随着深度学习技术在计算机视觉领域的快速发展,神经网络模型已经在自动驾驶、智能安防、医疗影像分析等关键场景中得到广泛应用。然而,这些高性能模型在安全性方面存在明显隐患,其中对抗样本问题被认为是深度学习系统面临的最重要安全挑战之一。

对抗样本的现实威胁
在现实应用场景中,对抗样本可能带来严重后果。例如,通过在交通标志图像上加入人类几乎无法察觉的微小扰动,自动驾驶系统可能会把"限速标志"误判为"停止标志";在人脸识别系统中,只需在图像中加入细微噪声,就可能使模型将一个人误识别为另一个人。这些微小的输入变化却能导致模型产生完全错误的预测,不仅揭示了深度神经网络在决策边界上的脆弱性,也对现实系统的安全性提出了严峻挑战。
迁移攻击的特殊价值
在众多对抗攻击研究方向中,迁移攻击具有特殊的研究价值。这类攻击不需要访问目标模型的结构、参数或梯度信息,而是通过一个可访问的代理模型生成对抗样本,再利用这些样本攻击其他未知模型。这种攻击方式在现实场景中更具威胁性,因为实际部署的模型通常处于黑盒环境,攻击者难以获得模型的内部信息。
RaPA方法的核心创新
RaPA方法的创新之处在于发现了现有迁移攻击方法存在的关键问题:生成的对抗样本往往过度依赖代理模型中的少量关键参数。实验分析表明,当删除这些最重要的参数时,攻击成功率会出现明显下降,这说明攻击样本在生成过程中对特定参数产生了较强依赖。这种依赖性会导致攻击样本难以适应其他模型结构,从而降低对抗样本在不同模型之间的迁移能力。
针对这一问题,研究团队提出了随机参数剪枝策略。该方法在攻击过程中随机屏蔽模型中的部分参数,使每一次攻击时所使用的模型都会发生变化。由于每一轮攻击都对应不同的模型参数结构,生成的对抗样本需要在不断变化的模型环境中进行优化,因此攻击样本不再依赖某些固定参数,而是能够适应更多不同的模型情况。
实验设计与结果分析
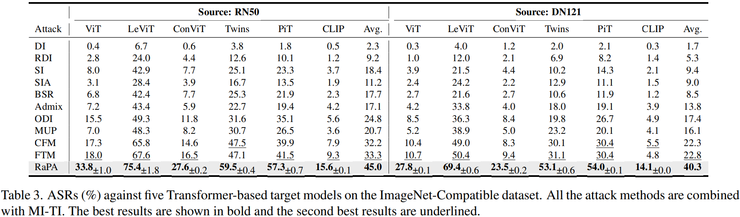
研究团队在ImageNet兼容数据集上进行了全面实验验证。实验使用了多种不同类型的模型,包括经典的卷积神经网络模型(VGG16、ResNet18、ResNet50等)和视觉Transformer模型(ViT、LeViT、ConViT等),还测试了CLIP模型这种结构差异较大的模型。
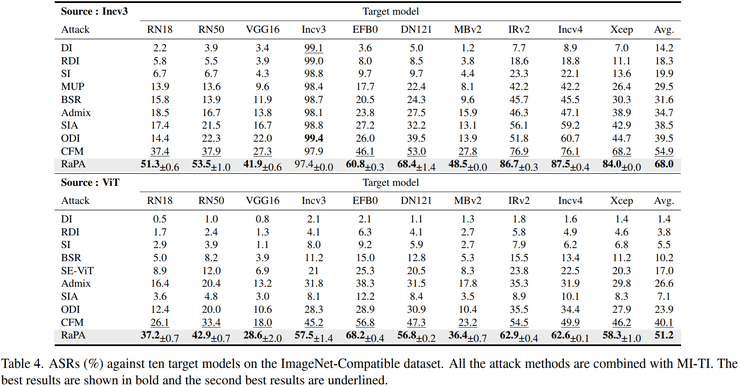
实验结果表明,在跨模型结构攻击任务中,RaPA的优势尤为明显。当使用ResNet50作为攻击模型时,平均攻击成功率提升约11.7%;当使用DenseNet121作为攻击模型时,平均攻击成功率提升约17.5%。这些结果充分证明了RaPA生成的对抗样本具有更强的通用性和迁移能力。
防御机制下的表现
研究人员还在多种防御机制存在的情况下测试了RaPA的攻击效果,包括对抗训练模型、JPEG压缩防御、随机化防御、图像降噪防御以及扩散模型防御。实验结果显示,在所有防御条件下RaPA的攻击成功率仍然保持最高水平。
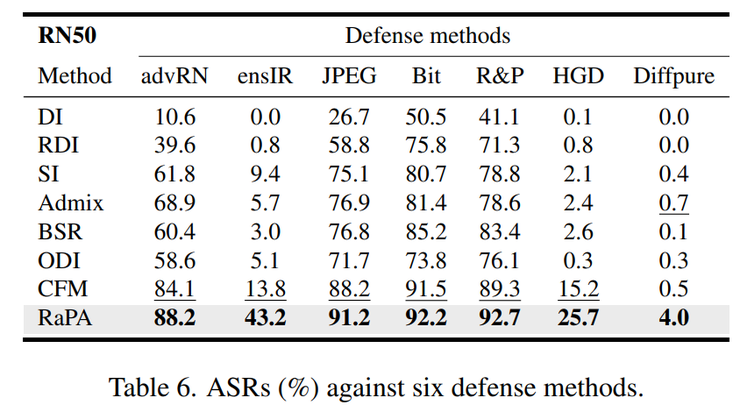
特别值得注意的是,在对抗训练模型上,RaPA的攻击成功率约为88%,明显高于其他攻击方法。这一结果说明,即使目标模型经过专门的安全加固,RaPA仍然能够有效实施攻击,这为模型安全性评估提供了重要参考。
计算资源的影响
研究人员还深入分析了计算资源变化对攻击效果的影响。通过增加攻击迭代次数以及增加每轮计算次数进行实验,结果显示当计算量增加时,其他攻击方法的性能提升幅度较小,而RaPA的性能提升最为明显。
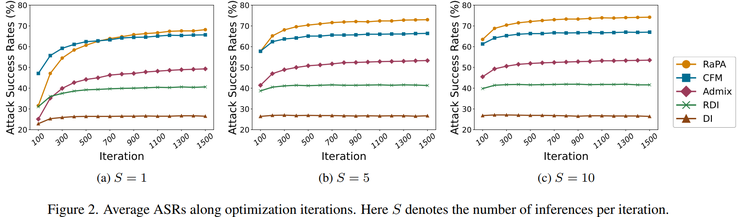
例如在使用ResNet50的情况下,攻击成功率可以额外提升约15.9%。这些结果表明,在更多计算资源支持下,RaPA的攻击效果能够得到进一步增强,这为实际攻击场景中的资源分配提供了指导。
方法实现细节
在具体攻击流程方面,RaPA方法首先以原始图像作为初始输入。随后在每一次攻击迭代过程中,随机选择一部分模型参数并将其暂时关闭,这些参数主要包括全连接层参数以及归一化层参数。通过这种方式,原始模型在每一次迭代中都会产生一个新的模型版本。
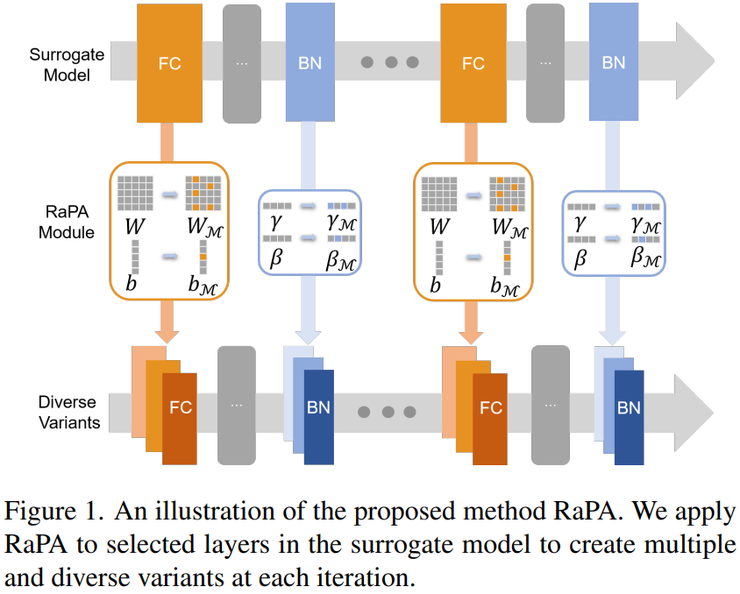
接着在同一次迭代中生成多个不同的随机剪枝模型,也就是说,一个原始模型会被扩展为多个结构略有不同的模型。然后利用这些不同模型分别计算攻击所需的梯度信息。所有模型得到的梯度会被统一进行平均处理。之后根据平均得到的梯度对图像进行更新,从而生成新的对抗样本。整个过程会不断重复多次迭代,直到攻击过程结束并得到最终的对抗样本。
与其他方法的兼容性
RaPA方法的一个重要优势是能够与多种已有攻击技术进行结合使用。研究团队测试了与输入变换类方法(如DI、RDI)、梯度优化类方法(如SI)、特征混合类方法(如Admix、CFM)的结合效果。
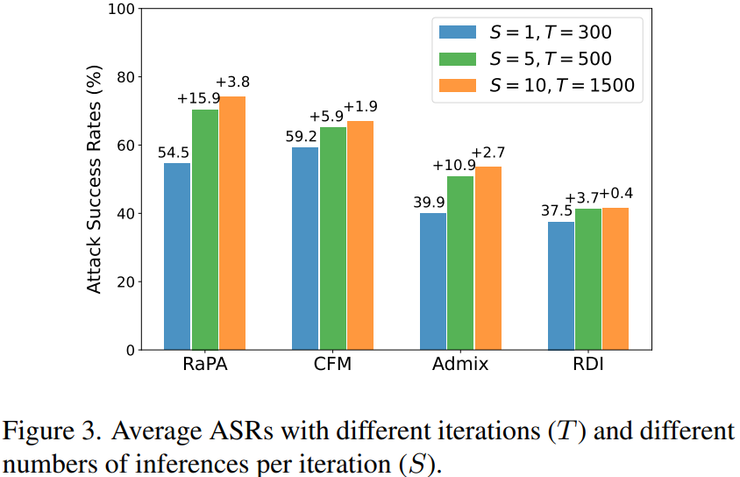
实验结果表明,在这些方法的基础上引入随机参数剪枝策略,可以进一步增强攻击样本的迁移能力,从而获得更好的攻击效果。这种兼容性使得RaPA可以灵活应用于不同的攻击场景,为研究人员提供了更多的技术选择。
理论意义与实践价值
从理论角度来看,RaPA方法揭示了模型参数依赖性问题对对抗样本迁移性的重要影响。这一发现不仅有助于理解深度学习模型的决策机制,也为改进模型鲁棒性提供了新的思路。

从实践价值来看,RaPA方法为模型安全性评估提供了更有效的工具。通过使用这种方法,研究人员可以更准确地评估模型在实际部署环境中的安全性能,及时发现潜在的安全隐患。同时,这种方法也为开发更强大的防御机制提供了重要的参考依据。
未来研究方向
基于RaPA方法的研究成果,未来可以在以下几个方向继续深入探索:首先,可以研究更智能的参数选择策略,而不是完全随机剪枝;其次,可以探索将这种方法应用于其他类型的深度学习模型;最后,可以研究如何将这种攻击方法的原理转化为防御策略,提高模型的鲁棒性。

此外,随着大模型时代的到来,如何将RaPA方法应用于大型语言模型和多模态模型的安全评估,也是一个值得关注的研究方向。这些模型通常具有更复杂的结构和更多的参数,可能面临新的安全挑战。
RaPA方法的提出不仅提升了对抗攻击的技术水平,更重要的是为理解深度学习模型的安全性本质提供了新的视角。这种方法强调了对模型内部参数分布的理解,而不是仅仅关注输入输出的映射关系,这标志着对抗样本研究正在向更深层次发展。