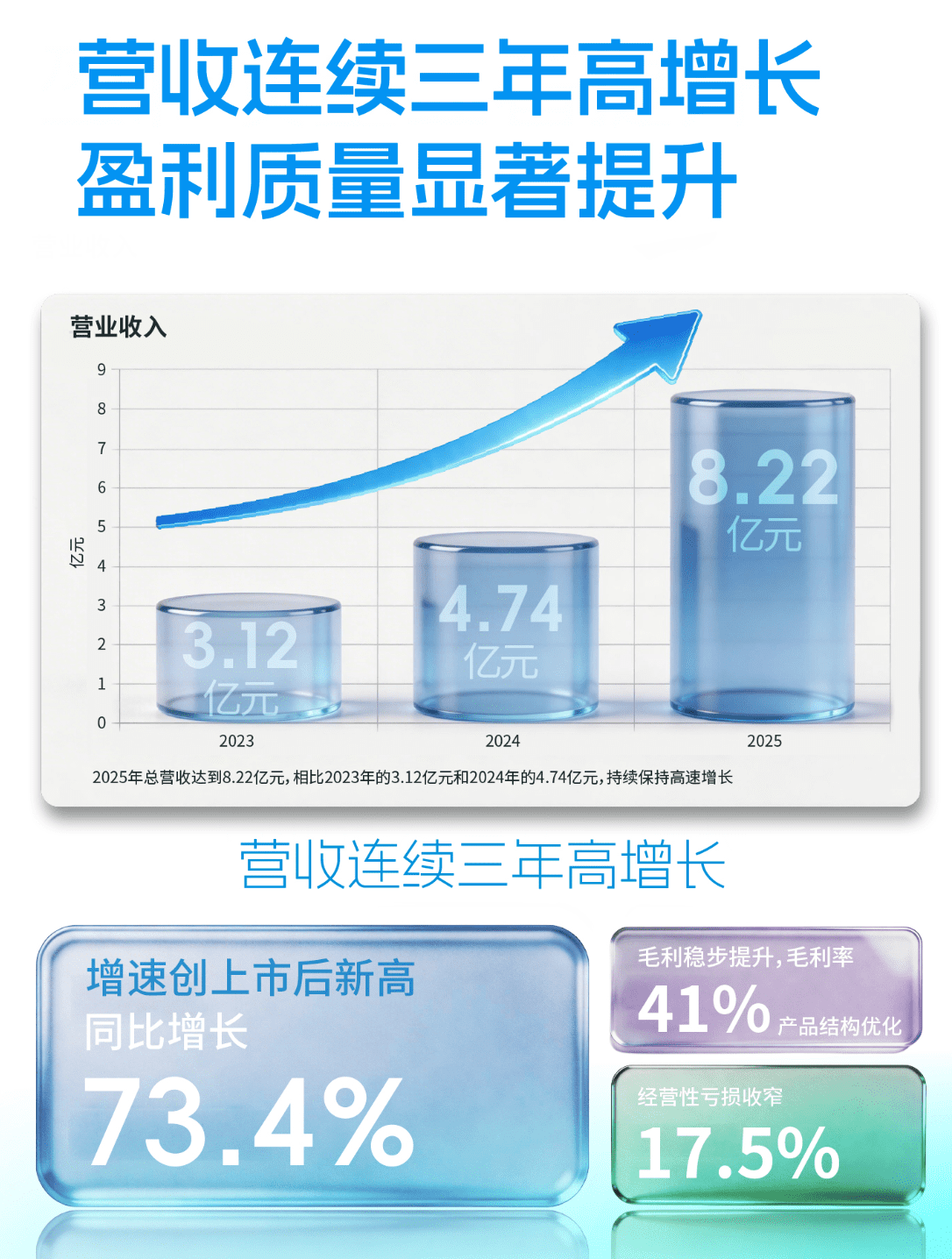
MMSI-Video-Bench的技术定位与行业价值
随着多模态大语言模型在视频理解领域的快速发展,传统评估体系在空间动态场景中的局限性日益凸显。上海人工智能实验室主导开发的MMSI-Video-Bench基准,正是针对这一痛点设计的革命性解决方案。不同于静态图像或简单动作识别的测试框架,该工具首次构建了覆盖时空双维度的综合评估体系,其核心价值在于将物理世界的复杂不确定性引入AI评估范畴。
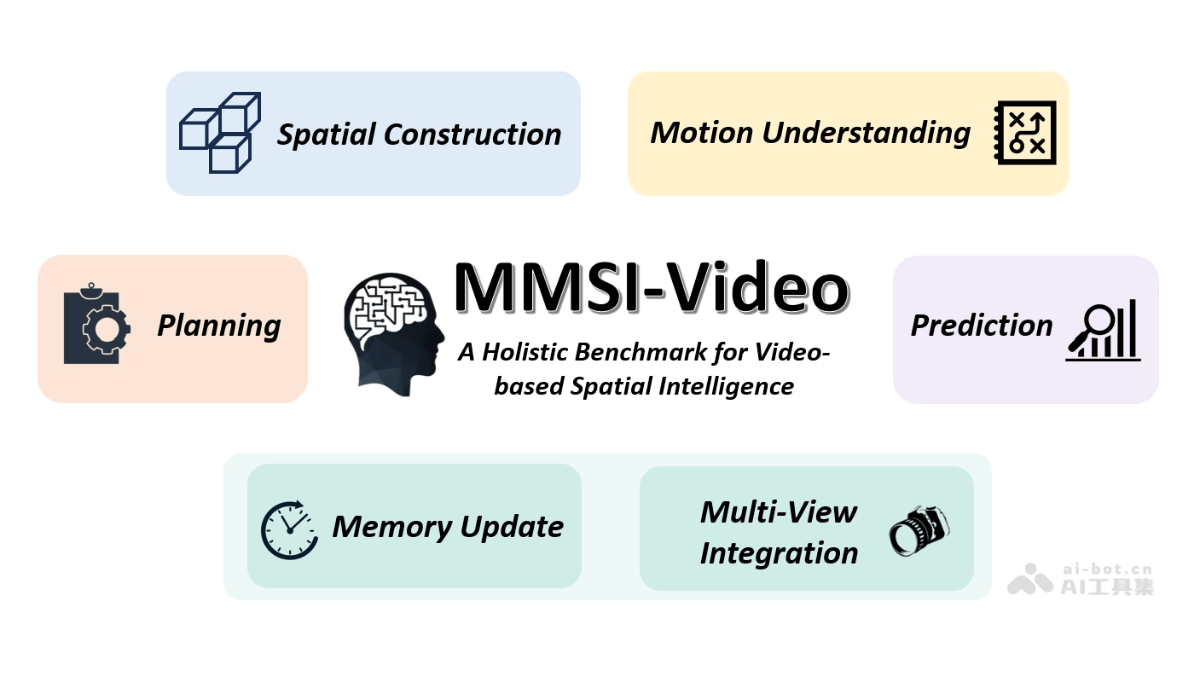
多维能力评估体系
- 空间感知维度:要求模型精确识别视频中物体的三维坐标、相对位置及遮挡关系,例如在自动驾驶场景中判断行人车辆的空间距离变化趋势
- 运动理解层级:分析物体运动轨迹的连续性特征,典型案例如工业机器人操作视频中的工具运动路径预测
- 规划与决策机制:测试模型基于视频时序信息生成操作指令的能力,仓库物流机器人避障任务测试显示顶尖模型准确率仅58.7%
- 跨视频推理突破:创新性设计需要关联不同视频片段的因果链问题,如将建筑工地安全监控视频与设备操作手册视频进行逻辑关联
据2026年评估报告显示,现有开源模型在跨视频推理任务上的平均得分不足40%,暴露出现有技术的重大缺陷。
技术架构的创新突破
真实场景驱动机制
摒弃传统模板生成方式,直接从现实物理世界采集动态视频数据。项目团队在全球12个城市采集的140段匿名视频中,包含雨雪天气、夜间低光照等极端场景,有效提升了测试环境的挑战性。这种设计迫使模型必须处理真实世界的不规则变量,例如卡车卸货视频中因货物遮挡导致的临时空间关系变化。
多模态时空融合技术
video_frames = load_video_segment()
spatial_features = 3D_CNN_extractor(video_frames)
temporal_features = Transformer_encoder(spatial_features)
multimodal_fusion = cross_attention(text_query, temporal_features)通过上述架构,系统要求模型在3秒内完成对视频关键帧的空间定位,并同步解析语音指令中的方位指示词。在机器人抓取测试中,融合视觉与语言信息的模型成功率比单模态模型高出32%。
专家级标注体系
由11位3D视觉专家构建的四级标注框架:
- 基础空间关系(物体相对位置/距离)
- 运动轨迹建模(速度/加速度分析)
- 因果逻辑链(事件触发机制)
- 跨场景知识迁移
每个问题附带平均150字的解释性标注,例如"叉车托盘放置错误源于货架空间计算偏差"的详细力学分析。
行业应用实践案例
自动驾驶系统压力测试
某头部车企采用该基准评估新一代ADAS系统,在127个街景视频测试中发现:
- 雨雾天气中行人距离判断误差率达19.3%
- 复杂立交场景的路径规划延迟超800ms 这些数据直接推动其感知模块的算法重构,召回率提升至92.6%。
工业机器人智能升级
库卡机器人研发部门通过基准中的装配线视频测试,发现现有模型在工具切换场景存在认知断层。通过引入时空注意力机制,操作成功率从74%提升至89%,每年减少产线停工损失约$120万。
未来发展与挑战
虽然MMSI-Video-Bench已建立视频空间智能评估的新标准,但仍面临三大挑战:
- 长尾场景覆盖不足(仅占数据集12%的极端案例)
- 实时性评估缺失(当前测试为离线模式)
- 多智能体协作场景空白
上海AI Lab团队透露,2026年第三季度将发布支持实时流媒体分析的2.0版本,并纳入无人机集群协作等新型测试场景。随着5G边缘计算的发展,该基准有望成为工业4.0智能化升级的核心检测工具。