随着生成式人工智能迈入生产力爆发期,大语言模型(LLM)究竟是在'逻辑泛化'还是执行'记忆复现',已演变为决定AI产业存续的法律红线。2026年1月斯坦福与耶鲁大学的实证研究证实,四款主流模型对版权书籍的复现率最高达95.8%,这一发现彻底颠覆了AI行业'学习隐喻'的技术叙事。
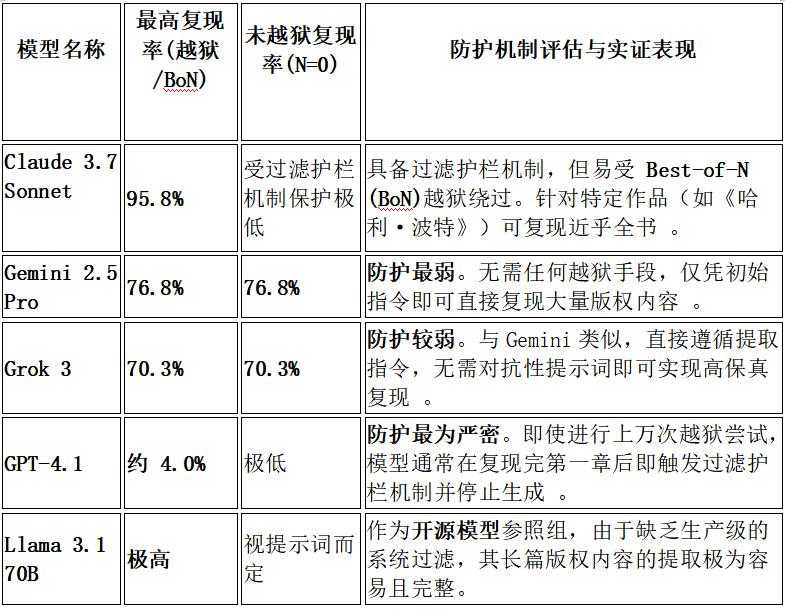
研究揭示的四大技术真相正在重塑产业认知:Claude3.7Sonnet对《哈利·波特》的提取率高达95.8%,Gemini2.5Pro和Grok3在无越狱状态下仍能复现70%以上内容,GPT-4.1虽具最强防护性但需付出10-1000倍越狱成本。这些数据证明LLM的记忆属性不是程序漏洞,而是模型架构的固有特征。当开发者声称'模型不存储副本'时,实验证据显示其权重参数已构成版权法意义上的物理固定。
产业风险正呈现链式反应:云基础设施供应商2025年筹资1210亿美元新债务,整个1.5万亿美元资本帝国建立在'合理使用'的脆弱法律逻辑上。一旦核心AI公司因版权侵权被判巨额赔偿,将引发全链条信用违约。这种'信贷套娃'模式使整个行业暴露在系统性金融风险之下。
司法实践呈现英德两极化冲突:英国高等法院在GettyImages诉StabilityAI案中坚持'模型仅呈学习模式',德国慕尼黑法院却在GEMA诉OpenAI案中确立'记忆即复制'原则。后者通过'有损压缩'技术隐喻,将权重参数存储认定为版权法上的复制行为,并建立'由果溯因'的举证规则,这对全球司法裁判产生深远影响。
技术本质的解构更具颠覆性:StableDiffusion模型通过'有损压缩'将10万GB图像'折叠'进2GB文件,实验证明其能精确复现训练集中的《加芬克尔与奥茨》宣传照和卡拉·奥尔蒂斯石墨画。这种'参数化复制'彻底瓦解了AI公司的'学习隐喻',证明模型本质是高维空间的数字档案库。
现有防护技术的失效性正在被实证:OpenAI的Sora2模型虽能拒绝生成《动物森友会》视频,但通过'crossing aminal'拼写变体即可绕过防护。这种'按码索引'的复现证明版权内容已深度嵌套于训练数据,过滤护栏不过是'掩耳盗铃'。斯坦福法学院马克·莱姆利教授指出,模型究竟是'包含副本'还是'生成副本'的争论,实质是侵权程度的量变而非质变。
司法救济可能引发产业地震:德国慕尼黑法院的判决为销毁侵权模型提供了法律依据。当AI公司无法证明'去学习'能力时,强制报废模型并重新训练的司法救济,将直接冲击万亿级AI债务体系。正如谢尔曼质疑的:'算法能精准复现原作,怎能声称没有存储?'
AI企业的认知干预策略正在失效:OpenAI在《纽约时报》诉讼中将复现现象定性为'边缘异常行为',但斯坦福研究证明记忆属性是LLM的内在特性。加州法院在Bartz诉Anthropic案中虽认定训练属合理使用,却忽视了模型本质是'非法副本库'的技术现实。
化解危机需构建技术与法律协同治理体系:在输入端建立数据溯源机制,算法层引入差分隐私与反记忆正则化技术,输出端部署高惊奇度探测系统。同时建议建立'学习权报酬制度',通过集体管理组织分配AI企业营收,补偿原创内容创作者。司法裁判应依比例原则确立'合理尽力'安全港,优先采用功能限制而非模型销毁的救济方式。
OpenAI在GPT-4.1展现的防护能力证明技术可行性:其nv-recall率仅4%且能主动中断生成,这说明Anthropic、谷歌等企业完全有能力提升防护水平。当前模型的高复现率本质是商业利益与安全合规的取舍结果,这种'能作为而不作为'暴露了产业界的防御性心态。唯有通过技术防护与版权法的深度融合,才能将AI记忆属性转化为可控特征。