在基于可验证奖励的强化学习(RLVR)技术快速发展的背景下,大语言模型在数学求解、代码生成和SQL推断等任务上取得了显著进展。然而,一个令人困惑的现象逐渐浮出水面:许多经过RL微调的模型虽然在单次作答场景下表现出色,但在允许多次尝试时,其综合性能反而出现下降。

多样性坍塌的本质分析
这种看似矛盾的现象背后,隐藏着一个深层次的问题:模型在强化学习过程中逐渐丧失了原本丰富的解题路径和候选解空间。传统RL微调方法往往过度关注奖励最大化,而忽视了模型知识分布的多样性保护。
从数学角度分析,大多数RL后训练方法采用reverse-KL或直接移除divergence约束的做法存在明显缺陷。reverse-KL本质上具有mode-seeking特性,会鼓励策略向少数高概率模式收缩;而无divergence约束则意味着模型在训练过程中缺乏对原始知识分布的显式保护机制。
这种机制缺陷导致模型日益集中于少量"熟悉答案",进而引发Pass@k下降、既有能力遗忘以及跨任务泛化能力减弱。若将基础模型视为已掌握大量知识与多样解法的"知识分布",那么RL微调的理想目标应该是在保留既有能力的前提下进一步提升任务表现。
divergence选择的理论重构
针对这一困境,研究团队提出了根本性的解决方案:将divergence从"约束项"重新定义为"保多样性机制"。这一转变的核心在于认识到divergence项不应仅仅是训练时的附带正则项,而应成为主动保护模型多样性的核心工具。
具体而言,研究团队放弃了传统的reverse-KL,转而引入更具mass-covering性质的f-divergence。与倾向于收缩至单一模式的reverse-KL不同,这类divergence会鼓励新策略继续覆盖参考策略中原本存在的多种解法。
以forward-KL为例,其数学表达式体现了期望对参考策略πref的依赖。只要参考策略曾覆盖过某些合理解法,新策略πθ便不能轻易将其概率压至接近零。这种机制本质上是一种rehearsal mechanism(复现机制),使模型在训练过程中持续参考初始策略的分布,从而保留原有的知识覆盖范围。
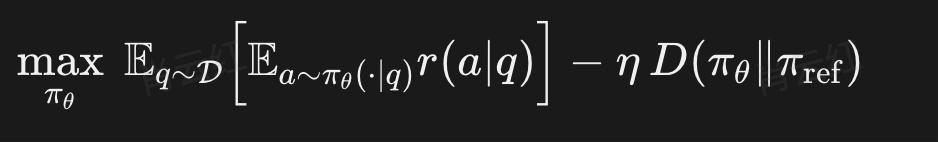
DPH-RL方法的技术创新
基于上述理论洞察,研究团队开发了DPH-RL(Diversity-Preserving Hybrid RL)方法。该方法在技术实现上具有多个创新点:
分情况训练策略是DPH-RL的核心特征。方法将训练数据明确划分为探索集合(Dexp)和近完美集合(Dpef),针对不同性质的样本采用差异化的训练目标。
对于模型尚未掌握的困难样本(Dexp),不加入任何KL penalty,让模型在困难样本上更激进地探索高奖励解法。这部分采用标准PPO-clip目标,专注于性能提升。
而对于模型已基本掌握的样本(Dpef),则依靠f-divergence保持在正确样本上的多样性。模型在这部分样本上不再追求"获取更高奖励",而是尽量不偏离原本已表现良好的行为分布。
高效实现方案是DPH-RL的另一个亮点。作者采用基于generator function的方式计算f-divergence,仅需从初始πref预采样,无需在训练过程中维护在线reference model。这种设计显著降低了计算成本,使方法更适合实际大规模后训练场景。
实验验证与性能分析
在实验设计方面,研究采用Llama3.1-8b作为基础模型,在BIRD数据集上进行训练,并在BIRD、Spider及数学任务数据集上测试OOD泛化能力。这种设置能够全面评估方法在in-domain和cross-domain场景下的表现。
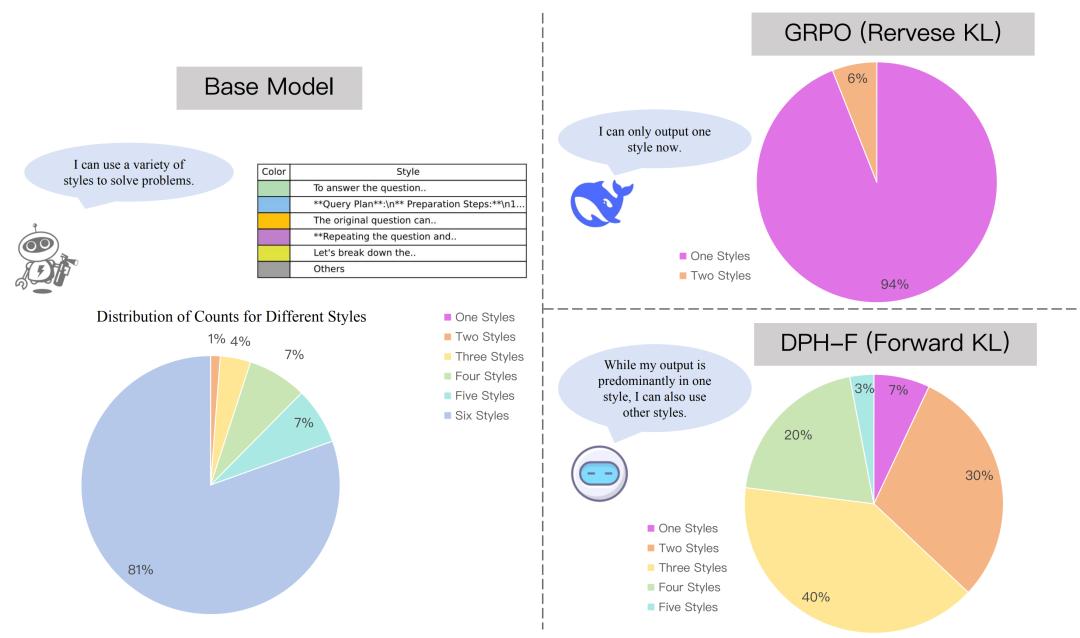
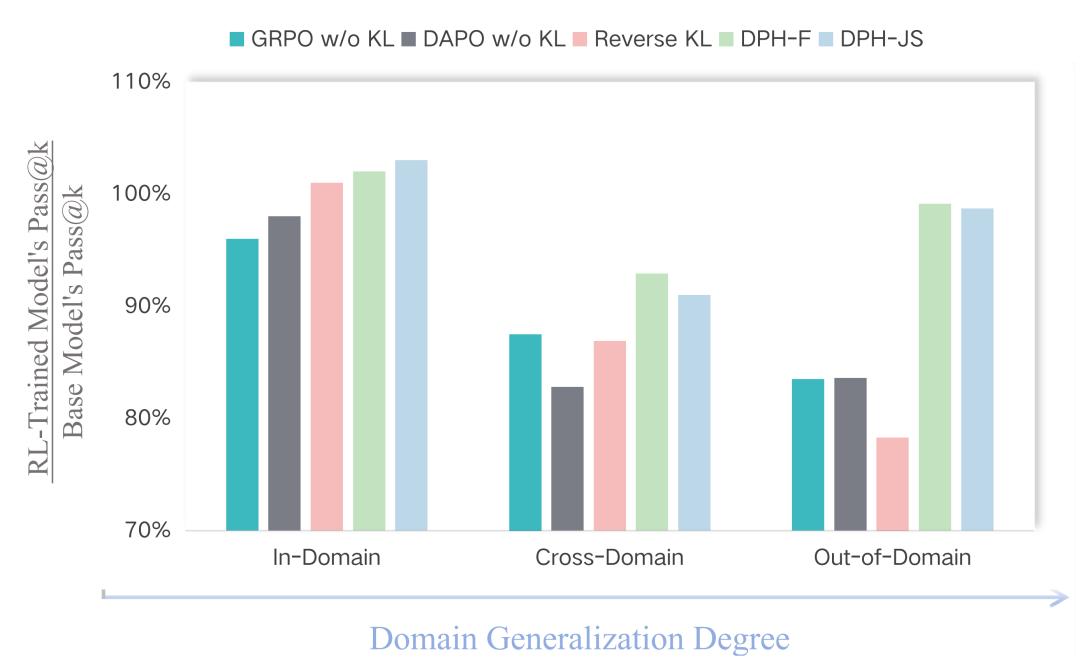
In-Domain性能分析显示,传统方法如GRPO与DAPO虽然可能提升了Greedy(相当于Pass@1)表现,但其Pass@8和Pass@16分数均显著低于Base Model,证实了多样性坍塌的存在。相比之下,DPH-F与DPH-JS不仅Greedy分数最高,其Pass@8分数也超越了Base Model。
具体数据表明,DPH-JS的Pass@8分数较GRPO高出4.3%。在更大的k设置下,DPH-RL更接近base model,有效缓解了Pass@k的崩塌现象。这一结果验证了mass-covering divergence在保护多样性方面的有效性。
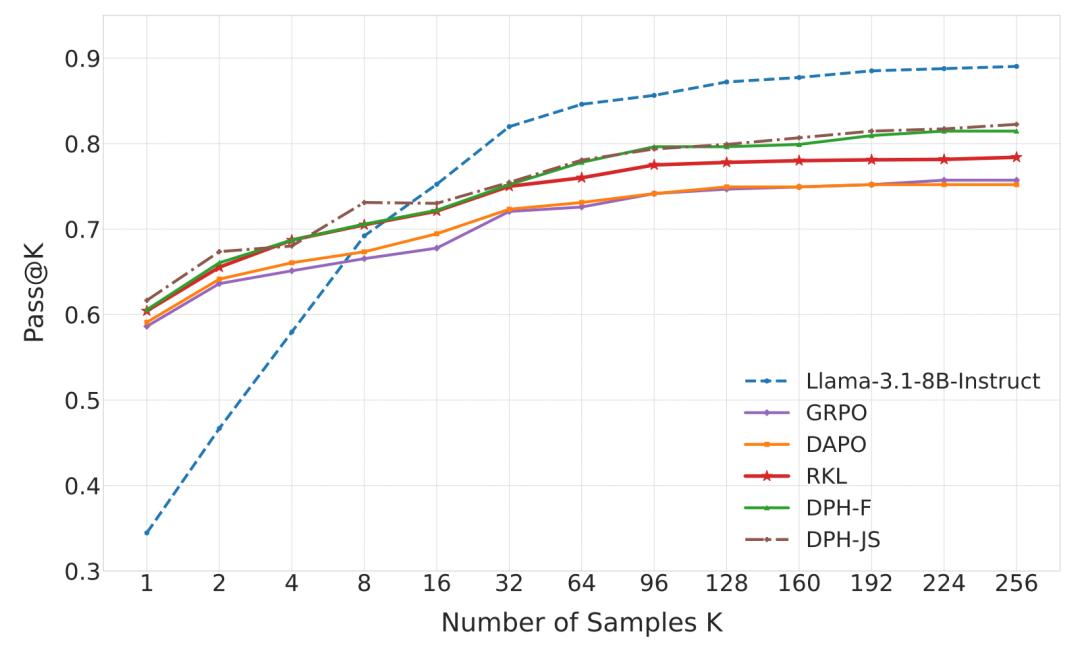
跨域与OOD性能测试进一步证明了DPH-RL的优越性。将SQL任务上的Spider数据集视为cross-domain,数学数据集视为out-of-domain,所有仅在SQL数据集Bird上训练得到的RL模型在分布发生偏移时都会出现不同程度的性能下降。
然而,DPH-F与DPH-JS的Pass@k分数显著高于其他所有RL方法,最接近Base Model的原始水平。特别值得注意的是,DPH-F的Pass@16分数较DAPO高出9.0%,而Reverse-KL在OOD场景下表现严重下滑。这些结果充分说明,通过保留解决方案的多样性,DPH-RL能够更有效地防止灾难性遗忘。
机制解析与平衡策略
为了深入理解DPH-RL的工作机制,研究团队通过解构模型在Pass@8上的表现,分析了RL微调前后的知识动态。分析聚焦于两个关键指标:保留率(Keep Rate)和额外探索率(Additional Exploration Rate)。
保留率衡量的是知识稳固度,即基础模型原先能做对的样本在微调后依然保持正确的比例。实验结果显示,DPH-RL拥有极高的保留率,能有效留存模型已有的稳固知识,从根本上避免了"灾难性遗忘"。
额外探索率则衡量能力增量,指基础模型原先做错的样本在微调后转而做对的比例。相比之下,GRPO虽然具有一定的探索能力,但在获取新知识的同时,往往伴随着对原有能力的剧烈侵蚀。
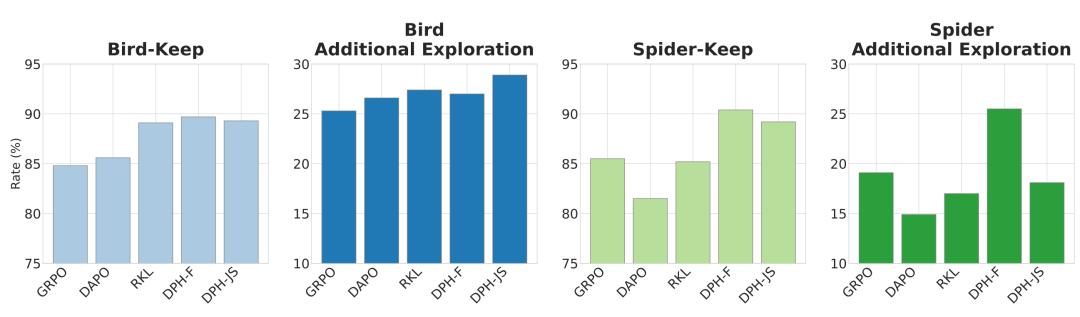
这种对比揭示了DPH-RL的核心优势:通过对强化学习组件的功能解耦,实现了保留与探索的显式平衡。方法证明,在通过RL提升模型能力上限的同时,稳固已有的知识底座是取得最终胜出的关键。
技术细节与实现考量
在具体实现层面,DPH-RL采用了多项技术优化确保方法的实用性和可扩展性。f-divergence的选择是一个关键决策点,研究团队对比了多种divergence形式,最终确定了最适合多样性保护的方案。
对于JS divergence,其生成函数可写为特定形式,提供了更加平滑的分布约束方式。这种对称性设计有助于在训练过程中保持稳定性,避免因divergence选择不当导致的训练震荡。
样本划分策略是另一个技术亮点。方法不是简单地对所有样本施加统一约束,而是基于模型当前表现进行动态划分。这种自适应机制确保了对不同难度样本的差异化处理,既保证了探索效率,又维护了多样性保护。
应用前景与扩展方向
DPH-RL方法的成功不仅为解决RL微调中的多样性危机提供了有效方案,更为后续研究开辟了新的方向。在多模态学习场景下,多样性保护显得尤为重要,因为不同模态之间的交互需要模型保持灵活的问题解决能力。
在持续学习框架中,DPH-RL的思路可以进一步扩展。通过将divergence保护机制与增量学习相结合,有望解决大模型在持续适应新任务时的知识遗忘问题。
对于安全对齐应用,多样性保护机制也具有重要价值。过度优化的模型往往会产生"模式坍塌",导致回答变得单一和刻板。DPH-RL提供的多样性保护有助于维持模型回答的丰富性和创造性,避免过度约束。
行业影响与实践意义
这项研究对AI行业的实际应用具有深远影响。在企业级大模型部署中,往往需要在特定领域进行微调以适应业务需求。传统RL微调方法虽然能提升特定任务的表现,但常常以牺牲模型通用能力为代价。
DPH-RL方法为解决这一困境提供了可行路径。企业可以在保持模型原有能力的基础上,针对性地优化特定业务场景的表现,实现"专而不窄"的微调效果。
在AI安全领域,多样性保护机制也有助于防止模型产生过于确定性的输出模式,降低模型被恶意引导的风险。通过维持一定程度的回答多样性,模型能够更好地抵抗针对性攻击。

未来研究方向
基于当前研究成果,多个方向值得进一步探索。首先是divergence形式的优化,现有研究主要集中于forward-KL和JS divergence,但可能存在更适合大模型训练的divergence形式。
其次是自适应阈值调整,当前样本划分策略依赖于预设阈值,未来可以研究基于训练动态的自适应划分机制,使方法更具普适性。
在大规模实践方面,需要进一步验证DPH-RL在更大参数模型和更复杂任务上的表现。同时,方法的计算效率和内存消耗也是实际部署中需要重点考虑的因素。
最后,理论分析的深化将有助于更好地理解多样性保护机制的工作原理。从信息论和概率论角度深入分析divergence选择对模型行为的影响,可以为方法改进提供理论指导。
这项研究的重要意义在于,它重新定义了RL微调的目标范式:不再仅仅追求性能指标的提升,而是要在性能与多样性之间寻求最佳平衡。这种范式转变将对未来大模型训练方法的发展产生深远影响。