最近几周,一个有趣的现象在全球AI开发者社区中悄然兴起:海外开发者开始研究如何注册中国的支付工具,特别是支付宝和微信支付。这一看似与AI技术无关的行为,实际上源于智谱AI旗下GLM Coding Plan的定价差异——同样的服务,中国用户享受的价格远低于海外市场。
定价差异引发的全球现象
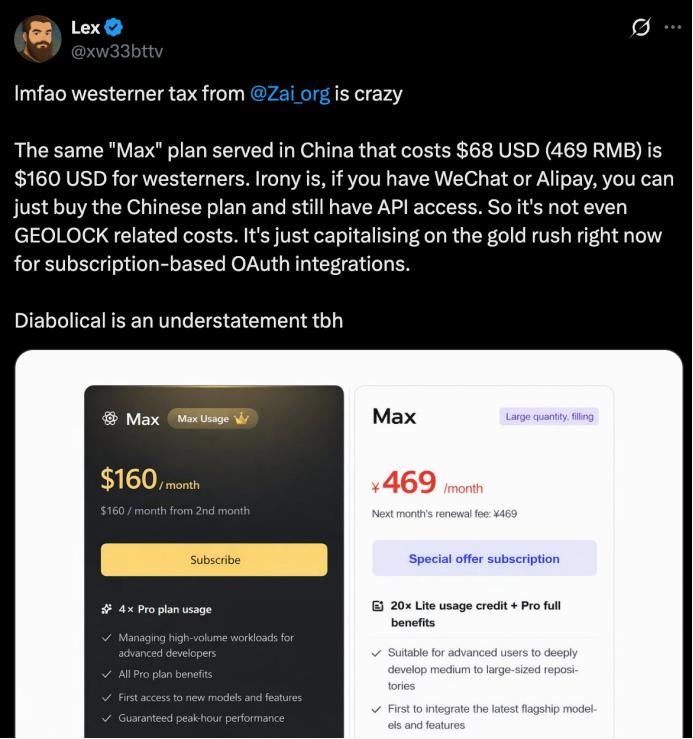
智谱GLM Coding Plan作为国内较早推出的AI编码订阅服务,其定价策略在2026年引发了广泛关注。该服务提供Lite、Pro、Max三个档位,国内版月费分别为49元、149元和469元。然而,海外用户看到的却是另一番景象:单月计费模式下,相应档位的价格分别为18美元、72美元和160美元。
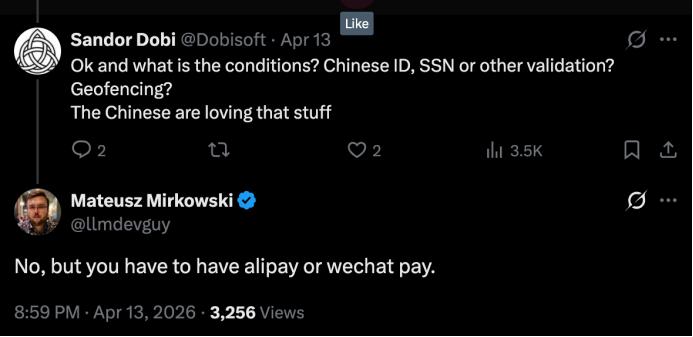
这种价格差异意味着,换算成人民币后,海外用户需要支付相当于国内价格2-3倍的费用。值得注意的是,尽管价格存在显著差异,但服务配额却保持一致——每个档位都提供相同的prompt调用次数。这种"同质不同价"的现象自然引发了海外用户的不满,有人甚至戏称这是在支付"护照税"。
配额机制的演变与优化
智谱在2026年2月对Coding Plan进行了重要调整,不仅提高了价格,还相应减少了配额。Lite档从每5小时120次降至80次,Pro从600次降至400次,Max从2400次降至1600次。这种调整反映了AI服务提供商在平衡用户体验与运营成本方面的考量。
平台采用的双层额度机制值得关注:一层是短周期配额(每5小时刷新),另一层是周度总上限。调整后,周度上限按照"5小时额度的4倍"重新计算,这意味着用户需要更合理地规划使用频率。GitHub知名作者Jeegec对此有一个形象的比喻:"在智谱你每周只工作4天,每天5小时;在Moonshot要工作5天;而在字节跳动和阿里巴巴的计划里要工作7.5天。"
全球开发者的应对策略
面对价格差异,海外开发者展现了惊人的适应能力。博客作者Levi分享了自己的经历:"当我兴致勃勃地准备开通GLM Coding Plan时,发现国区版本已经售罄,需要定时抢购。"最终他通过支付渠道优惠,使得海外版Max包年套餐的价格接近国内水平。
Levi的实际使用体验也揭示了另一个重要问题:不同模型对配额的消耗存在差异。他实测发现,GLM Coding Plan配合GLM-5.1模型,额度消耗是ClaudeCode加Opus4.6的1.5-2倍。这种差异促使开发者需要更精细地评估不同服务的性价比。
行业定价策略的深层逻辑
从商业角度看,区域差价是全球SaaS行业的常见策略。这种差异化定价基于几个核心考量:
首先,各地市场的支付能力存在差异。欧美开发者习惯于为生产力工具支付10-30美元月费,GitHub Copilot个人版长期定价10美元/月,Cursor主力套餐为20美元/月,都拥有稳定的付费用户群体。
其次,海外服务的运营成本更高。国际节点、海外算力资源和支付渠道都增加了成本负担。
最后,企业战略定位不同。国区面向庞大的工程师市场,优先追求规模效应;海外区则主攻高ARPU值市场,注重单用户收入。

主流厂商的定价竞争
2026年,几乎所有主要的大模型公司和云厂商都推出了自己的Coding Plan或类似产品。主流厂商面向国内的价格普遍在40-50元/月之间,其中MiniMax采取了相对低价的策略,月费29元,仅支持自家M2系列模型。
这种低价策略带来了显著的市场效果。OpenRouter数据显示,3月中旬MiniMax主力模型周调用量达到1.75万亿tokens,连续五周位列全球第一。同期,月之暗面的KimiK2.5为5600亿tokens,智谱GLM系列稳定进入全球前五。
MiniMax在TokenPlan中也采用了明显的双区定价策略:国际站标准版月付为10/20/50美元,中国区标准版则为29/49/119元。所谓的"高速版"对应可直接调用MiniMax-M2.7-highspeed的极速版订阅,主要区别在于响应速度。
配额消耗的技术考量
不同厂商采用了各具特色的配额管理机制。智谱的GLM5系列模型在高峰时段调用会消耗3倍配额,非高峰时段为2倍。这种"动态系数"机制鼓励用户在非繁忙时段使用先进模型,高峰时段则转向成本更低的版本。
MiniMax和Kimi则采用缓存机制来优化配额消耗:缓存命中时只计费0.7元/百万tokens。这些技术优化反映了厂商在提升用户体验与控制成本之间的平衡艺术。

算力市场的供需变化
AI服务定价的调整背后,是算力市场供需关系的深刻变化。知名半导体分析机构Semi Analysis的报告显示,美国市场上英伟达H100一年期GPU租赁合同价格从2025年10月的1.70美元/小时/GPU飙升至2026年3月的2.35美元/小时/GPU,涨幅近40%。
与此同时,国产算力正在加速接入国产模型体系。摩尔线程的MTTS5000服务器已实现"Day-0"兼容性,可为GLM-5.1提供服务。这种本土化算力支持为国产模型提供了成本优势。
商业化进程的加速
智谱2026年一季度的财报数据显示,尽管接口调用价格提升了83%,但调用量仍然增长400%。这种"价量齐升"的现象表明,国产模型在技术能力和商业化成熟度上已经达到新的高度。
小米集团MiMo负责人罗福莉在社交媒体上指出:"全球的算力供给,跟不上agent带来的token需求增长。真正的出路不是更便宜的token,而是模型和Agent的'协同进化'。"这一观点揭示了AI服务定价背后的技术演进逻辑。
市场反应的多样性
面对价格上涨,用户社区的反应呈现多样化特征。有用户抱怨"三个月涨了五倍,简直贵的离谱",也有用户认为价格调整后模型调用的平顺性得到提升:"很高兴看到系统恢复了平衡。任何系统都无法承受海啸般剧烈的变化。"
资本市场的反应更为直接:截至4月14日,智谱在港股的市值达到4200亿港元,超过同期上市的MiniMax。这一市场表现反映了投资者对国产模型商业化前景的信心。
未来发展趋势
随着国产模型在能力输出、稳定性、安全性和生态支持上不断进步,全球AI服务定价体系正在经历重构。低价抢占市场的阶段正在结束,取而代之的是更加精细化的差异化定价策略。
这种变化不仅体现在价格数字上,更反映了中国AI企业在全球市场竞争地位的提升。从技术追随者到规则制定者,国产模型厂商正在通过创新的商业模式重新定义全球AI服务市场格局。
未来,随着技术继续演进和市场需求变化,AI服务定价策略还将持续优化。但可以肯定的是,中国支付工具成为海外开发者"省钱利器"的现象,只是这个更大变革过程中的一个有趣插曲。