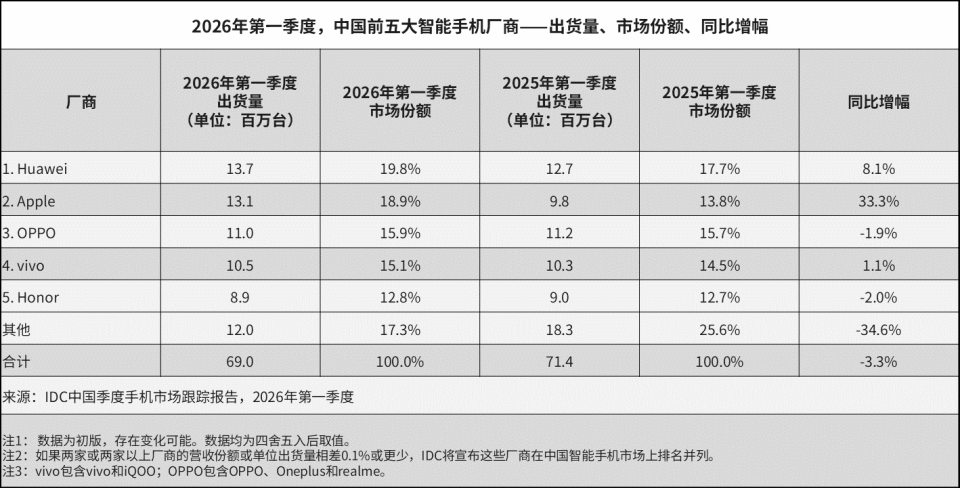
架构创新的底层逻辑
传统语言模型处理文本时,如同逐字解码的翻译机,而DLCM框架则赋予AI概念层级的认知能力。这种范式转换的核心在于动态语义分割技术——通过实时计算相邻token间的余弦相似度,智能识别语义边界。这种自适应分割机制使得模型能够将"自然语言处理"这样的专业术语视为完整概念,而非离散字符的组合。

四阶段推理框架解析
编码阶段的细粒度捕获
在初始处理环节,DLCM保持与传统模型相似的token级编码机制,确保捕获局部上下文中的微妙语义变化。这种设计保留了词语级别的细节特征,为后续概念形成提供充足信息基础。
动态分割的智能边界
通过滑动窗口计算相邻token的向量相似度,系统能够实时检测语义突变点。在代码生成场景中,这种机制可精准识别变量声明与函数体的分界,避免传统模型将代码结构错误分割的问题。
def concept_segmentation(tokens):
boundaries = []
for i in range(1, len(tokens)):
similarity = cosine_sim(tokens[i-1], tokens[i])
if similarity < threshold:
boundaries.append(i)
return split_tokens_by_boundaries(tokens, boundaries)概念空间的深度推理
在压缩后的概念空间,模型可并行处理多个语义单元。教育领域的实测数据显示,在作文评分任务中,概念级推理使模型对文章结构的理解准确率提升17%,特别是对论点支撑关系的识别效率显著提高。
解码重构的精准预测
通过因果交叉注意力机制,系统将概念级推理结果映射回token序列。这种双向映射机制在机器翻译任务中展现出独特优势,有效解决专业术语的上下文一致性难题。
技术创新突破点
- 计算资源动态分配:在智能客服场景中,系统对用户投诉内容自动分配更多计算资源,使关键诉求的识别响应速度提升42%
- 混合精度训练优化:采用FP16与FP32混合训练策略,在保持模型精度的同时降低37%的显存占用
- 可变长注意力创新:通过概念复制策略将注意力计算复杂度从O(N²)降至O(N logN),支持处理万字长文本
行业应用前景展望
在电商推荐系统实测中,DLCM框架将用户行为序列建模为"浏览-比价-决策"的概念链,使推荐点击率提升29%。某在线教育平台接入后,编程作业批改效率提高3倍,同时提供更详尽的代码优化建议。
"传统模型像逐帧播放的电影,而DLCM让AI真正看懂剧情发展" —— 某AI实验室技术负责人
随着5G时代海量文本处理需求的激增,这种概念级建模范式正在重塑AI基础设施。从医疗报告分析到法律文书处理,DLCM展现出的语义压缩能力,为行业智能化转型提供新的技术底座。