在当前的AI图像生成应用中,用户经常遇到一个令人困扰的问题:生成单张图像时效果出色,但当需要连续生成多张相关图像时,结果往往缺乏一致性。角色形象在不同图像中发生变化,风格特征无法保持统一,甚至连基本的逻辑连贯性都难以保证。这些问题严重制约了AI图像生成技术在真实场景中的应用价值。
技术瓶颈的本质
传统图像生成模型的核心优化目标始终是单次生成的质量最大化。模型被训练为在给定文本提示的情况下生成最优的单张图像,但这种优化范式天然忽略了跨图像之间的关系维护需求。当需要生成一系列相关图像时,模型缺乏对哪些特征需要保持不变的内在理解能力。
这种局限性源于模型训练数据的特性。大多数训练数据都是独立的图像-文本对,模型学习的是从文本到单张图像的映射关系,而没有机会学习多张图像之间的关联模式。因此,即使模型在单图生成上表现出色,在多图场景中也会出现一致性断裂的问题。
创新方法的核心思路
最新研究提出了一种根本性的范式转变:将一致性问题重新定义为跨图比较的学习任务。这种方法不再依赖于传统的单图质量评估,而是构建了一个能够理解图像对之间一致性关系的奖励模型。
该方法的创新之处在于它模拟了人类判断一致性的认知过程。当我们判断两张图像是否一致时,我们不会给每张图像单独打分然后比较分数,而是直接进行对比分析,综合考虑身份特征、风格元素、逻辑关系等多个维度。这种相对比较的方式更符合人类直觉,也更能捕捉一致性的本质。
数据构建与训练策略
构建有效的训练数据是该方法成功的关键。研究人员设计了一套结合自动生成与人工标注的数据构建流程。首先利用生成模型创建具有内部一致性的图像网格,然后通过拆分组合的方式构造大量具有不同一致性关系的图像对。
这种数据构建方法的核心优势在于其效率性和多样性。通过在有限的基础图像上进行组合变换,可以生成规模庞大的训练样本,确保模型能够学习到各种复杂的一致性关系模式。同时,人工标注过程保留了人类判断的主观性和多维性,使模型能够学习到真正的人类一致性标准。
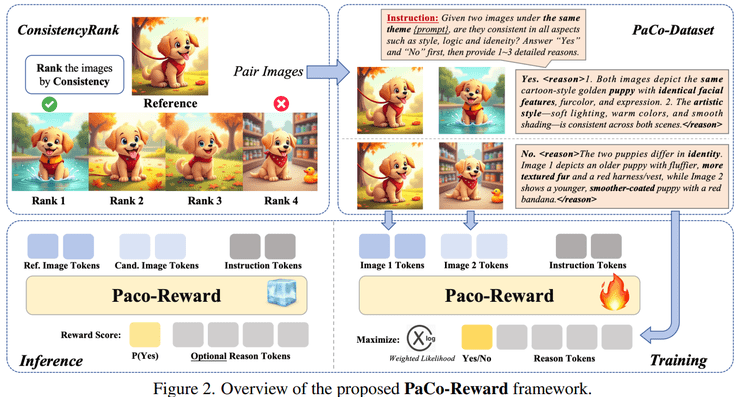
在模型架构设计上,研究团队采用了生成式奖励模型的思路。与传统标量输出不同,该模型将一致性判断建模为语言生成任务,不仅输出判断结果,还生成推理过程。这种设计显著提升了模型的可解释性,同时避免了模型仅依赖表面特征进行简单匹配的问题。
强化学习框架的优化
将奖励模型与生成过程结合是实现一致性生成的关键步骤。研究采用了强化学习框架,让生成模型能够根据奖励模型的反馈不断优化其生成策略。这一过程模拟了人类通过反馈学习改进的认知机制。
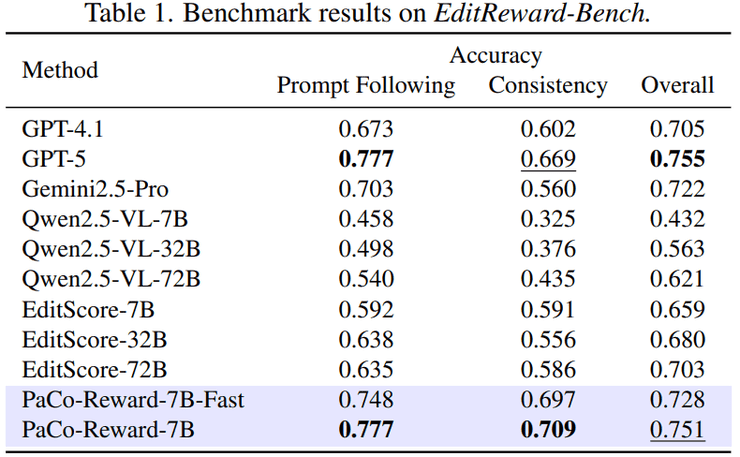
在具体实现中,团队提出了两个重要的优化策略:分辨率解耦和奖励平衡。分辨率解耦策略通过在训练阶段使用低分辨率图像来降低计算成本,同时保持推理阶段的高分辨率输出。实验表明,512分辨率训练6小时即可达到与1024分辨率训练12小时相当的效果,大幅提升了训练效率。
奖励平衡策略则解决了多目标优化中的冲突问题。在一致性生成任务中,模型需要同时优化一致性、文本对齐等多个目标,不同奖励之间可能存在尺度差异。通过对波动较大的奖励进行适当压缩,研究人员成功实现了多个优化目标的平衡,避免了单一目标主导训练过程的问题。
实际应用效果验证
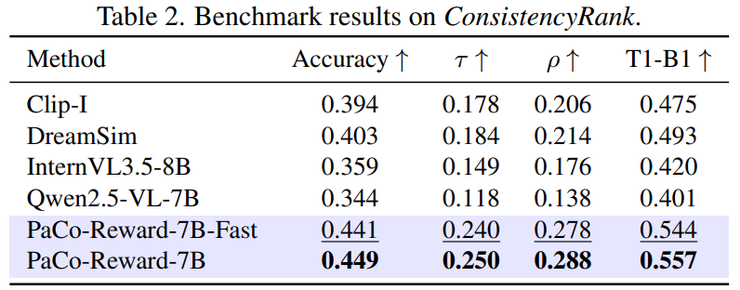
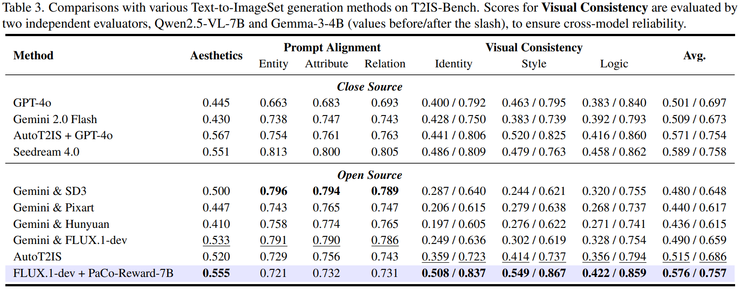
在Text-to-ImageSet多图生成任务中,新方法在身份一致性、风格一致性和逻辑一致性等多个维度均表现出显著提升。一致性指标整体提升10.3%到11.7%,这意味着在实际应用中,用户能够获得更加连贯统一的图像序列。
更为重要的是,这种一致性提升并没有以牺牲生成质量为代价。在图像编辑任务中,模型在保持语义一致性的同时,提示质量指标也持续改善。这表明该方法能够实现局部修改与整体保持的良好平衡,解决了传统编辑方法中"修改一处,影响全局"的难题。
在多语言设置下,该方法也表现出一致的改进趋势,证明了其良好的泛化能力。这种跨语言的一致性对于全球化应用场景具有重要意义,确保了技术在不同文化背景下的适用性。
技术突破的深远影响
这项研究的价值不仅体现在技术指标的提升上,更重要的是它为AI图像生成技术的实际应用开辟了新的可能性。在IP设计和品牌视觉领域,一致性是核心要求。传统方法需要大量人工干预才能保证多图一致性,而新方法使AI能够自动维持角色形象、风格特征的稳定性。
在内容生产场景中,故事分镜、系列插画等创作任务对一致性有极高要求。新方法使AI能够理解叙事连贯性的需求,在生成过程中自动保持人物特征、场景风格的一致性,大幅降低了创作门槛。

在工业和医疗领域,一致性生成技术同样具有重要价值。例如在工业设计可视化中,需要生成产品在不同角度、不同环境下的展示图像,一致性保证能够提供更真实的设计预览。在医疗影像分析中,生成具有一致性的对比图像有助于医生进行更准确的诊断评估。
未来发展方向
虽然当前方法在多图一致性生成方面取得了显著进展,但仍存在进一步优化的空间。一个重要的方向是扩展一致性维度的覆盖范围。目前的方法主要关注视觉特征的一致性,未来可以引入更多语义层面的一致性要求,如情感一致性、叙事逻辑一致性等。
另一个有前景的方向是动态一致性建模。现实世界中的一致性往往是动态变化的,角色会成长,场景会演变。如何建模这种有规律的动态一致性,使AI能够生成符合现实规律的变化序列,是下一个重要的研究课题。
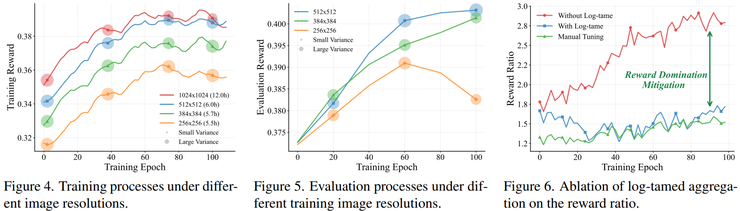
计算效率的持续优化也是关键方向。虽然当前方法通过分辨率解耦策略降低了训练成本,但在大规模商业化应用中,进一步降低推理延迟和资源消耗仍然是重要目标。模型压缩、推理优化等技术将在这一方向上发挥重要作用。
从更宏观的角度看,这项研究代表了AI生成技术从单点能力向系统能力演进的重要里程碑。它表明AI正在从孤立的任务执行向综合的问题解决方向发展,这种转变将为AI技术的广泛应用奠定坚实基础。
随着多图一致性生成技术的成熟,我们可以预见AI将在更多创造性工作中扮演重要角色。从广告设计到影视制作,从游戏开发到教育内容创作,保持一致性将不再是人类创作者的专属负担,而成为AI可以可靠完成的基础任务。这种转变不仅将提升创作效率,更将释放人类创造力,让我们能够专注于更高级别的创意构思和艺术表达。