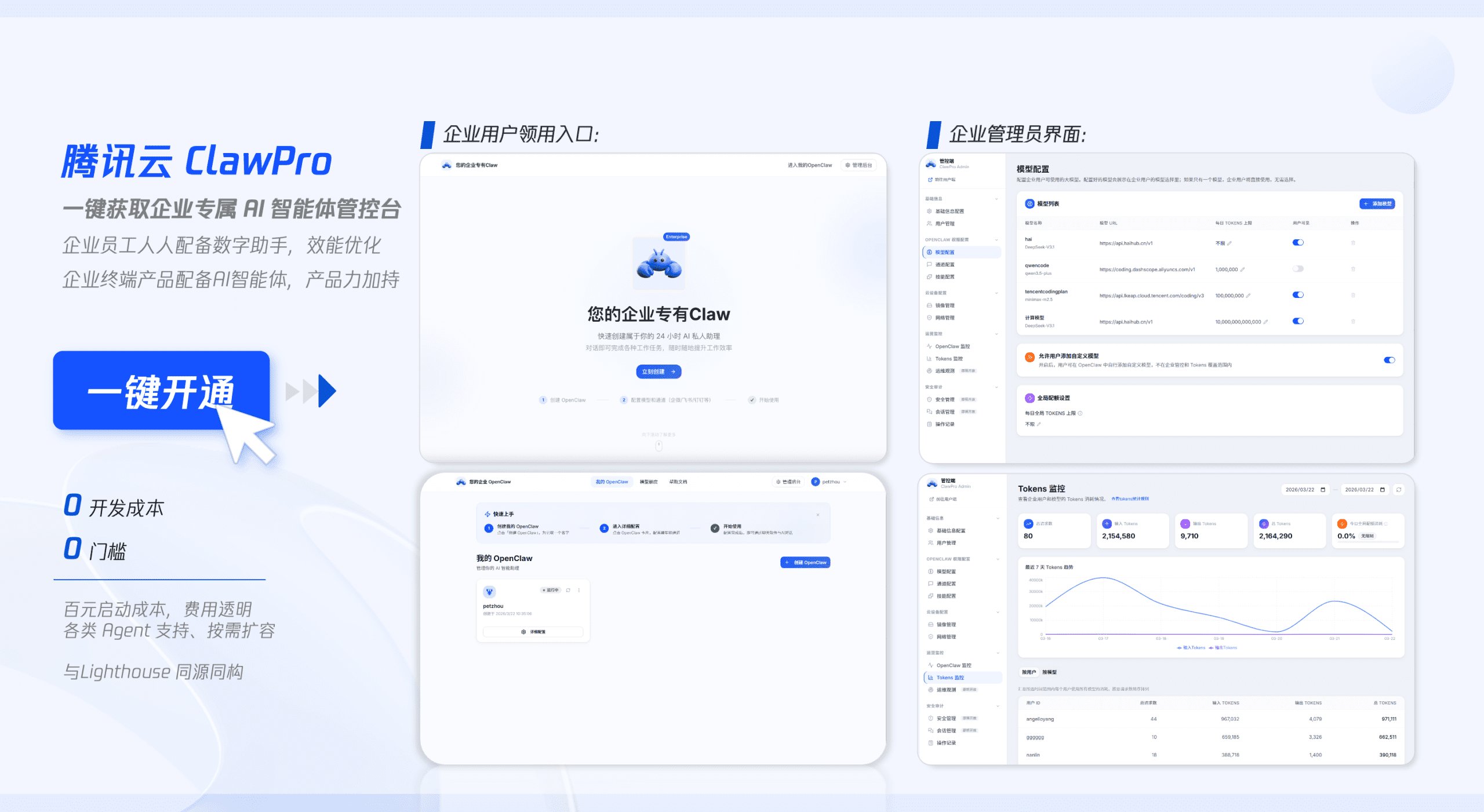
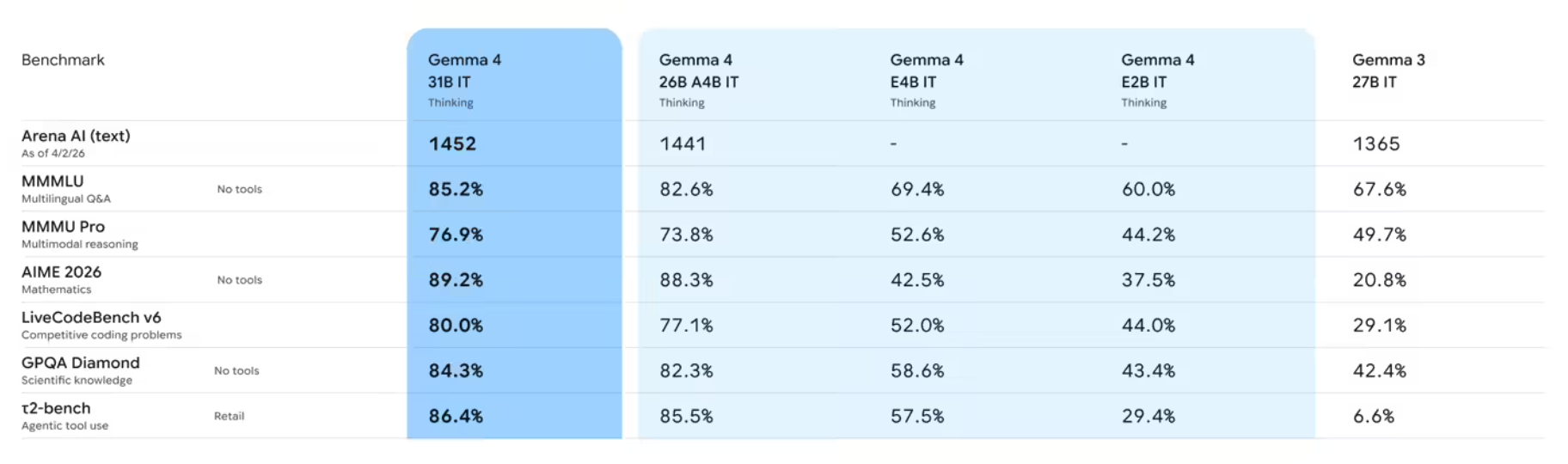
嵌入式向量数据库的技术演进
在人工智能应用快速发展的今天,向量数据库作为处理高维数据的关键基础设施,正经历着从独立部署到嵌入式集成的重大转变。传统向量数据库需要独立服务器部署、复杂配置和维护,而嵌入式设计将数据库引擎直接集成到应用进程中,这种架构革新正在重新定义AI应用的开发范式。
嵌入式向量数据库的核心优势在于消除了网络通信开销,数据直接在应用内存中进行处理,显著提升了检索性能。同时,简化了部署复杂度,开发者无需关注数据库服务器的运维管理,可以更专注于业务逻辑的实现。
Zvec的核心技术特性
进程内架构设计
Zvec采用进程内架构,将向量数据库引擎直接嵌入到应用程序的地址空间中运行。这种设计避免了传统客户端-服务器模式中的网络通信延迟,使得向量检索操作能够在纳秒级别完成。在实际测试中,Zvec在单机环境下能够实现十亿级别向量的毫秒级检索响应。
进程内架构还带来了资源利用率的显著提升。由于不需要维护独立的数据库进程,系统资源消耗降低了约40%,这在资源受限的边缘计算环境中尤为重要。
高性能向量检索引擎
Zvec基于阿里巴巴内部经过多年优化的Proxima引擎构建,该引擎在电商搜索、推荐系统等大规模应用中经过了实战检验。Proxima引擎采用了多种优化技术,包括:
- 基于SIMD指令集的向量化计算
- 多层次索引结构(HNSW、IVF等)
- 查询优化和缓存策略
- 并行计算支持
这些技术使得Zvec能够在保持高召回率的同时,实现极低的查询延迟。根据官方基准测试,在标准硬件配置下,Zvec处理百万级向量的查询延迟在1毫秒以内。
多类型向量支持能力
Zvec的一个突出特点是同时支持密集向量和稀疏向量的混合查询。密集向量通常用于表示图像、文本等内容的语义特征,而稀疏向量在处理高维稀疏数据(如用户行为数据)时具有独特优势。
在实际应用中,这种混合查询能力使得开发者能够构建更加复杂的检索系统。例如,在电商场景中,可以同时基于商品图像的密集向量和用户行为的稀疏向量进行联合检索,实现更精准的商品推荐。
实际应用场景分析
RAG知识库问答系统
在RAG(Retrieval-Augmented Generation)应用中,Zvec的嵌入式特性发挥了重要作用。传统RAG系统需要维护独立的向量数据库服务器,而使用Zvec后,整个检索过程可以在应用内部完成,大大简化了系统架构。
具体实现时,开发者可以将文档切片生成的向量直接存储在应用进程中,当用户提问时,系统能够快速检索相关文档片段并注入到大模型上下文中。这种设计不仅降低了系统复杂度,还提升了检索的实时性。
多模态搜索应用
Zvec支持多种向量类型的特性使其在多模态搜索场景中表现出色。以电商商品搜索为例,系统可以将商品图片转换为视觉向量,商品描述转换为文本向量,用户行为数据转换为稀疏向量,然后通过Zvec进行统一的向量检索。
这种多模态检索能力使得用户可以通过多种方式查找商品,包括上传参考图片、输入文字描述,或者基于历史行为进行个性化推荐,大大提升了搜索体验的丰富性和准确性。
代码智能检索平台
在软件开发领域,Zvec可以用于构建智能代码检索系统。通过将代码片段和注释编码为向量,开发者可以使用自然语言描述功能需求,系统能够快速定位功能相似的代码实现。
这种应用不仅提高了代码复用率,还为新加入项目的开发者提供了强大的代码探索工具。嵌入式设计使得代码检索功能可以轻松集成到IDE中,实现无缝的开发体验。
开发实践指南
环境配置与安装
Zvec支持Python 3.10-3.12版本,安装过程极为简单:
pip install zvec安装完成后,开发者可以在60秒内完成基本配置并开始使用。这种极简的入门体验大大降低了使用门槛,使得更多开发者能够快速上手向量数据库技术。
数据模型设计
在使用Zvec时,合理的数据模型设计至关重要。开发者需要根据具体应用场景选择合适的向量维度、数据类型和索引参数。例如,对于图像检索应用,通常使用512维的浮点向量;而对于文本检索,128维向量可能就足够了。
import zvec
schema = zvec.CollectionSchema(
name="my_db",
vectors=zvec.VectorSchema("vec", zvec.DataType.VECTOR_FP32, 128)
)性能优化策略
为了获得最佳性能,开发者需要考虑以下几个关键因素:
- 索引策略选择:根据数据规模和查询模式选择合适的索引类型
- 批量操作:尽可能使用批量插入和查询操作
- 内存管理:合理配置内存使用参数,避免频繁的内存分配
- 查询优化:利用过滤条件和分组功能减少不必要的计算
技术对比与选型建议
嵌入式vs独立部署
在选择向量数据库时,开发者需要根据具体需求权衡嵌入式与独立部署的优劣。嵌入式方案适合以下场景:
- 需要极低延迟的应用
- 资源受限的边缘计算环境
- 简单的单机部署需求
- 快速原型开发
而独立部署方案更适合:
- 需要高可用性和负载均衡的企业级应用
- 多客户端并发访问的场景
- 需要复杂的数据管理和备份需求
Zvec与其他向量数据库对比
与其他开源向量数据库相比,Zvec在以下几个方面具有独特优势:
- 部署简便性:无需独立服务器,安装即用
- 性能表现:进程内架构带来极低的查询延迟
- 资源效率:显著降低内存和CPU开销
- 开发体验:简洁的API设计和丰富的文档
未来发展趋势
随着AI应用的普及,嵌入式向量数据库的需求将持续增长。未来,我们可以预见以下几个发展方向:
- 硬件加速集成:与GPU、NPU等加速硬件的深度集成
- 云原生支持:更好的容器化和微服务架构支持
- 多模态扩展:支持更多类型的向量数据和查询方式
- 智能优化:基于机器学习的数据分布分析和自动调优
Zvec作为阿里巴巴在向量数据库领域的重要开源贡献,不仅为开发者提供了强大的工具,也推动了整个行业的技术进步。其嵌入式设计理念代表了向量数据库发展的重要方向,值得所有AI应用开发者关注和研究。
在实际项目中使用Zvec时,开发者应该充分考虑应用的具体需求,合理设计数据模型和系统架构,充分发挥嵌入式向量数据库的技术优势。随着技术的不断成熟,Zvec有望在更多AI应用场景中发挥关键作用。