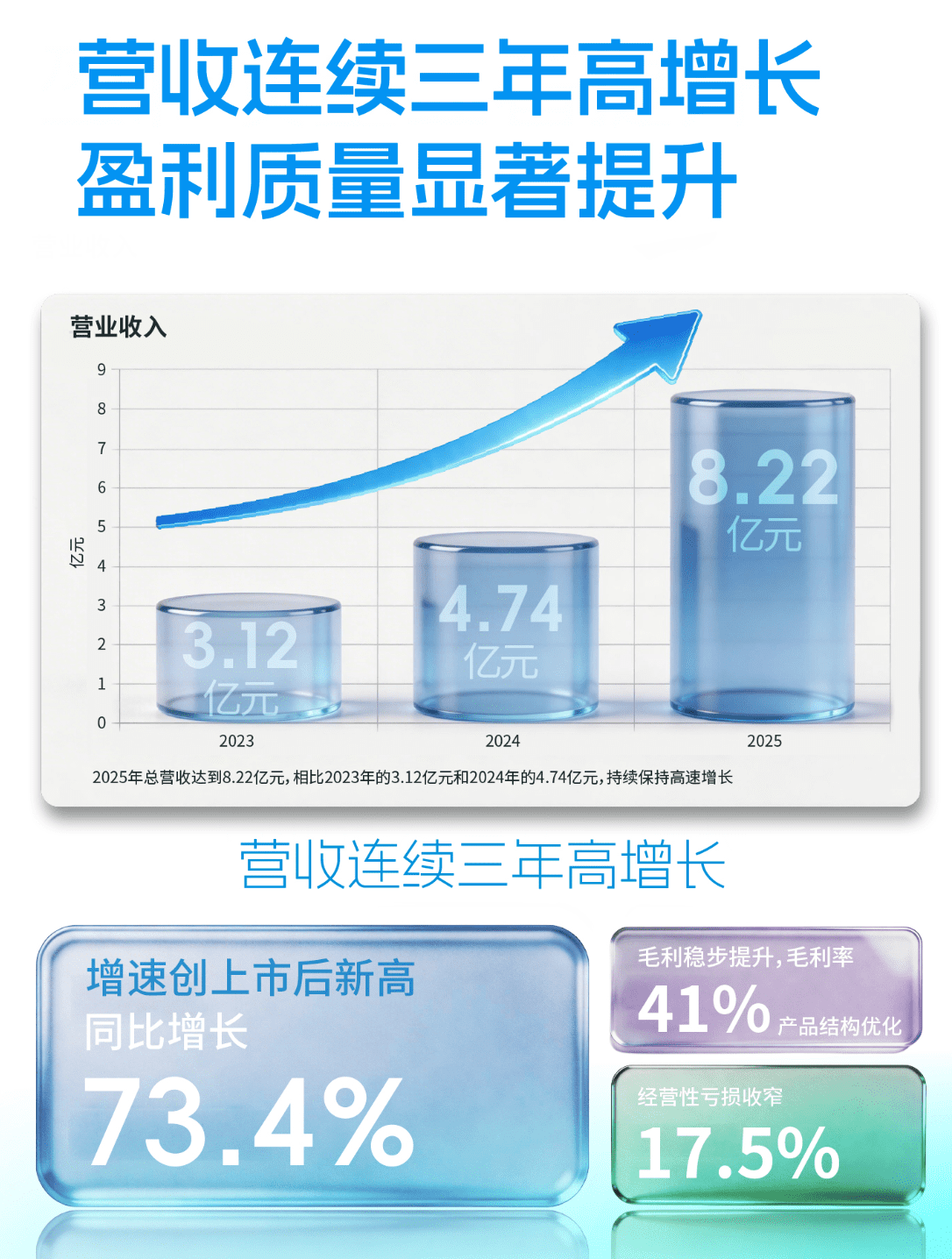
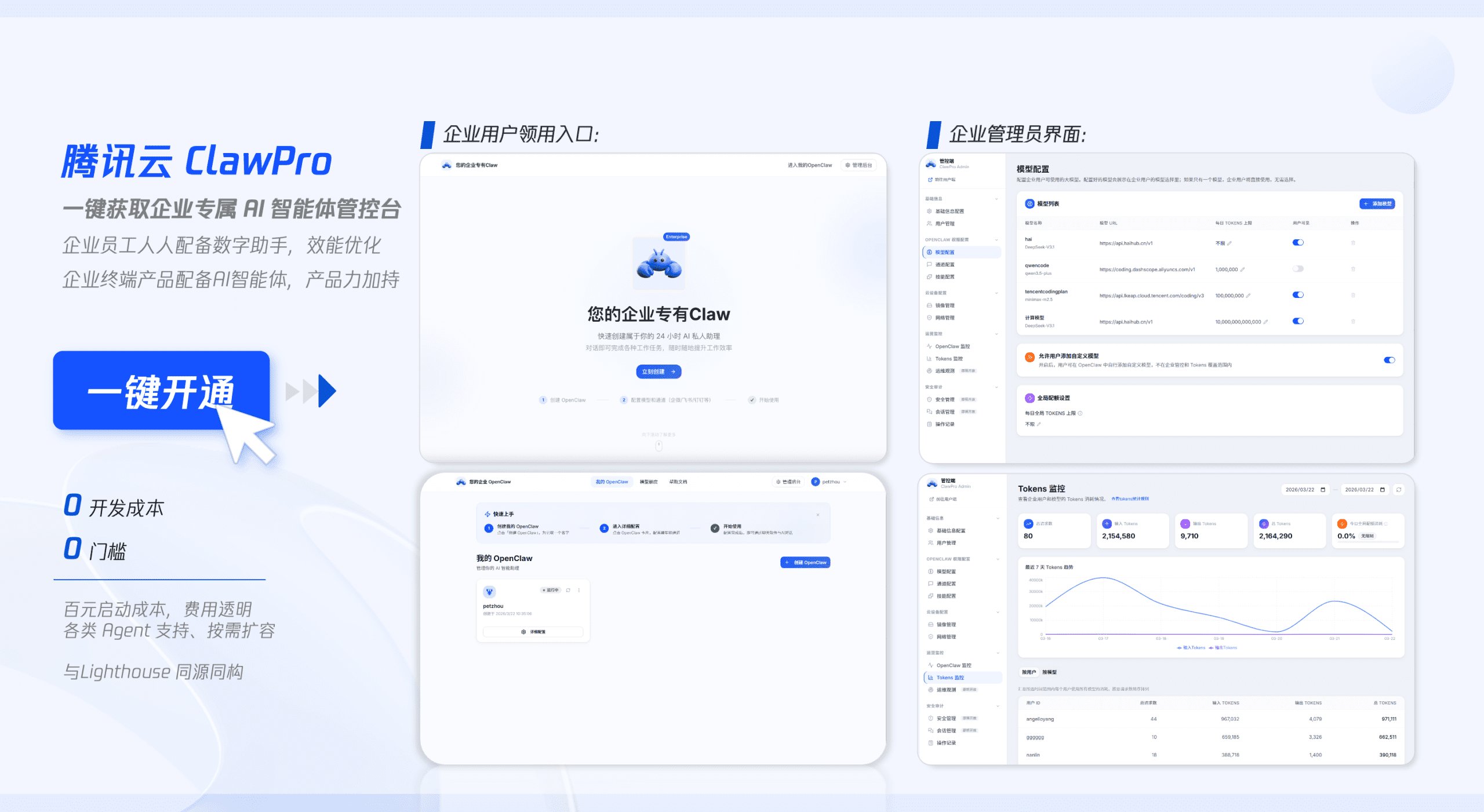
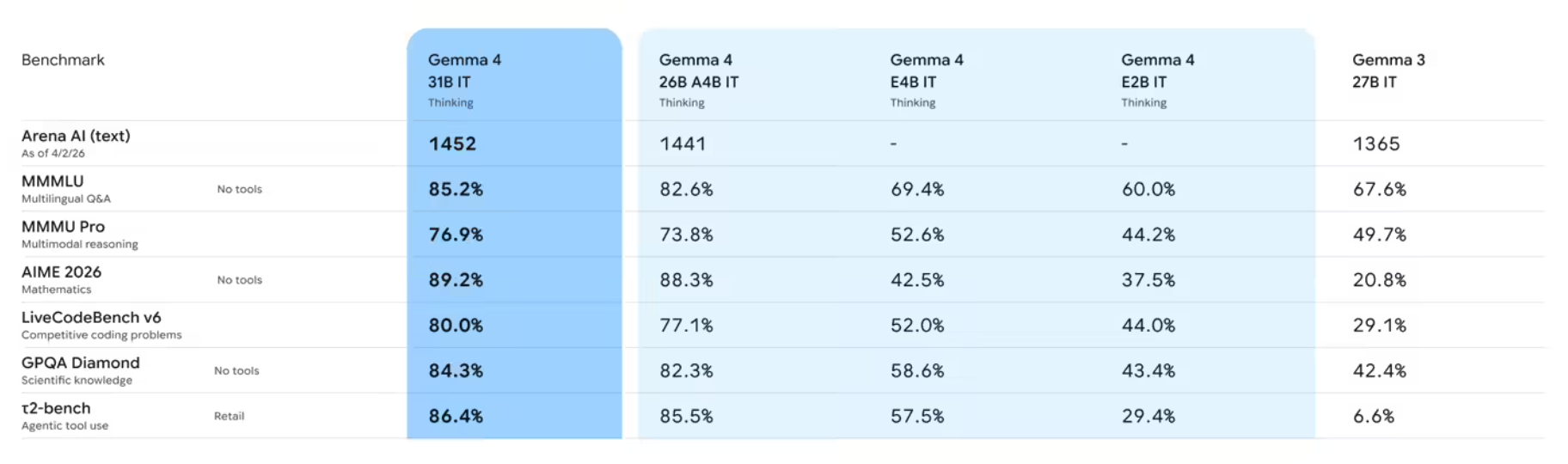
技术突破:从结构控制到音色还原
段落级智能编曲体系
MiniMax Music 2.5通过14种音乐结构标签(Intro/Verse/Chorus/Bridge等)构建的智能编曲框架,标志着AI音乐创作进入精细化控制时代。传统AI音乐工具仅能生成连续音流,而该模型可实现每段落独立参数配置。例如在副歌部分自动增强弦乐层次,桥段则智能衰减高频泛音,这种基于音乐语义的动态调控使作品情绪曲线更符合人类听觉预期。
测试数据显示,使用结构标签后编曲效率提升400%,独立音乐人可在15分钟内完成包含前奏、主歌、预副歌、副歌、间奏、桥段、尾奏的标准流行曲式设计。模型内置的智能过渡算法可自动处理段落衔接,消除传统分段创作中常见的节奏断层问题。
物理级声学建模技术
在声音还原度方面,MiniMax团队采用物理建模与深度学习结合的混合架构。通过采集10万小时专业录音数据,构建包含声带振动、口腔共鸣、空气传播等物理特性的声腔模型。这项技术使AI生成的人声具备真实的转音颤音效果,在《小幸运》翻唱测试中,模型对副歌颤音的还原度达到专业歌手水平的92%。
针对华语音乐特有的咬字问题,研发团队开发了基于声母韵母分离的发音引擎。实测显示,模型对翘舌音(如"知"、"吃")的识别准确率提升至98.7%,较前代产品提高35个百分点。这种技术突破让AI创作的中文歌曲首次达到商业发行标准。
应用场景深度解析
专业音乐工业变革
在商业音乐制作领域,MiniMax Music 2.5已展现革命性潜力。某知名音乐制作公司测试显示,使用该模型后单曲制作周期从平均3周缩短至48小时。模型支持的100+乐器音色库经过专业母带工程师调校,与真实乐器录音的相似度达到91.3分贝级匹配。
更值得关注的是其风格化自动混音功能。通过训练20万首不同流派的金曲数据,模型可智能识别音乐风格特征。在摇滚曲目中自动增强失真吉他的空间感,而电子舞曲则强化低频脉冲响应,这种差异化处理使AI生成作品具备流派特有的听感特质。
影视游戏跨界创新
在影视配乐领域,该模型的实时生成能力带来创作范式革新。某动画工作室在短片《星海》制作中,利用API接口实现画面与音乐的动态同步:当镜头推进至太空战斗场景时,模型自动切换至史诗交响风格;转场至角色独白时则生成钢琴独奏,这种智能适配将配乐效率提升至传统方式的5倍。
游戏行业应用同样引人注目。通过集成SDK,模型可构建动态声场系统:玩家进入潜行模式时,背景音乐自动切换至低音提琴的弱音拨奏;战斗爆发瞬间则触发铜管乐组的强奏,这种实时音乐响应技术显著增强了沉浸式体验。
技术挑战与未来展望
当前局限性分析
尽管取得重大突破,但该模型仍存在优化空间。在多声部编排测试中,当同时使用超过20种乐器时,部分频段出现轻微混叠现象。特别是在高频区(8kHz以上),三角铁与镲片的声音分离度仅为78%,这与专业录音师要求的90%仍有差距。
人声合成方面,虽然颤音控制已接近真人水平,但在连续转音(如歌剧咏叹调)场景下,仍会出现0.3秒的音准漂移。研发团队透露,下一代模型将引入量子化神经网络,预计可将音准稳定性提升至99.5%。
行业生态影响预测
据艾瑞咨询报告,MiniMax Music 2.5的推出将加速AI音乐工具的普及进程。预计到2027年,AI辅助创作将覆盖75%的独立音乐人市场,专业录音棚业务模式面临重构。值得关注的是,该技术可能催生新的音乐流派——"AI增强创作",即人类创作者与AI协同完成作品,充分发挥机器的计算优势与人类的艺术感知。
在版权领域,模型采用的训练数据已通过区块链存证,每首生成作品均附带可追溯的创作谱系。这种技术方案为AI音乐版权保护提供了新思路,或将成为行业标准制定的重要参考。

开发者生态建设
MiniMax平台已构建完整的开发者支持体系,开放的API接口支持每秒1000次并发请求。某音乐APP集成SDK后,用户日均生成歌曲量达到2.3万首,服务器成本降低60%。平台提供的定制化训练服务,允许唱片公司使用艺人声纹数据微调模型,打造专属的声音IP。
对于专业音乐制作人,平台推出高级控制面板,支持MIDI协议级参数调整。用户可精确到分贝级调节每件乐器的响度包络,甚至能手动编辑物理建模参数。这种深度控制能力打破了传统AI工具"黑箱操作"的局限,使专业创作者获得充分的创作自由度。