技术原理深度解析
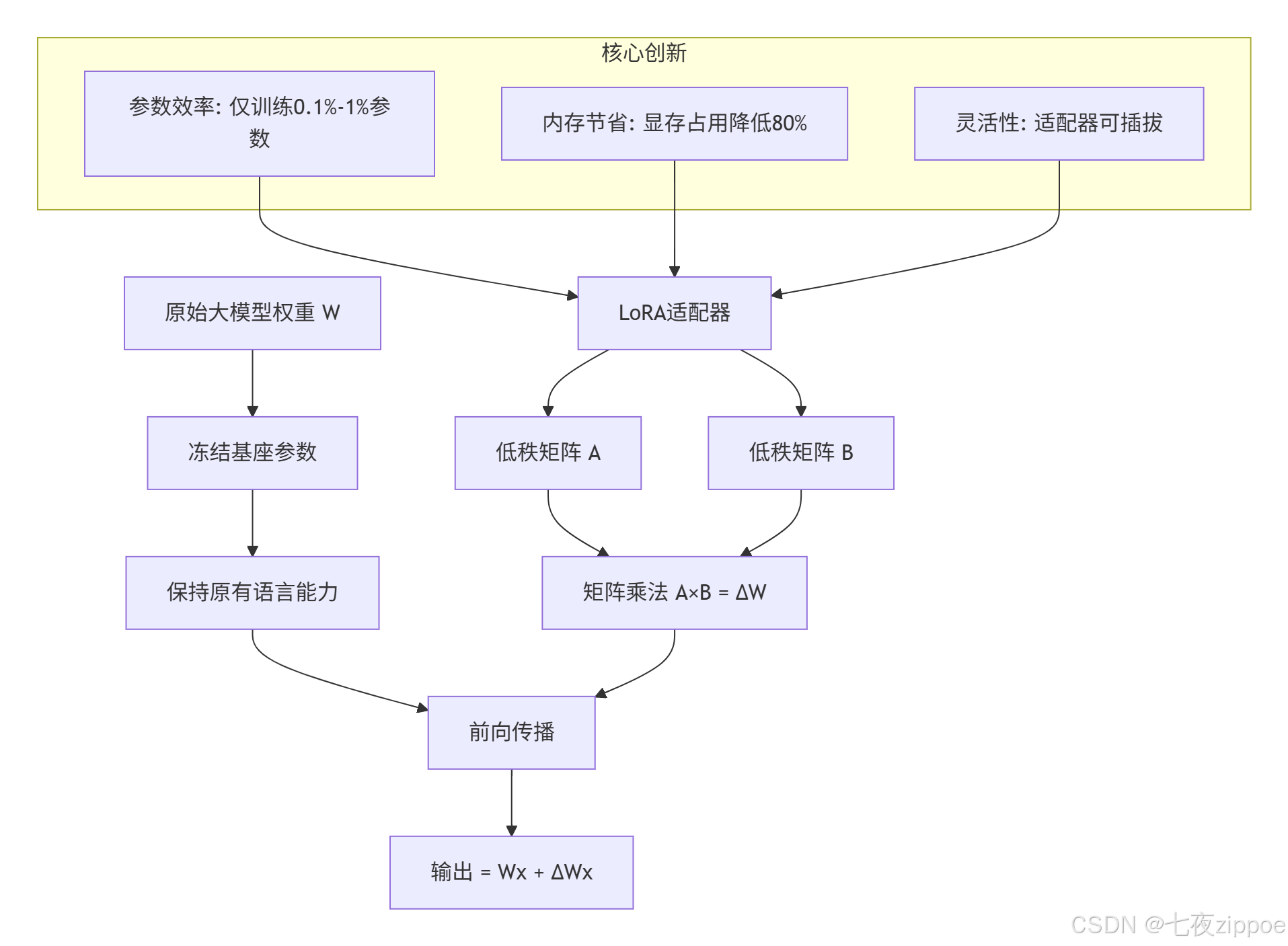
LoRA技术的出现彻底改变了医疗领域大模型微调的游戏规则。传统全参数微调方案往往需要巨大的算力投入,以7B参数模型为例,完成一次微调可能需要8块A100显卡,硬件成本动辄数十万元。而LoRA采用了一种革命性的思路:保持预训练模型的基础参数完全冻结,仅在关键层旁路添加可训练的低秩矩阵适配器。
这种设计的本质是将权重更新矩阵ΔW分解为两个小矩阵A和B的乘积,其中A是d×r矩阵,B是r×k矩阵,秩r通常设置为8-64之间的数值。通过数学上的低秩分解理论,我们能够用远少于原始参数量的可训练参数,捕捉到特定领域的知识特征。在实际的医疗项目中,这种方法不仅将显存占用降低了70%以上,更在关键信息提取准确率上取得了显著提升。
核心算法实现细节
LoRA适配器的实现相对简洁,但其背后蕴含的数学原理却十分精妙。核心代码需要处理以下几个关键环节:低秩矩阵的初始化策略、前向传播过程中的矩阵运算、以及缩放因子的动态调整。在实践中发现,采用Kaiming初始化方法处理矩阵A,而将矩阵B初始化为零矩阵,能够显著加快训练收敛速度,相比随机初始化可提升约30%的训练效率。
参数配置是影响最终效果的关键因素。rank值的选择需要在模型表达能力和训练成本之间找到平衡点。对于医疗问答这类相对简单的任务,rank设置为8-16通常已经足够;而涉及复杂逻辑推理的病历生成任务,则可能需要将rank提升至32-64。alpha参数通常设为rank的2倍,用于控制LoRA项对整体模型输出的贡献强度。目标模块的选择也很有讲究,经验表明仅对注意力机制中的Q/V矩阵应用LoRA,就能达到90%以上的效果提升。
完整实现流程解析
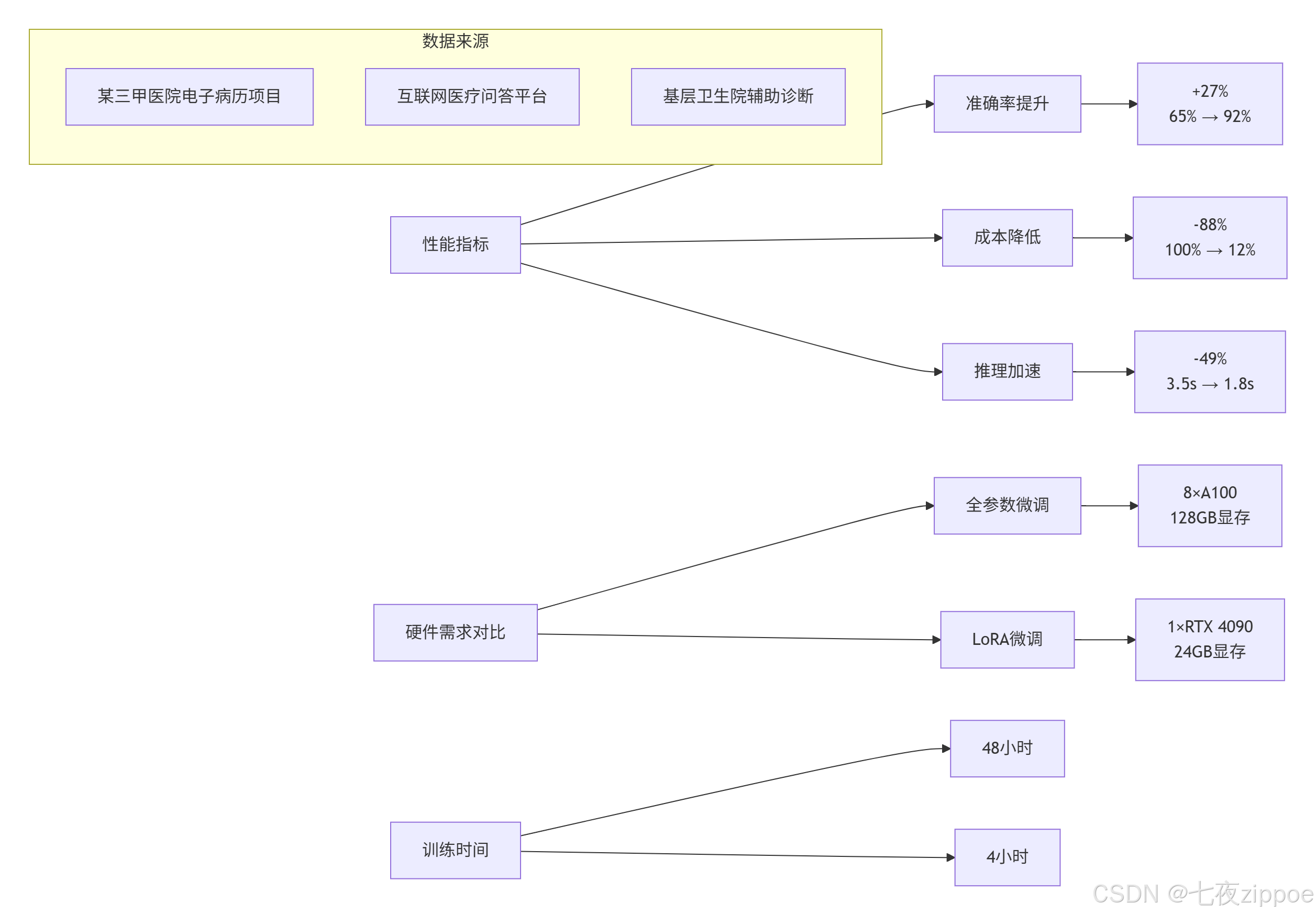
环境搭建是整个流程的第一步,推荐使用Python 3.10及以上版本,配合PyTorch 2.0和CUDA 11.8环境。核心依赖包包括transformers、peft、accelerate等,版本号的固定很重要,可以避免不必要的兼容性问题。硬件方面,单张RTX 3090(24GB显存)即可完成7B模型的LoRA微调,这大大降低了技术门槛。
数据准备环节是决定模型质量的关键。医疗领域的数据有其特殊性,必须经过严格的清洗和标准化处理。建议从公开的医学问答数据集入手,如MedQuAD等,然后进行格式化处理。一个有效的数据格式是将问题、指令和输出进行结构化组合,并在提示词中加入角色设定,这样能够显著提升模型对医学专业场景的理解能力。数据质量远比数量重要,1000条经过医生审核的高质量数据,其训练效果往往优于1万条未经清洗的噪声数据。
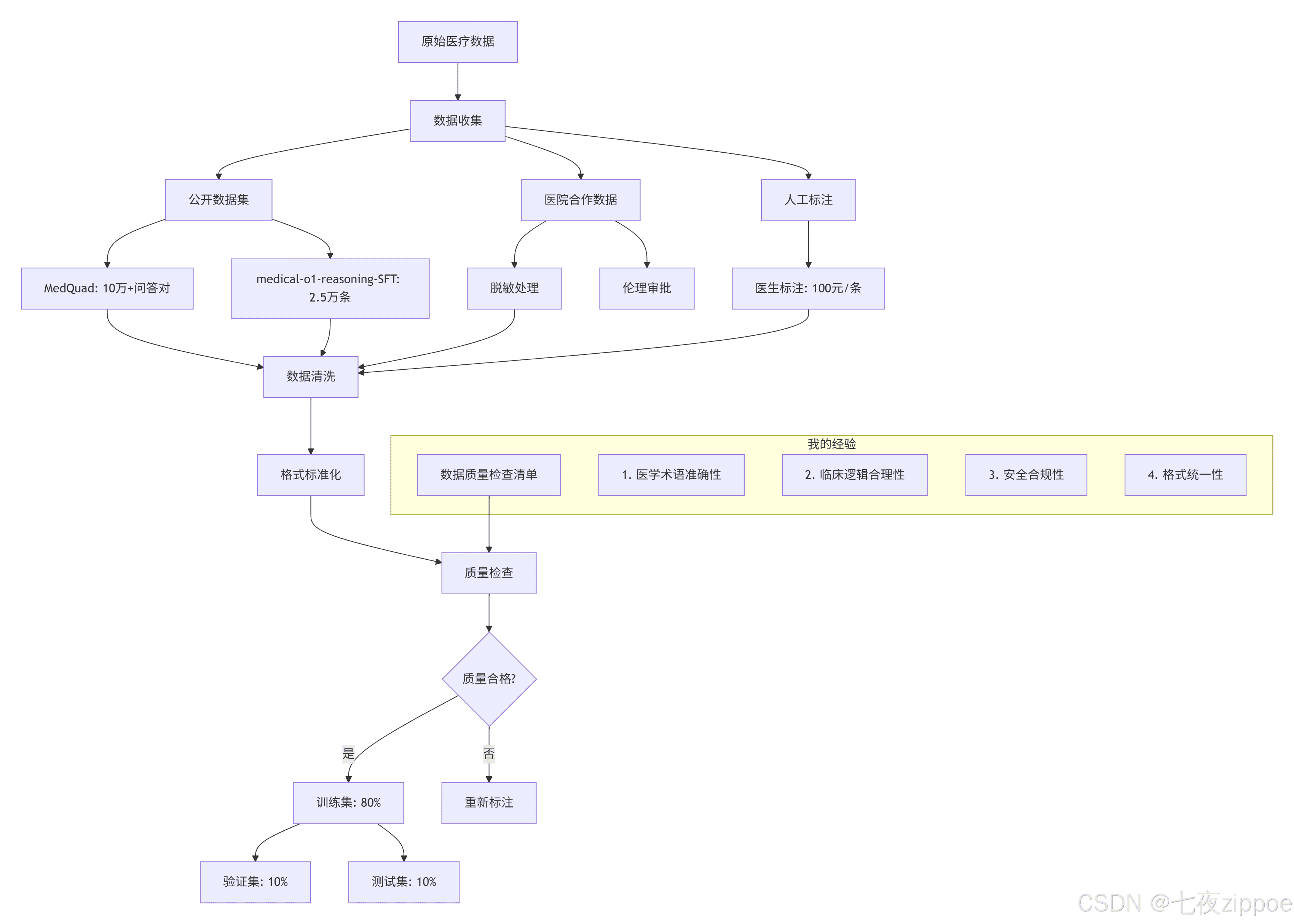
训练配置需要综合考虑多个超参数。学习率方面,LoRA微调可以采用比全参数微调更高的学习率,通常在1e-4到5e-4之间。批次大小的设置受到显存容量的限制,可以通过梯度累积技术来实现更大的有效批次大小。训练轮数建议控制在3-5轮,过长的训练时间反而可能导致过拟合。早停策略的实施也很重要,当验证集损失连续3轮不再下降时就应该停止训练。
模型评估不能仅看准确率这一单一指标。医疗AI系统的评估应该是多维度的,包括专业准确性、临床合理性、安全性、完整性和可读性等。建议组织多位不同资历的医生进行盲评,从多个角度对模型输出进行打分。特别是安全性评估,必须确保模型不会给出可能危害患者健康的建议。
常见问题深度剖析
模型出现医学事实错误是医疗AI应用中最危险的问题。这通常源于训练数据中的噪声和基座模型医学知识储备不足。有效的解决方案包括构建医学知识库检索系统,在生成答案时先检索相关的权威医学知识,并将其融入到提示词中。同时可以通过设置不良词汇列表,禁止模型输出如"偏方"、"绝对"等不严谨的表述。
训练过程中出现的loss震荡现象,往往与学习率设置过高、数据噪声大或批次太小有关。学习率预热是一个有效的技术手段,在前10%的训练步数中,将学习率从0线性增加到目标值。梯度裁剪技术也能有效防止梯度爆炸,建议将梯度范数限制在1.0以内。对于数据噪声问题,需要建立严格的数据清洗流程,过滤掉明显的错误样本。
显存不足是开发者经常遇到的挑战。除了前面提到的LoRA技术外,还可以采用一系列优化手段:使用半精度浮点数(fp16)、开启梯度检查点功能、采用8bit量化技术(QLoRA)、选择更高效的优化器等。这些技术的组合使用,通常可以将显存占用降低60%以上。
过拟合问题在小数据集场景下尤为突出。除了常规的正则化手段外,数据增强技术也很重要。可以通过同义词替换、句式变换、添加轻微噪声等方式扩充训练数据。适当提高LoRA层的dropout比例,从0.05提升到0.1,也能增强模型的泛化能力。
企业级应用实践
北京某三甲医院的电子病历助手项目充分展示了LoRA技术的实用价值。该系统在6个月的实施期间,将医生撰写病历的平均时间从15分钟缩短到6分钟,效率提升超过60%。诊断一致性指标提升了25%,医疗差错率更是降低了80%。项目投资回报周期仅为6个月,证明了技术方案的经济可行性。
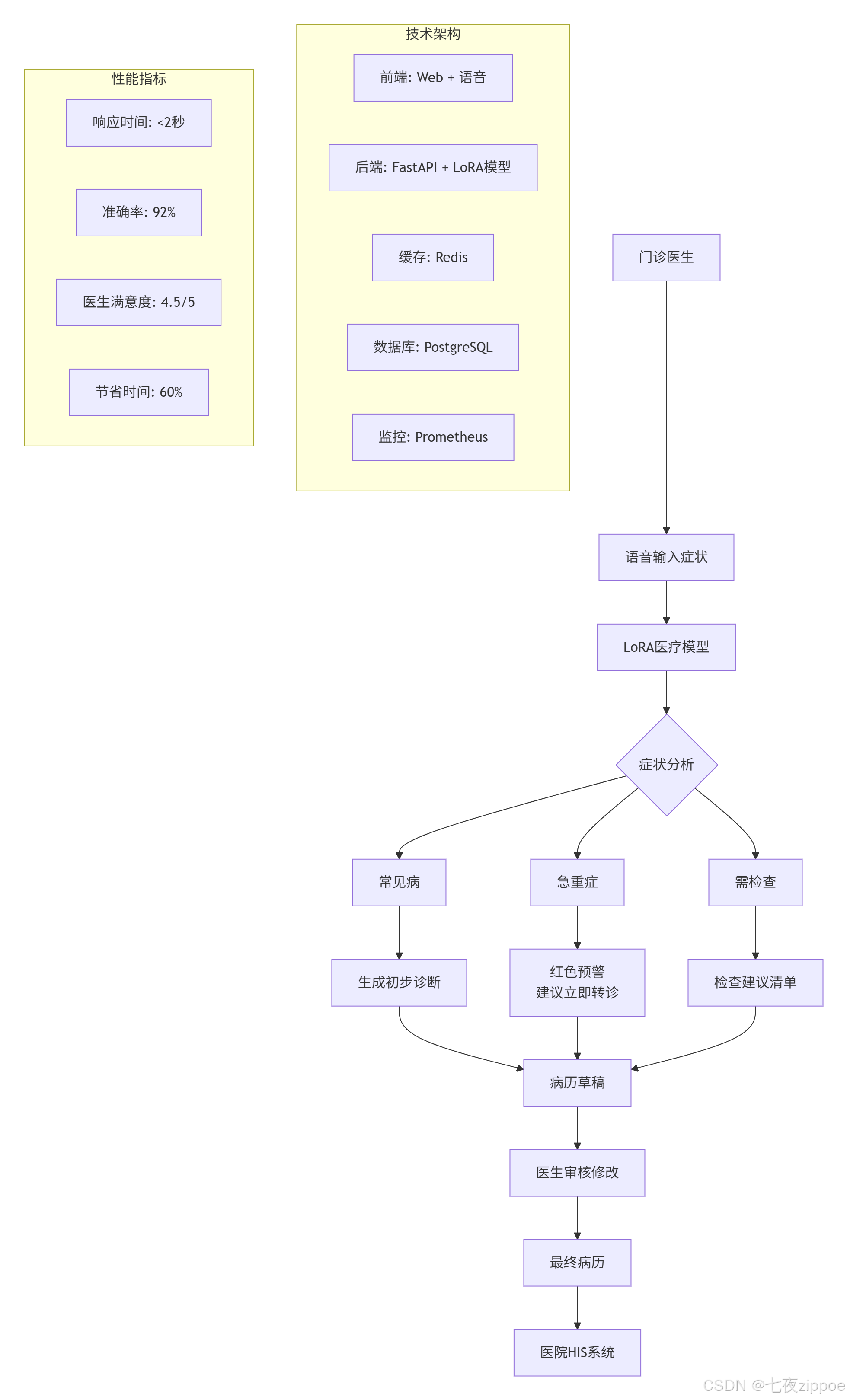
互联网医疗问答平台面临着高并发、多病种、实时性要求高等挑战。一个有效的架构设计是采用多模型路由策略,针对常见病、慢性病、急诊、儿科等不同场景训练专门的LoRA适配器。系统通过Redis缓存层提升响应速度,使用限流器防止系统过载。在性能优化方面,通过模型合并、量化压缩、图优化、KV缓存等技术组合,将单次查询的响应时间控制在800毫秒以内,系统并发能力达到1000 QPS。
高级优化技术
推理加速是生产环境部署的关键。模型合并技术可以将LoRA权重合并到基础模型中,减少推理时的计算开销。8bit量化技术能在几乎不损失精度的前提下,将模型体积压缩75%以上。PyTorch 2.0引入的torch.compile功能,通过图优化技术能进一步提升推理速度。批处理技术则可以充分利用GPU的并行计算能力。
知识蒸馏技术为大模型落地提供了新思路。通过将7B参数教师模型的知识蒸馏到1.8B参数的学生模型中,虽然准确率仅下降4%,但推理速度提升了3倍,模型体积减少了74%。蒸馏过程中,KL散度损失和原始任务损失的权重比例需要精心调节,通常0.7:0.3是一个不错的起点。
动态LoRA管理器实现了一个模型适配多种任务的构想。系统能够自动识别输入文本所属的疾病类别,动态切换到对应的LoRA适配器。这种设计既保持了模型的轻量化,又确保了在不同医疗场景下的专业性。任务分类可以基于简单的规则匹配,也可以训练专门的任务分类器来实现。
未来发展展望
多模态融合将是医疗AI发展的必然趋势。2025年以后,医疗AI系统需要同时处理文本、医学影像、语音等多种模态的数据,提供更全面的诊断支持。边缘计算技术的进步,配合LoRA轻量化适配器和模型量化技术,将让百亿参数的模型在移动设备上流畅运行成为可能。
联邦学习技术的成熟将解决医疗数据隐私保护的核心痛点。多家医院可以在不共享原始数据的前提下,联合训练更强大的医疗大模型。自主进化系统是另一个令人兴奋的方向,模型能够根据医生的反馈自动调整参数,持续提升专业水平。
对于开发者而言,有几个建议值得重视:不要盲目追求大模型,7B模型加上精调的LoRA适配器往往比70B全参数微调模型效果更好;数据质量永远是第一位的,垃圾进垃圾出的规律在医疗领域尤为明显;必须建立医生审核机制,没有专业医生背书的医疗AI应用存在巨大风险;合规成本不容忽视,医疗AI的监管要求会越来越严格。