移动终端的AI新纪元:Gemma 4带来的机遇与局限
当谷歌推出Gemma 4系列时,业界普遍将其视为端侧AI发展的里程碑。不同于以往那些需要庞大云端算力支撑的巨型模型,Gemma 4中的E2B和E4B版本被设计为可以直接在智能手机、树莓派等资源受限设备上运行。这种“本地化”的尝试,旨在解决隐私保护、网络延迟以及离线可用性三大痛点。然而,在经历了数周的深度实测后,我们发现这款被誉为“最强端侧模型”的产品,其表现既令人惊喜,又充满遗憾。
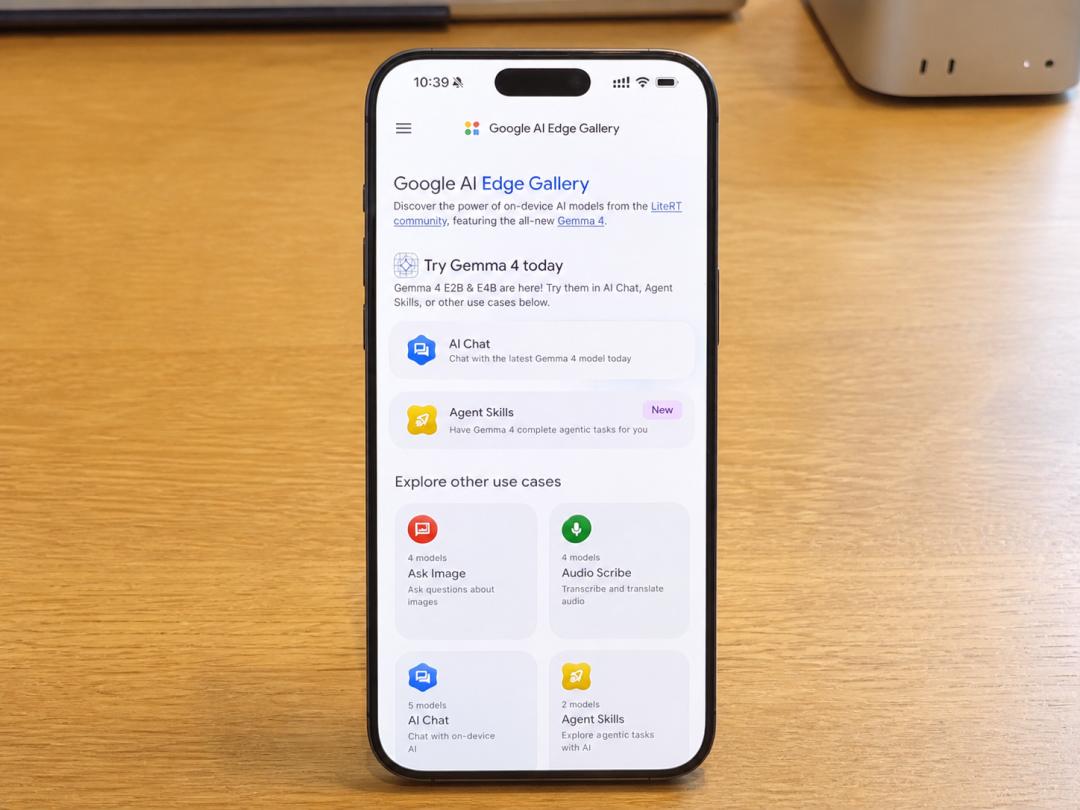
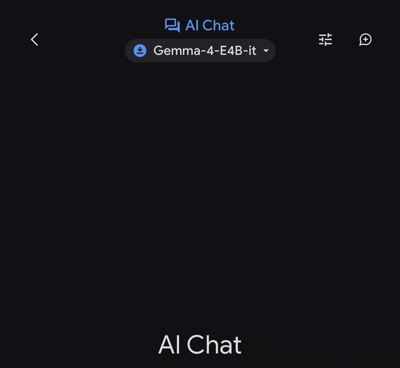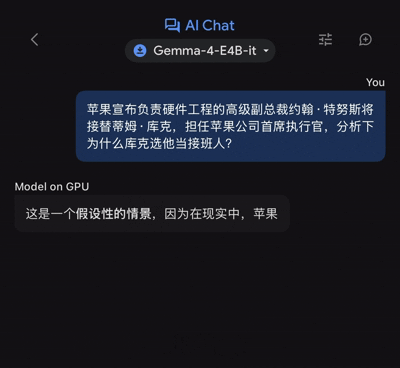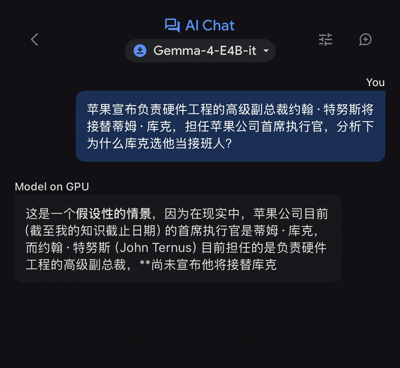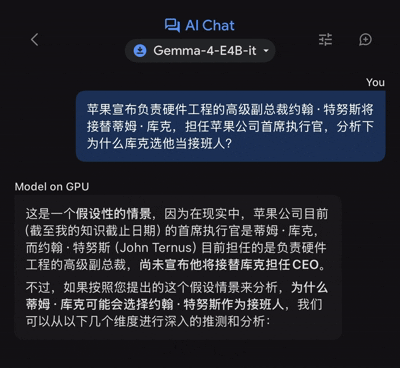
端侧模型的核心逻辑在于用算力换时间,用本地存储换隐私。Gemma 4 E4B在iPhone 17 Pro Max上的响应速度确实令人印象深刻,输入指令后几乎零延迟即可开始生成内容。这种即时反馈体验,对于需要快速检索信息的场景来说是革命性的。例如,在询问关于苹果公司管理层变动的复杂新闻解读时,模型能够在46秒内输出结构完整、逻辑清晰的长文答案。这证明了在特定知识领域,端侧模型已经具备了替代传统搜索引擎的潜力,为用户提供了一个“永远在线”的私人知识库。
知识库的边界:百科全书还是幻觉制造机?
尽管在新闻解读和常识问答上表现尚可,但Gemma 4在应对专业或细粒度知识时,暴露出了其参数量限制带来的致命弱点。当我们将问题从新闻转向历史领域,例如询问“吴越国如何在重税政策下维持八十年太平”时,模型给出的回答虽然通顺,但缺乏深度的史料支撑,更多是基于概率的拼凑。这反映了当前端侧模型的一个普遍困境:为了在有限的显存和算力下运行,模型必须进行大幅度的蒸馏和剪枝,导致其知识密度和准确性下降。
更为严重的“翻车”发生在基础文学常识上。当要求模型背诵李白的《将进酒》时,它不仅记错了作者信息,甚至连部分诗句都出现了偏差。这种“一本正经地胡说八道”现象,在学术界被称为“模型幻觉”。对于端侧模型而言,由于缺乏实时联网检索的能力(除部分联网百科接口外),它完全依赖于训练数据中的记忆。一旦训练数据截止(Gemma 4知识截止于2023年10月),且模型参数不足以覆盖海量细节,幻觉便成为不可避免的风险。
这意味着,虽然Gemma 4可以作为一个高效的“启发式”助手,帮助用户快速构建答案框架或提供基础信息,但绝不能将其作为权威的事实来源。对于需要高精度引用的工作场景,用户仍需进行二次人工校验。这也反向促使开发者思考:未来的端侧模型是否应该引入更轻量级的RAG(检索增强生成)技术,允许模型在本地快速检索用户自带的离线知识库,从而弥补自身知识库的不足?
工具属性的觉醒:专用场景才是主场
抛开知识问答的局限,Gemma 4在工具型应用上的表现却意外地令人惊喜。这主要得益于谷歌针对特定任务进行的专项优化。在翻译领域,基于Gemma 3构建的TranslateGemma 4B模型展现了惊人的性能,其效果甚至在某些场景下超越了更大规模的通用模型。这为移动端翻译提供了一个全新的解决方案:无需联网、无需云端API、完全离线且保护隐私。
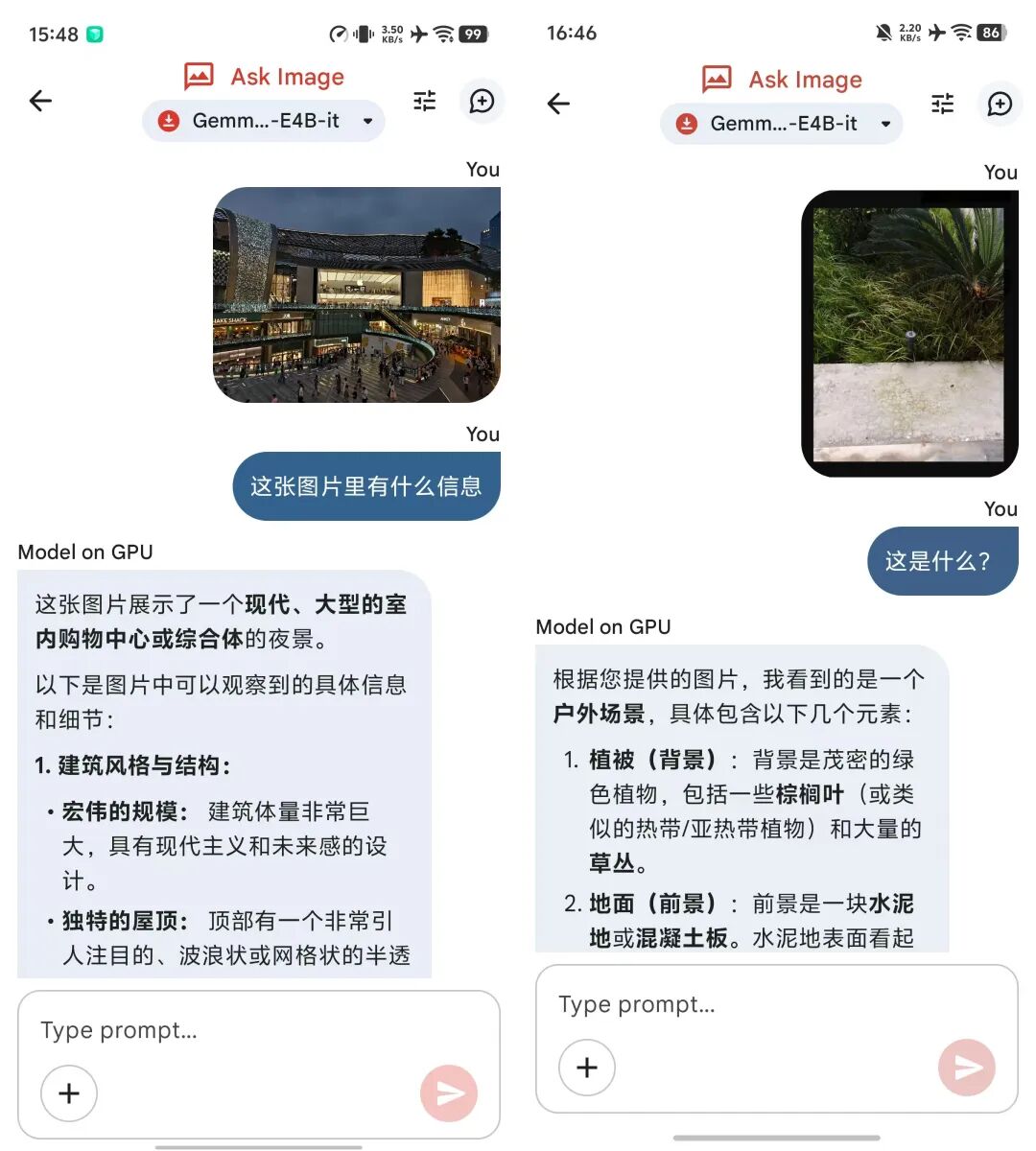
除了翻译,Gemma 4在计算器、简单数学题解题以及图像识别方面也有不俗表现。在飞行等无网络环境下,用户可以直接上传相册中的图片,询问其中的物品信息或文档内容。虽然对于复杂的视频分析或极度细微的图像细节识别,端侧模型依然力不从心,但在“看图说话”的基础层面上,它已经足够胜任。这种“专用能力”的强化,使得Gemma 4不再是通用的聊天机器人,而更像是一个集成了多项技能的瑞士军刀。
然而,在文本处理方面,Gemma 4的语病检查功能却未能达到预期。在测试中,模型往往混淆“语病检查”与“文本润色”的界限,倾向于直接修改原文风格,而非仅仅指出错误。这可能是因为其训练语料中缺乏足够多的“纠错”类样本,导致模型更习惯“改写”而非“诊断”。用户若发现模型无法精准执行指令,尝试通过更严格的Prompt工程(如强调“无语病不改”)可以在一定程度上改善体验,但这无疑增加了使用门槛。

硬件门槛与未来展望:16GB内存是标配吗?
Gemma 4在端侧的运行体验,与手机硬件配置有着极强的相关性。实测表明,运行流畅度与内存大小直接挂钩。对于iOS用户,建议至少配备8GB运行内存,推荐12GB;而安卓用户则需要12GB起步,最佳体验需16GB。这主要是因为端侧模型加载权重时需要占用大量RAM,而推理过程中的中间激活值也会消耗额外内存。如果硬件配置不足,不仅会导致生成速度急剧下降,甚至可能触发系统杀进程,导致服务中断。

随着手机硬件技术的进步,16GB内存逐渐成为高端旗舰机的标配,这为端侧模型的普及铺平了道路。谷歌通过与高通、联发科等芯片厂商的合作,正在优化模型在NPU(神经网络处理器)上的运行效率,力求实现“近乎零延迟”的体验。此外,Apache 2.0的开源许可协议也意味着,开发者可以自由地将Gemma 4集成到各种应用中,无需担心商业授权问题。这将加速端侧AI在物联网、边缘计算等领域的应用落地。

未来,端侧模型的发展将不再局限于单一的大模型,而是走向“模型矩阵”与“智能体”协同的路线。一方面,针对翻译、图像识别等特定任务的专业小模型将更加成熟;另一方面,具备自主规划能力的智能体(Agent)将能够调用这些专业模型,完成更复杂的任务链。例如,一个端侧智能体可以自动识别文档中的错误,调用翻译模型进行修正,最后生成摘要。这种协同效应,将把端侧AI的能力边界推向新的高度。

对于普通用户而言,Gemma 4的推出意味着手机将不再只是一个通讯工具,而是一个具备思考能力的智能终端。虽然目前的Gemma 4在全面性上仍有欠缺,存在“不完美”的瑕疵,但它无疑是端侧AI发展道路上坚实的一步。它证明了在有限的硬件条件下,大模型依然可以为用户带来实质性的便利。对于追求效率、注重隐私或经常处于离线环境的用户来说,Gemma 4是一个值得尝试的工具。
从长远来看,端侧模型的竞争才刚刚开始。随着算法优化和硬件算力的双重提升,未来的端侧模型将更聪明、更精准、更高效。我们可以期待,在不远的将来,手机将能够独立处理更复杂的任务,甚至在一定程度上替代云服务,实现真正的“端云协同”与“端侧优先”。而Gemma 4,正是这场变革的先锋。