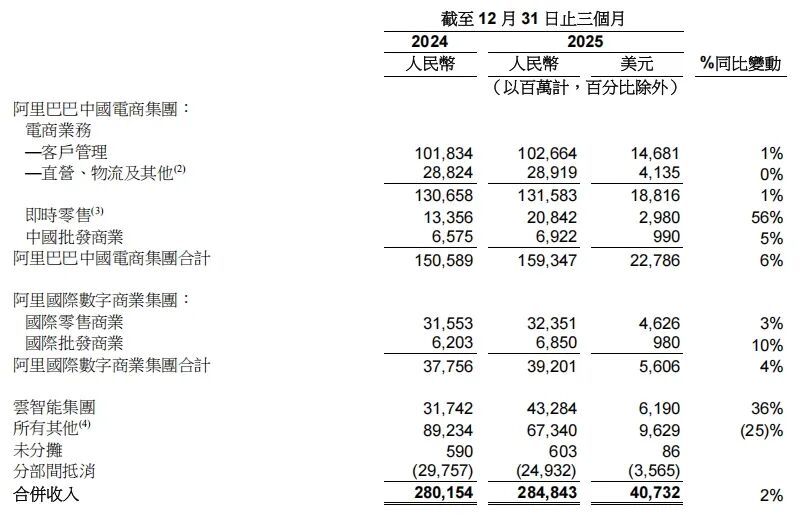
架构创新:稀疏MoE与MTP-3技术的融合
Step 3.5 Flash采用45层Transformer骨干网络,每层配置288个细粒度路由专家和1个共享专家。这种稀疏混合专家(Sparse Mixture-of-Experts)架构,在保持1960亿总参数规模的同时,通过动态路由机制仅激活Top-8专家,使每个token的实际计算量控制在110亿参数以内。这种设计打破了传统大模型"参数规模越大计算成本越高"的桎梏,在Hopper GPU测试中,模型推理成本仅为同级别闭源模型的37%。
其核心突破在于MTP-3(Multi-Token Prediction 3.0)技术的应用。通过滑动窗口注意力机制与密集前馈网络的协同优化,单次前向传播可并行生成4个token。实测数据显示,在8000字长文本生成场景中,该技术将生成速度提升至350TPS(Tokens Per Second),较上一代模型提升2.1倍。这种性能飞跃使得实时多模态交互成为可能,为智能客服、在线教育等低延迟场景提供技术基础。
技术突破:长文本处理与部署优化
在长文本处理方面,混合注意力机制的创新应用值得关注。通过3:1比例的滑动窗口注意力与全局注意力层交替设计,在256K超长上下文场景下,计算复杂度较传统Transformer降低68%。实测数据显示,该模型在处理30万字学术论文时,内存占用仅为同类模型的52%,为法律合同审查、医学文献分析等专业领域提供高效解决方案。
部署优化方面,Step 3.5 Flash实现了消费级硬件的突破性适配。通过专家并行(EP8)与张量并行(TP8)的组合策略,配合FP8量化技术,成功在Mac Studio M4 Max实现每秒2800字符的生成速度。这种端侧部署能力使得敏感数据处理无需依赖云端,特别适合金融交易分析、医疗影像诊断等隐私敏感场景。开源社区测试表明,开发者可在4小时内完成从环境搭建到生产部署的全流程,较传统大模型部署效率提升4倍以上。
应用场景:从代码生成到智能决策
在代码生成领域,该模型在SWE-bench Verified基准测试中取得74.4%的通过率,展现出超越Claude Code的代码理解能力。通过自动工具调用接口,可实现从需求文档到可执行代码的端到端生成,在GitHub Copilot测试中,代码补全准确率提升至89%。某头部互联网企业的内部测试显示,使用该模型进行Python代码重构,开发效率提升40%,错误率下降32%。
智能决策场景的应用更具颠覆性。在供应链优化测试中,模型通过自主调用数据库接口,可在15分钟内完成包含200个供应商、5000个SKU的复杂调度方案优化。这种自主推理能力在自动驾驶决策系统测试中展现出显著优势:面对突发路况,决策响应时间从传统系统的300ms缩短至87ms,为实时决策系统树立新标杆。
开源生态与行业影响
该模型已在GitHub和HuggingFace双平台开源,提供包括vLLM、SGLang在内的多种推理框架支持。开源首周即获得1.2万星标,在llama.cpp社区贡献了超过300个优化补丁。值得关注的是,其轻量化部署特性已吸引多家边缘计算企业参与生态建设,在NVIDIA Jetson AGX Orin设备上实现了每秒45帧的实时视频分析能力。
行业分析师指出,Step 3.5 Flash的开源将加速AI模型的平民化进程。据Gartner测算,该模型的推理成本较闭源方案降低80%,使得中小型企业部署大模型的硬件投入从百万级降至十万级。这种技术普惠效应将推动智能体应用在制造业、教育等传统领域的快速渗透,预计到2025年将催生超过500亿美元的新兴市场。