AI Agent测试困境:传统方法为何失效
在AI Agent快速发展的背景下,一个普遍存在的问题逐渐显现:许多在演示环节表现优异的AI Agent,在实际部署后却频繁出现各种意外问题。这种现象背后的根本原因在于,传统软件测试方法论与AI Agent的特性存在本质冲突。
传统软件测试建立在确定性验证的基础上——相同的输入必然产生相同的输出。测试用例固定,判断标准明确,这套经过几十年验证的方法论在传统软件开发中行之有效。然而,AI Agent基于大语言模型构建,其核心特征恰恰是非确定性。同一个用户问题,Agent可能选择不同的工具、采用不同的推理路径,最终给出不同的回答。
这种非确定性意味着,单次测试结果只能反映"可能发生的情况",而无法代表"通常发生的情况"。更重要的是,AI Agent的决策链路包含多个关键环节:工具选择、参数构造、结果合成,每个环节都可能成为问题的源头。传统测试方法只关注最终输出是否正确,就像考试只看总分而不分析各科成绩,难以发现深层次的质量问题。

AgentCore Evaluations:量化评估的新范式
Amazon Bedrock AgentCore Evaluations的推出,标志着AI Agent质量评估进入了一个新阶段。该服务基于三个核心原则构建评估体系:证据驱动开发、多维度评估和持续度量。
技术架构与兼容性设计
该服务的一个显著特点是基于OpenTelemetry标准构建。OpenTelemetry作为开源的可观测性标准,为生成式AI场景加入了专门的语义约定,包括提示词、补全结果、工具调用和模型参数等关键元素。这种设计确保了评估体系的框架无关性——无论使用Strands Agents还是LangGraph构建的Agent,只要接入了OpenTelemetry或OpenInference标准,就能直接使用这套评估系统。
三种评估方式的灵活组合
LLM-as-a-Judge评估是最核心的评估方式。这种方式使用一个大模型来评判另一个大模型的输出质量。评估模型会全面审视交互上下文,包括对话历史、可用工具、实际调用的工具和参数、系统指令等,然后给出评分和详细的推理过程。每个分数都附带解释说明,帮助开发者理解评分依据和改进方向。
Ground Truth评估适用于具有明确标准答案的场景。开发者可以预先定义期望的工具调用序列、回答内容或目标状态,系统会比较Agent的实际行为与标准答案之间的差距。这种方式特别适合具有明确业务规则的场景。
自定义代码评估器则针对需要精确检查的场景设计。当评估需求涉及特定格式验证或精确数值匹配时,可以通过AWS Lambda函数实现确定性检查。这种方式成本较低,适合生产环境下的高频评估需求。
双模式评估体系的设计逻辑
AgentCore Evaluations巧妙地将评估分为在线评估和按需评估两种模式,分别覆盖Agent生命周期的不同阶段。

在线评估模式从生产流量中持续采样交互数据,自动评分并展示在监控仪表板上。这种模式能够捕捉到传统运维监控难以发现的"无声退化"——即使系统层面的指标正常,用户体验可能已经在悄然恶化。
按需评估模式则为开发者提供了实验室环境,可以选择特定交互进行详细分析。这种模式特别适合提示词优化、模型对比和回归测试等开发场景。两种模式使用同一套评估器,确保了开发测试与生产监控的标准一致性。
13个维度的精细化评估体系
AgentCore Evaluations将Agent交互组织为三层结构,对应不同粒度的评估需求:
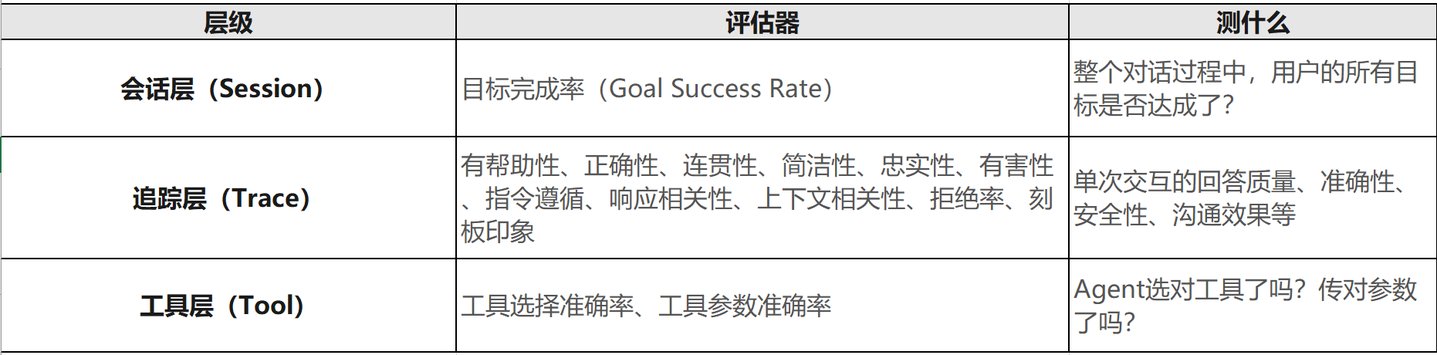
工具层评估指标
工具选择准确率评估Agent是否选择了正确的工具来完成特定任务。工具参数准确率则检查传递给工具的参数是否正确。这两个指标对于工具密集型Agent至关重要,它们确保了基础操作的正确性。
追踪层评估指标
上下文相关性评估Agent是否获取了完成任务所需的正确信息。目标完成率衡量Agent是否成功达成了用户的目标。正确性指标检查最终回答的事实准确性,而忠实性确保回答内容与提供的信息保持一致。
会话层评估指标
有帮助性评估回答是否对用户有实际价值,简洁性衡量回答是否避免不必要的冗长,安全性检查内容是否符合安全规范,无害性确保回答不会造成伤害。
评估器间的依赖与权衡关系
评估器之间存在明显的依赖关系。例如,工具参数准确率只有在工具选择准确率高的前提下才有意义——如果工具选错了,参数再准确也无济于事。同样,正确性往往依赖于上下文相关性,没有正确的信息输入,就不可能生成正确的回答。
评估器之间也存在矛盾关系。简洁性和有帮助性经常发生冲突——过于简洁的回答可能省略了用户需要的上下文信息。这种权衡关系提醒开发者在优化时需要综合考虑多个维度。
实用诊断模式与最佳实践
常见问题排查模式
当所有评估器分数都很低时,通常表明存在基础性问题。建议优先检查上下文相关性、系统提示词和工具描述等基础配置。
如果相似交互的评分不一致,很可能是评估器配置问题。需要检查评估指令是否具体明确,评分等级定义是否清晰可区分。适当降低评估模型的温度参数可以提高评分稳定性。
工具选择准确但目标完成率低的情况,说明Agent选对了工具但未能完成用户目标。这可能是因为缺少必要工具,或者Agent难以处理多步顺序调用的复杂任务。
实施策略建议
建议从3-4个核心评估器开始,根据Agent类型选择最关键的评价维度。客服型Agent应优先关注有帮助性和目标完成率,RAG型Agent需要重点评估正确性和忠实性,工具密集型Agent则要密切关注工具选择和相关参数准确性。
每个问题类别建议至少测试10次,按类别分组统计方差,这样可以更准确地了解Agent在不同场景下的稳定性表现。每次修改前后都应该进行对照实验,用数据支撑优化决策。
行业发展趋势与影响
AI Agent行业正在经历从"能不能用"到"用得好不好"的范式转变。Gartner预测,到2028年,33%的企业软件将内嵌Agent能力。这种规模化部署趋势对Agent的可靠性和可衡量性提出了更高要求。
AgentCore Evaluations的发布反映了行业对标准化评估体系的迫切需求。未来,成熟的Agent产品不仅需要具备功能完整性,还必须能够证明其服务质量。这种转变类似于汽车工业的发展历程——不是发动机技术最关键,而是碰撞测试、耐久测试等整套质检标准让消费者敢放心使用。
评估体系的局限与未来发展
虽然AgentCore Evaluations提供了全面的质量评估框架,但它主要关注质量维度。Agent的商业成功还需要综合考虑延迟、成本、用户体验等多个因素。此外,评估体系本身也需要随着技术发展不断演进。
未来可能出现的方向包括:更细粒度的评估维度、自适应评估阈值、跨模型评估标准化等。随着Agent应用场景的不断扩展,评估体系也需要相应扩展以覆盖新的需求。
这套评估体系的价值在于,它为AI Agent的质量讨论提供了数据支撑,使"这个Agent行不行"的问题从主观判断变成了客观度量。这种转变对于AI Agent的大规模商业化应用具有重要意义。