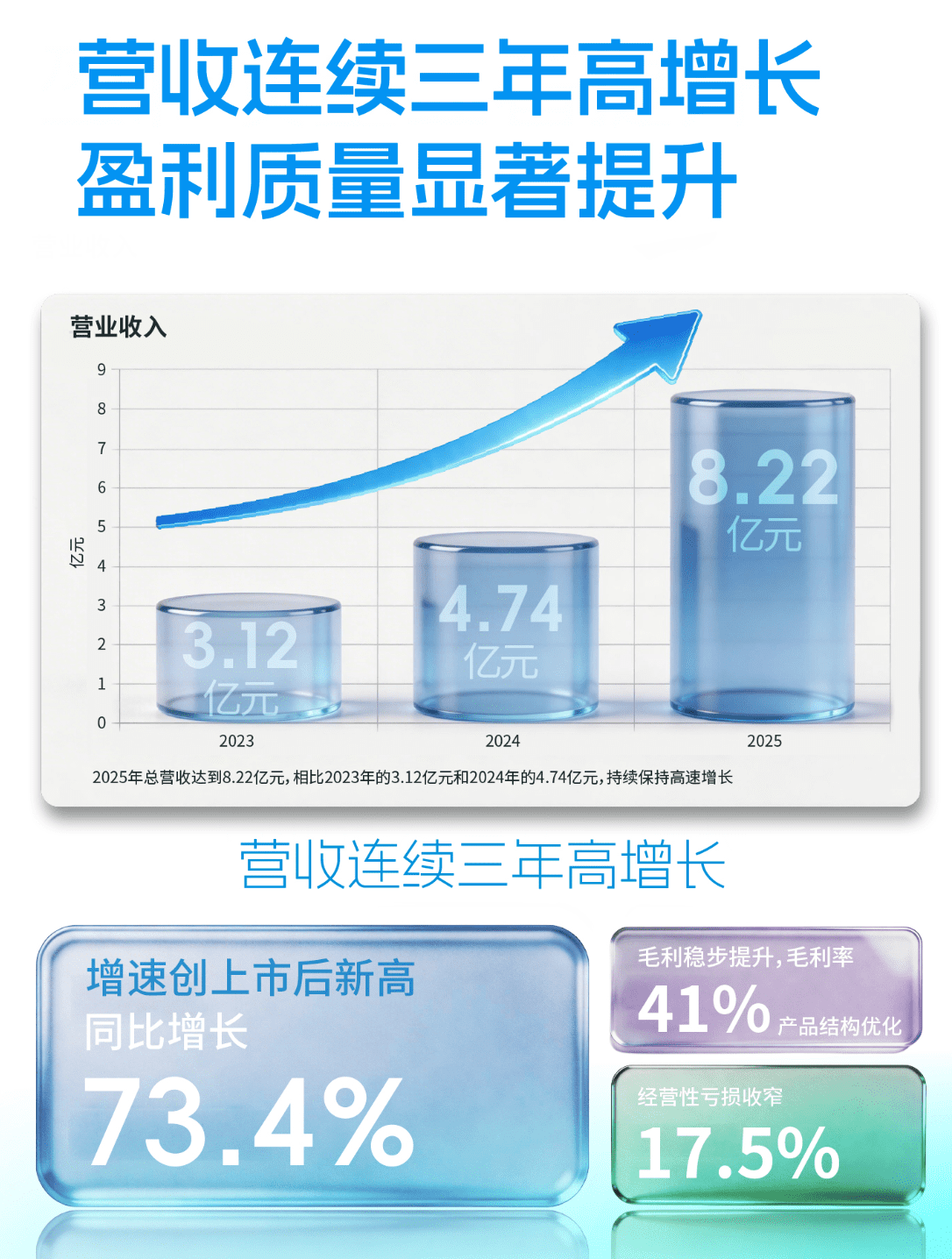
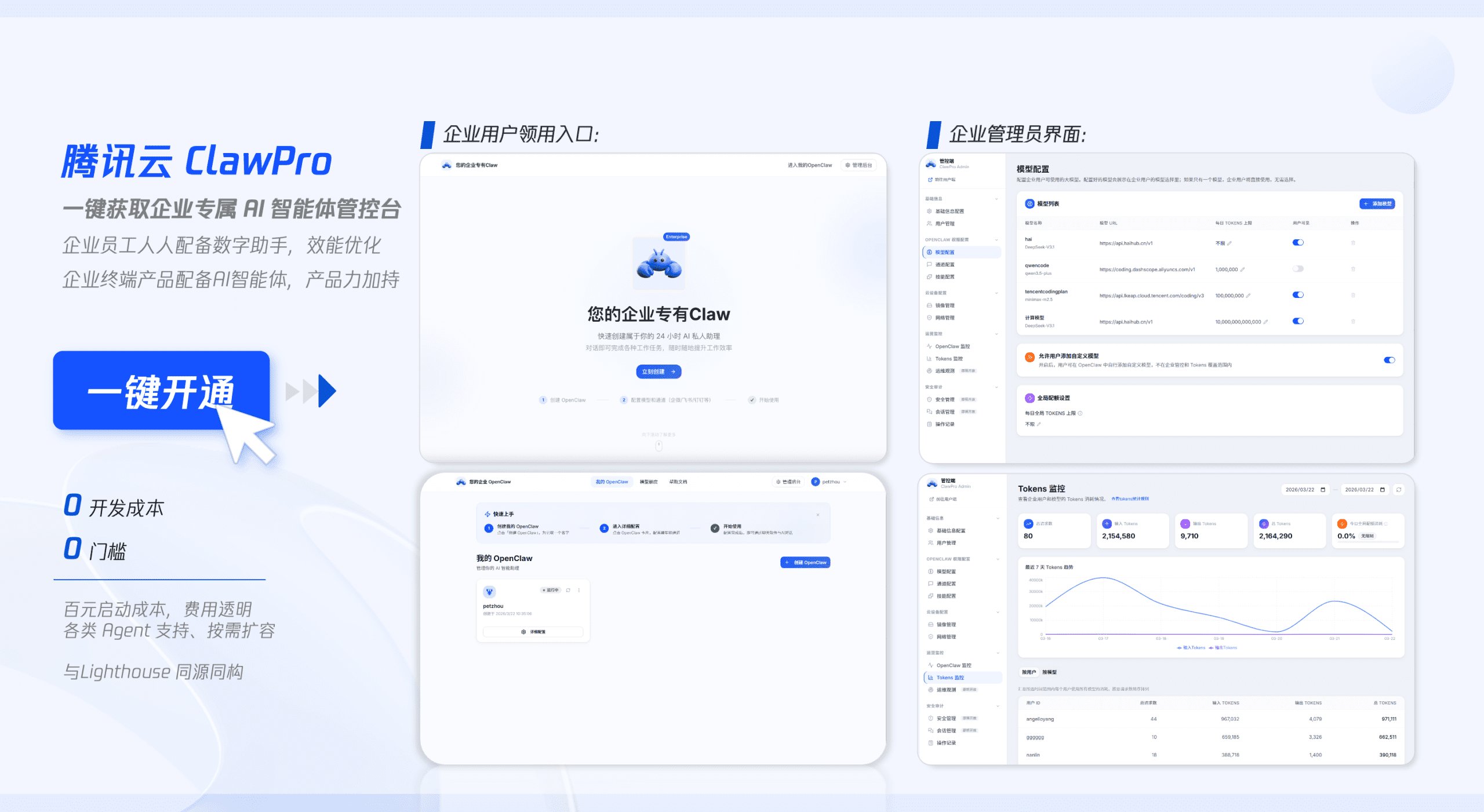
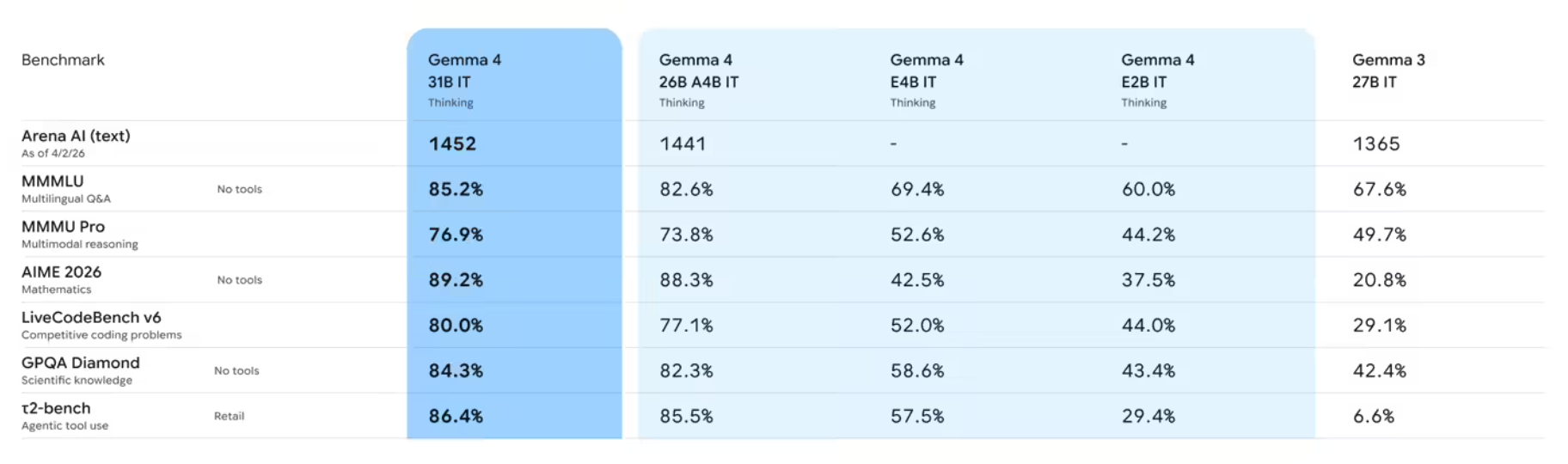
技术架构解析
VibeVoice-ASR采用独特的端到端架构设计,将传统语音识别流程中的多个独立模块整合为统一的计算框架。通过共享特征提取层,模型在保持运算效率的同时,实现了语音识别、说话者身份判断和时间戳标注的三重功能协同。

长上下文处理机制
为解决长音频记忆保持难题,研发团队创新性地改造了Transformer架构:
- 动态分块注意力机制实现局部与全局信息的平衡
- 分层记忆网络构建跨时间段的上下文关联
- 梯度累积算法优化超长序列的训练稳定性
核心功能实现
说话者分离技术
模型通过声纹特征聚类算法,在无需预注册声纹库的情况下实现:
- 实时声纹向量提取
- 基于谱聚类的说话者分类
- 动态说话者数量预测
热词引导策略
自定义热词功能采用双重干预机制:
- 前端词库构建TF-IDF权重矩阵
- 解码阶段引入热词偏置因子
- 动态调整beam search搜索路径
应用场景拓展
会议记录智能化
在某科技公司的实测数据显示:
| 指标 | 传统工具 | VibeVoice-ASR |
|---|---|---|
| 说话者识别准确率 | 82% | 95% |
| 专业术语识别率 | 76% | 89% |
| 处理速度 | 1.2倍实时 | 0.8倍实时 |
教学场景应用
模型在教育领域的特殊价值体现在:
- 支持多方言混合授课场景
- 自动标注重点内容时间节点
- 生成结构化课程大纲框架
部署实践指南
对于不同规模的用户需求,建议采用以下部署方案:
docker run -it --gpus all \
-v /local/models:/app/models \
-v /local/audios:/app/input \
microsoft/vibevoice-asr:latest未来发展方向
当前版本在以下方面仍存在优化空间:
- 超长音频(>2小时)的内存占用控制
- 重叠语音的精准分离技术
- 低资源语言的扩展支持
- 实时转录的延迟降低
模型团队透露,下一代版本将引入联邦学习框架,支持用户在不上传隐私数据的前提下进行领域自适应训练,这一创新可能彻底改变企业级语音识别系统的部署模式。