随着大语言模型技术的快速发展,强化学习在后训练阶段的作用机制成为学术界关注的重点。当前业界存在一个重要争议:强化学习究竟是真正教会模型新能力,还是仅仅对模型已有解法进行筛选和重排?清华大学刘知远团队的最新研究通过精心设计的实验环境,为这一争论提供了实证依据。
实验设计的创新之处
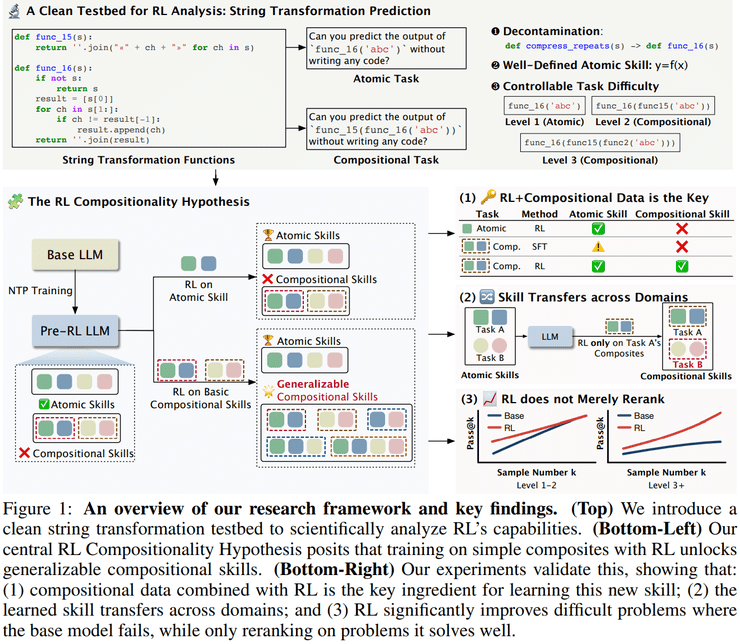
研究团队选择退回到高度可控的实验环境,采用字符串变换函数作为研究载体。这种设计的优势在于能够完全排除自然语言任务中常见的预训练语料污染问题,同时可以对技能难度进行精确控制。所有函数均采用随机命名的无意义字符串,彻底杜绝了模型根据函数名猜测代码逻辑的可能性。

研究将"技能"明确划分为两个层次:原子技能指模型能够正确预测单个函数作用后的输出,而组合技能则要求模型能够推断多层嵌套函数的最终结果。这种清晰的定义使得"新能力"不再是抽象概念,而是可以被精确检验的研究对象。
两阶段训练流程的关键发现
研究采用两阶段训练设计,刻意分离了原子技能掌握和组合技能学习两个过程。第一阶段通过监督学习让模型充分掌握每个字符串变换函数的具体行为,建立稳定的原子技能基础。第二阶段则完全隐藏函数定义,仅向模型提供函数名称和输入字符串。
在强化学习训练阶段,研究人员设计了三种不同的训练数据配置:仅单函数、仅二层嵌套函数、以及单函数与二层嵌套函数混合。测试结果显示出显著差异:仅在单函数上进行强化学习的模型,在三层及以上组合任务上的准确率几乎为零;而包含二层嵌套函数的训练则使模型在三层组合任务上的准确率提升至约30%,在四层组合任务上仍保持约15%的准确率。
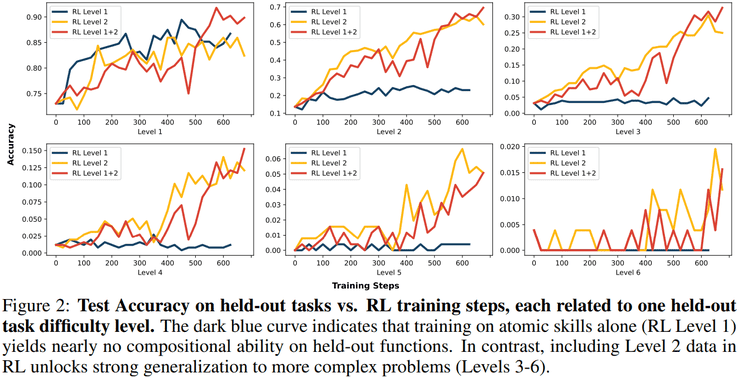
这种随组合深度增加仍能保持性能的现象表明,模型并非依赖偶然猜测或记忆模板,而是学会了一种可递归使用的组合策略。如果强化学习仅仅激活或重排已有推理模式,这种系统性表现是难以解释的。
监督学习与强化学习的对比分析
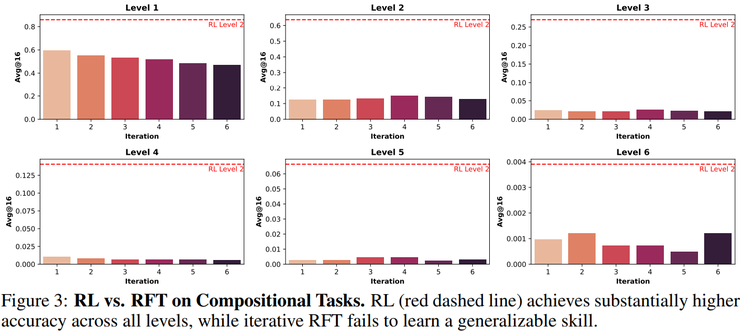
为了进一步验证强化学习的独特作用,研究团队设置了对照实验。在完全相同的二层组合数据上,用监督学习替代强化学习进行训练。结果发现,监督学习模型在三层组合任务上的准确率始终处于极低水平,甚至在相同难度但函数不同的二层组合测试中也表现不稳定。
相比之下,强化学习模型不仅能够稳定解决二层组合问题,还能系统性地外推到更深层的组合任务。这说明真正起关键作用的是强化学习所引入的结果驱动、探索机制与策略更新过程,它们共同促使模型形成新的推理结构。
跨任务泛化能力的实证
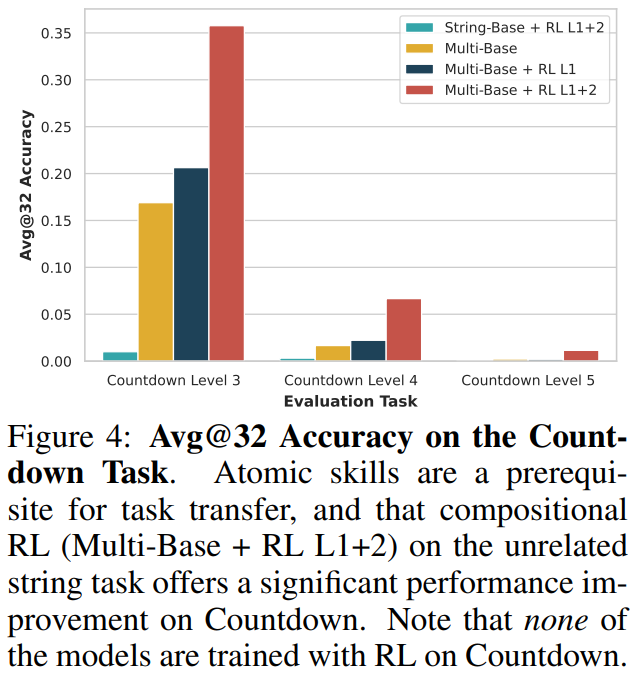
研究还通过跨任务实验验证了组合能力的通用性。如果模型在A、B任务上学习了原子能力,仅在A任务上进行合适的组合能力强化学习,模型就能将该能力泛化至B任务上。实验结果显示,尽管未在Countdown任务上进行强化学习,仅在复合函数输出预测上进行强化学习后的模型在多步Countdown任务上的表现也取得了明显提升。
这表明强化学习获得的并非特定于字符串任务的技巧,而是一种能够组织和调度已有原子技能的通用能力,即一种元技能。然而,这种迁移是有条件的——在其他任务上学到的组合能力并不能泛化到模型不具备原子能力的任务上。
对"强化学习只是重排"观点的回应
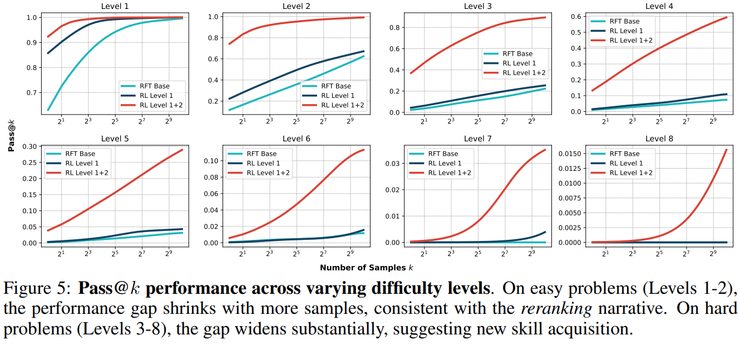
针对"强化学习只是将pass@k压缩为pass@1"的观点,研究人员进一步分析了不同难度任务下的表现差异。在低难度任务上,基础模型本就能够通过多次采样得到正确答案,强化学习的作用确实主要体现为重排。而在高难度组合任务中,基础模型即使在极大采样预算下仍表现不佳,强化学习模型的优势却随着采样数增加而不断扩大。
研究团队据此指出,"强化学习只是重排"的结论在一定程度上是一种评测假象,它忽略了任务难度对模型行为影响的复杂性。
错误类型分析的深层启示
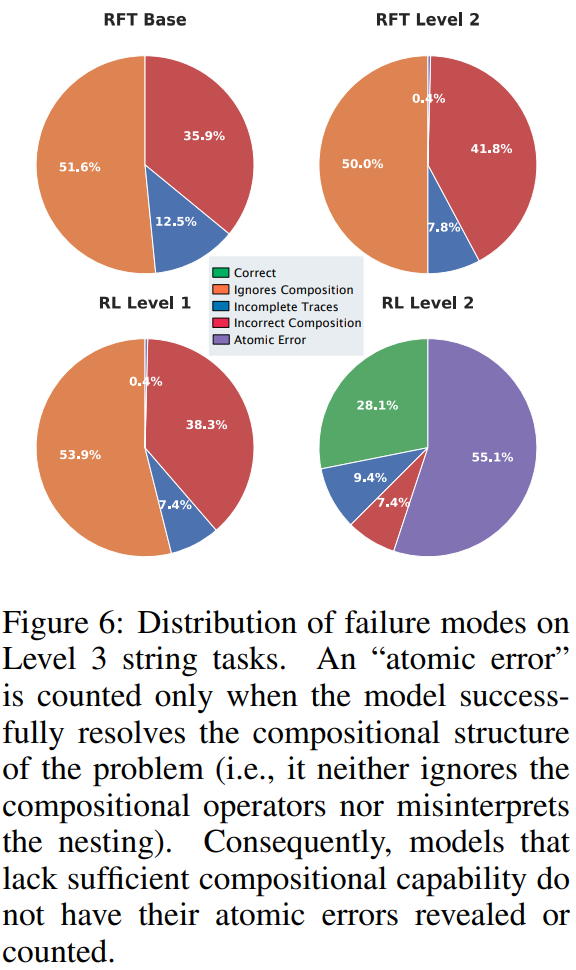
错误类型分析提供了更深入的见解。基础模型、监督学习模型以及仅进行原子强化学习训练的模型,其主要错误来源于忽略组合结构或误解嵌套关系。而经过组合任务强化学习训练的模型,其错误更多来自原子步骤的执行失误,而非对整体组合结构的误解。
这一发现表明,强化学习首先教会模型正确理解和执行组合结构,即使失败,也失败在更低层级。这种错误模式的变化反映出模型认知层面的根本转变,而不仅仅是准确率的提升。
研究方法论的创新价值
这项研究的方法论创新体现在多个方面。首先,它建立了一个高度可控的实验环境,使得"新能力"可以被精确定义和测量。其次,研究采用了两阶段训练设计,清晰分离了不同训练阶段的目标和作用。最后,通过多维度评测方法,包括准确率、pass@k表现、错误类型分析等,构建了完整的证据链。
对实践应用的指导意义
这项研究对大语言模型的实践应用具有重要指导意义。它提示我们,在模型训练流程设计中,应该明确不同训练阶段的分工:预训练或监督微调阶段侧重于建立原子能力基础,而强化学习阶段更适合用于发展组织和调度这些能力的高级技能。
此外,研究结果也为模型能力评估提供了新视角。单纯依赖整体性能指标可能无法全面反映模型能力的真实变化,需要结合错误类型分析等更细致的方法来理解模型行为的本质改变。
未来研究方向展望
基于这项研究的发现,未来有几个值得深入探索的方向。首先是探究组合能力的极限——在什么条件下模型能够学会的组合策略会达到上限?其次是研究不同奖励设计对组合能力学习的影响,如何设计更有效的奖励信号来促进复杂能力的形成?最后是将这种严格可控环境下的发现推广到更复杂的自然语言任务中,验证其普适性。
这项研究不仅回答了强化学习是否能够教会大模型新能力的问题,更重要的是为理解大模型能力形成机制提供了新的分析框架和方法论工具。它标志着大语言模型研究正在从简单的性能提升转向对能力构建机制的深入探索,这一转变将对未来模型设计和训练实践产生深远影响。