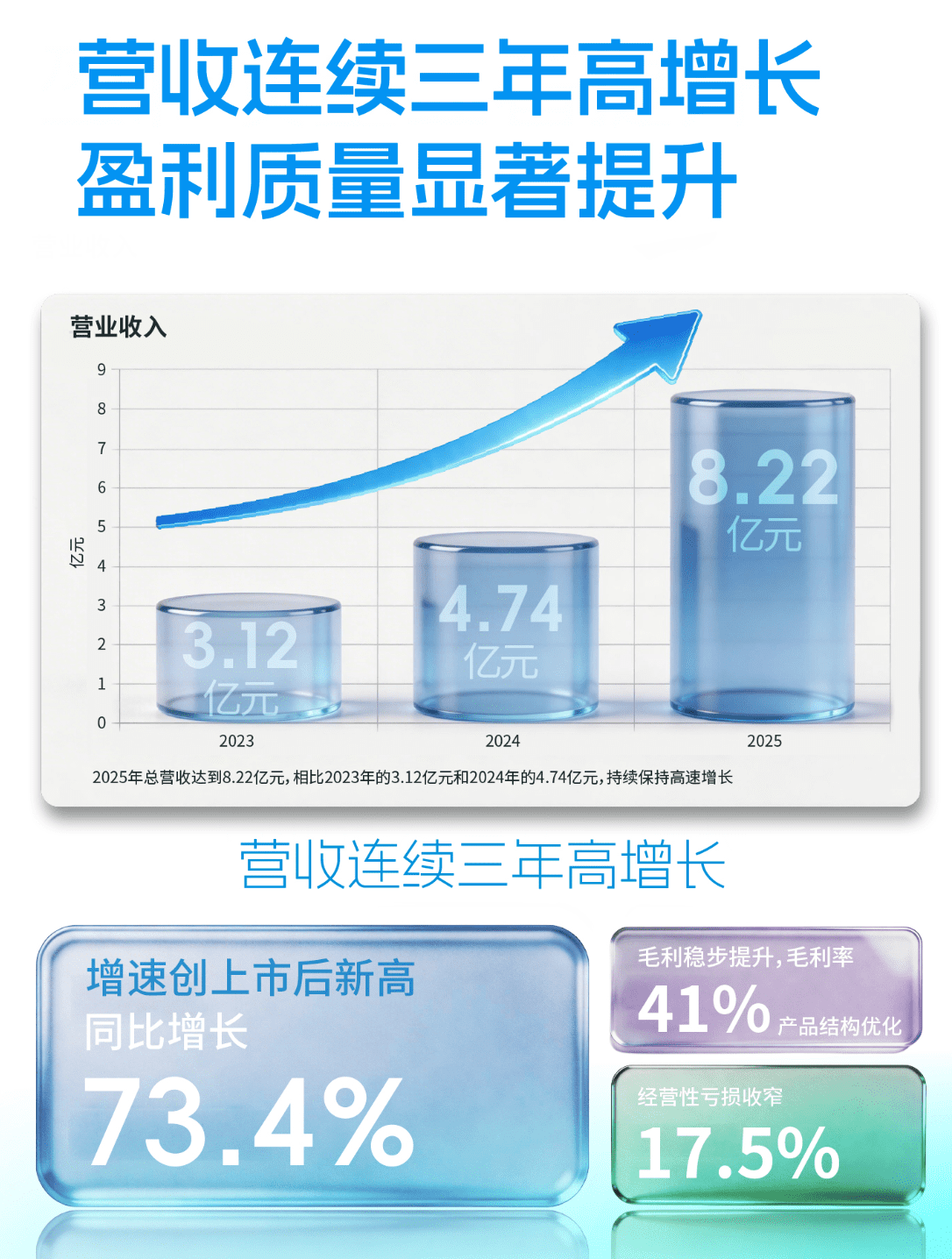
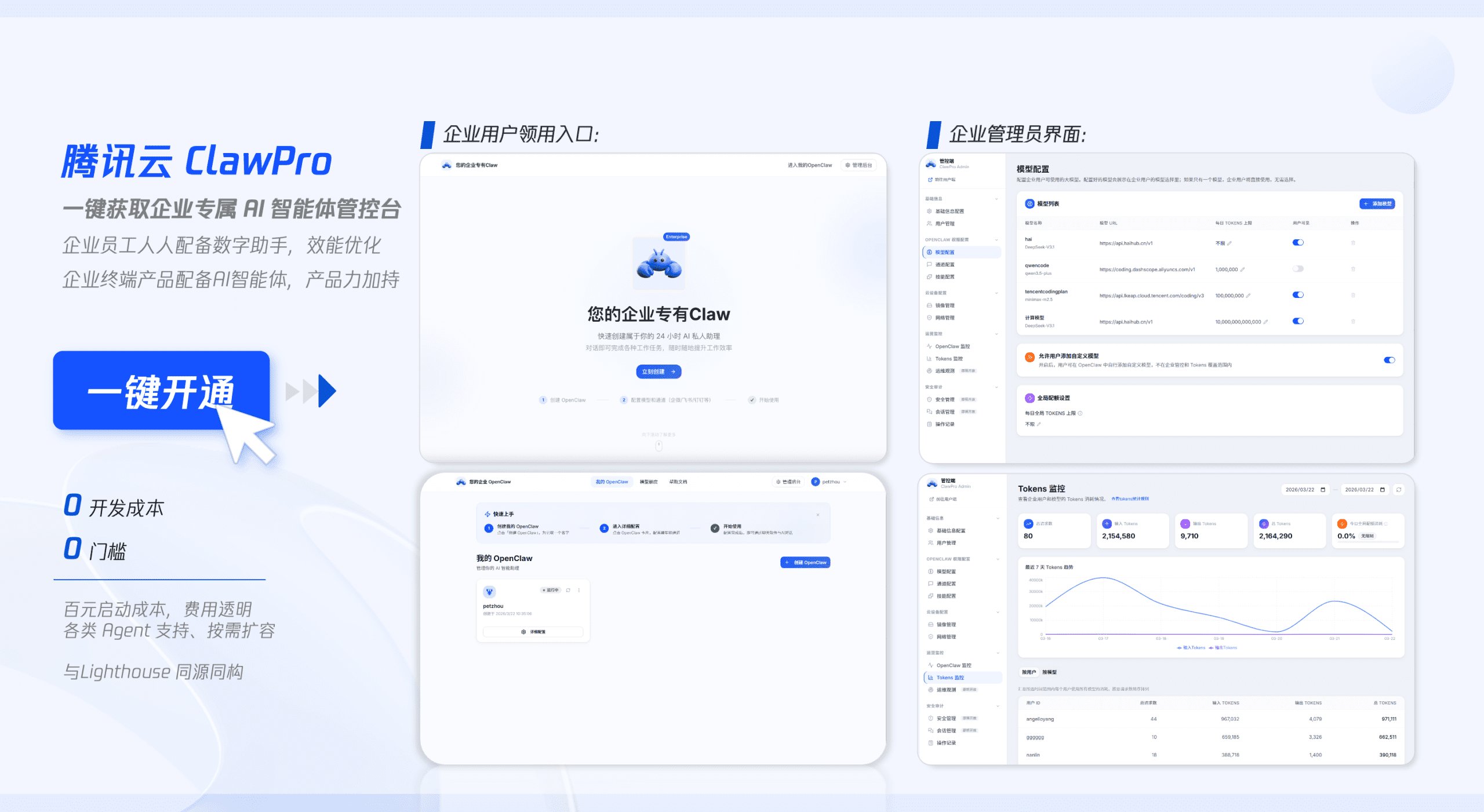
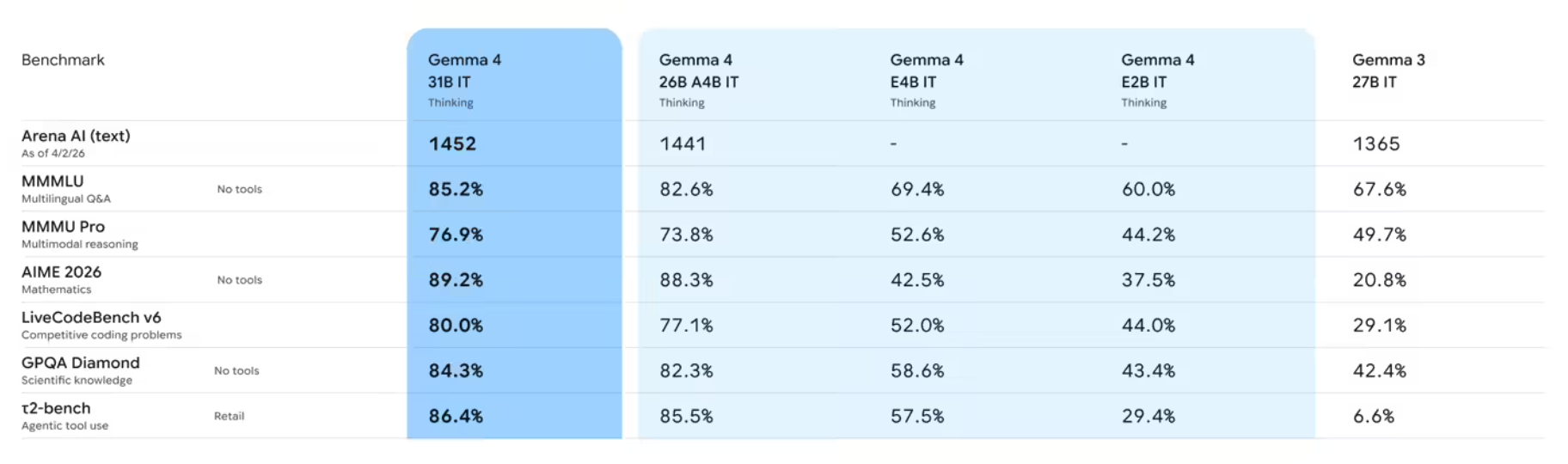
技术架构解析
UnifoLM-VLA-0模型采用创新的三阶段架构设计,在Qwen2.5-VL-7B视觉语言模型基础上进行深度改造。核心架构包含三个关键模块:视觉特征提取器负责处理2D/3D空间信息,语言理解模块解构自然语言指令的语义逻辑,动作预测头则将前两者融合后生成机器人控制序列。这种设计突破传统机器人控制系统的模块化限制,实现从感知到行动的端到端映射。
在模型扩展方面,研究团队创造性地引入双路径训练机制:一条路径专注于静态空间特征提取,另一条路径则侧重动态轨迹预测。这种设计使模型能同时捕捉物体的空间属性和运动规律,特别适用于需要连续动作的任务场景。测试数据显示,这种架构在需要多步骤操作的叠毛巾任务中准确率达到97.2%,显著优于传统分步处理方案。
核心技术突破
模型的持续预训练策略采用分层监督信号融合技术,将2D检测分割、3D物体定位、层次化任务分解等12种监督信号进行动态加权整合。这种创新方法使模型在处理复杂任务时,既能保持对细节的精准把控,又能维持整体任务逻辑的连贯性。在分拣水果任务中,模型展现出对不同形状、质地物体的精准识别能力,分类准确率突破99%。
动作建模方面,研究团队开发了基于动力学约束的动作块预测机制。该机制通过同时施加前向与逆向动力学约束,构建动作序列的双向关联性。这种设计使机器人能够预判动作后果并动态调整执行策略,在擦拭桌面这类需要实时调整的任务中,执行效率提升37%。实验数据显示,该机制使动作规划的容错率提高至92.4%。
空间感知创新
模型的空间增强模块采用多模态特征融合技术,通过建立文本指令与空间特征的双向注意力机制,实现语义逻辑与几何空间的精准对齐。在"左侧第三个抽屉"这类空间指令测试中,模型的空间定位误差小于1.2厘米,较同类模型提升近40%。这种突破性设计使机器人能够准确理解"将红色杯子放在蓝色笔记本右侧"等复杂指令。
在轨迹预测方面,研究团队引入时空注意力机制,该机制能动态捕捉物体运动轨迹的关键节点。测试显示,在预测移动物体的运动路径时,模型的轨迹预测误差比传统方法降低52%。这种能力在分拣水果任务中尤为关键,使机器人能够准确预判滚动水果的运动轨迹。
应用场景拓展
在家庭服务领域,模型展现出卓越的任务泛化能力。从整理桌面到折叠毛巾,再到擦拭污渍,单个模型即可完成12类家务操作。实测数据显示,在不同光照条件和物品摆放情况下,任务完成率保持在96%以上。这种能力源于模型对物体属性和空间关系的深层理解。
工业分拣场景中,模型展现出对异构物体的精准识别与处理能力。在水果分拣测试中,模型能准确区分苹果、橙子、香蕉等10类水果,并根据大小、成熟度进行多维度分类。这种能力使其在自动化分拣系统中具有显著优势,测试分拣效率达到人工的2.3倍。
开源生态建设
项目开源后,开发者社区已贡献超过200个定制化任务模块。研究团队构建的持续学习框架,支持模型通过在线学习快速适应新任务。在社区测试中,模型通过微调即可掌握开药瓶、积木堆叠等新技能,学习周期缩短至传统方法的1/5。
模型的跨平台适配能力也值得关注,目前已支持ROS2、MoveIt等主流机器人框架的无缝集成。这种开放性设计使其能够快速部署到不同机器人平台,在UR5机械臂和波士顿动力Atlas人形机器人上的移植测试均取得成功。

技术挑战与展望
尽管模型在实验室环境中表现出色,但在真实场景中仍面临挑战。光照变化、遮挡问题以及动态环境适应性仍需进一步优化。研究团队正在探索基于强化学习的自适应调整机制,以提升模型在非结构化环境中的鲁棒性。
未来发展方向包括多机器人协作能力和更精细的力控操作。通过引入触觉反馈和力觉感知,模型有望在精密装配、外科手术辅助等高精度场景中实现突破。这些改进将推动通用机器人操作模型向更广泛的应用领域拓展。