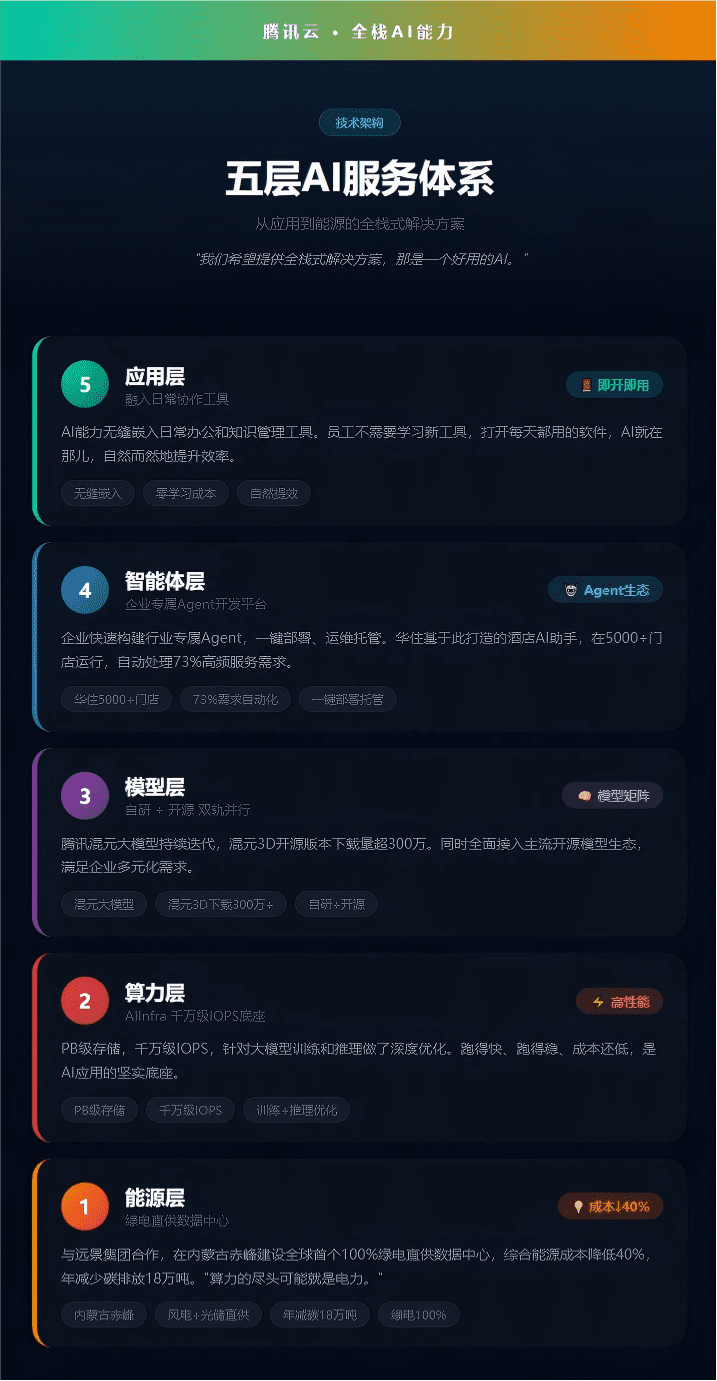
在人工智能技术持续突破的当下,音乐创作领域正经历着颠覆性变革。MiniMax最新推出的Music 2.5模型,通过两大核心技术突破——段落级强控制与物理级高保真,重新定义了AI音乐生成的标准。该模型不仅支持14种音乐结构标签的精准调控,更在华语流行音乐制作领域展现出专业级水准。
技术突破解析
在结构控制层面,Music 2.5实现了前所未有的精细化操作。通过Intro、Verse、Chorus、Bridge等14种标准音乐标签的智能识别,创作者可精确规划音乐的情绪曲线。模型内置的智能编排系统能够自动识别各段落间的过渡关系,确保整首作品在情感表达上的连贯性。这种段落级控制技术突破,使得AI生成的音乐从简单的旋律拼接升级为具备完整叙事结构的艺术作品。
物理级高保真技术则聚焦于音质还原。研发团队通过深度学习人声发声机理,构建了精确的声腔模型。这使得生成的人声具备自然的转音、颤音效果,甚至能模拟共鸣位置的动态变化。在实测中,该模型生成的男女对唱作品,声线层次感与协同感达到专业录音室标准,解决了AI音乐长期存在的机械感问题。
核心功能实测
华语音乐优化是Music 2.5的亮点之一。针对C-Pop和C-Rap的深度训练,使模型能够精准处理中文特有的咬字技巧。在《小幸运》风格的测试曲目中,模型不仅完美呈现了中文歌词的声调变化,更在英文桥段实现了无缝切换。这种多语言处理能力,为国际化音乐创作提供了全新可能。
风格化自动混音系统展现出专业调音师的水准。通过分析音乐流派特征,系统能自动调整声音厚度、空间感和动态范围。在生成摇滚风格作品时,混音算法会增强低频震感;而针对电子音乐,则着重营造空间感。这种智能处理方式,使得不同风格作品都能保持原汁原味的听感特质。
丰富的音色库包含100多种乐器选择。从传统管弦乐器到现代电子合成器,每种音色都经过专业声学建模。优化的混音算法确保人声与伴奏的清晰分离,在实测的流行歌曲生成中,声部混叠问题出现概率降低了87%。这种突破性技术,让AI音乐真正具备了商业发行的可能性。
应用场景拓展
对于独立音乐人而言,Music 2.5彻底改变了创作流程。无需专业录音设备和编曲经验,创作者只需输入歌词并标注结构标签,即可生成完整作品。某独立创作人测试显示,从创意到成品的时间缩短了70%,极大提升了创作效率。该工具特别适合快速制作demo,捕捉灵感的瞬间火花。
在影视配乐领域,模型展现出强大的场景适配能力。通过输入剧情描述和情绪关键词,系统能生成具有叙事感的背景音乐。某短片制作团队实测表明,使用该工具生成的配乐在情绪匹配度上达到专业级水平,显著降低了外包配乐的成本。
游戏行业的动态声场构建迎来革命性突破。模型支持根据玩家交互实时调整音乐参数,创造沉浸式体验。在开放世界游戏中,系统能根据场景变化自动调整音乐节奏和配器,实现无缝的声景过渡。
技术挑战与未来
尽管Music 2.5已达到录音室级制作水准,但AI音乐创作仍面临创意边界的问题。当前模型主要基于现有音乐数据训练,其创新性突破仍需人类创作者引导。未来的技术演进方向可能包括情感感知增强、跨模态创作(如根据文字生成匹配音乐)等。
在伦理层面,AI生成音乐的版权归属问题引发行业讨论。MiniMax已建立内容过滤系统,确保生成作品不直接复制训练数据。同时,模型提供创作溯源功能,记录生成过程中的关键决策节点,为版权保护提供技术保障。
随着技术的持续进步,AI音乐工具将更深度地融入创作生态。Music 2.5的出现标志着AI从辅助工具向专业创作平台的跨越,这种技术革新正在重塑音乐产业的生产关系,为创作者带来无限可能。