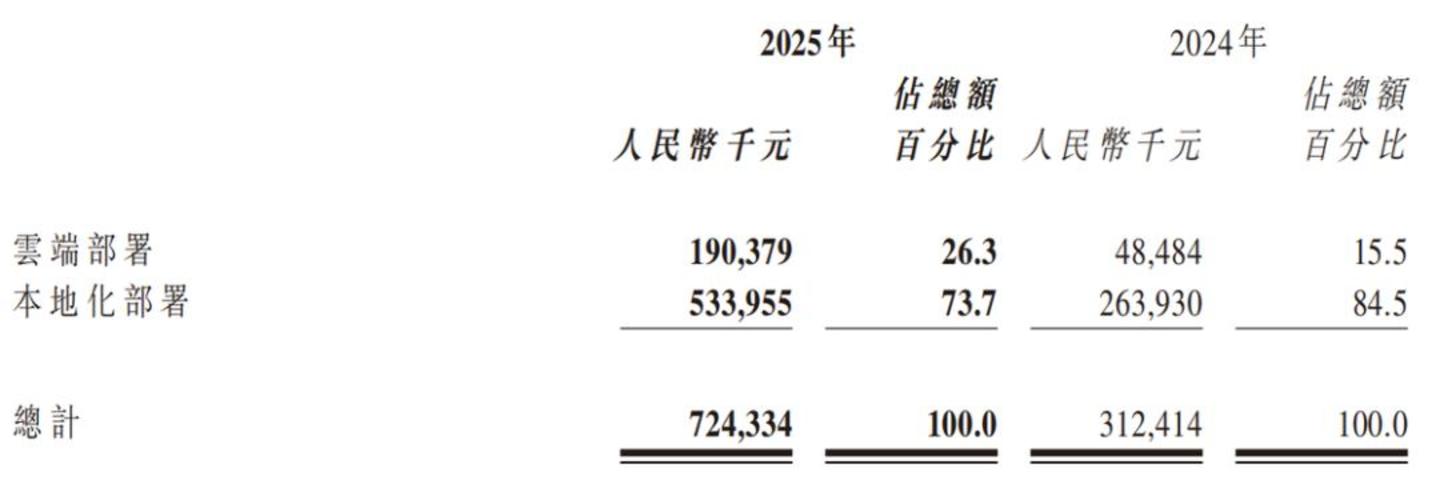
在机器人技术领域,一个看似简单却长期困扰研究人员的现象是:机器人伸手去拿桌上的杯子,刚把杯子抬起来又停住,随后放回原位,然后再次伸手去拿。这种动作重复现象在真实环境中并不少见——按钮明明已经按下却还在反复按,抽屉已经关好却还在继续推。
这些失败并非源于视觉感知能力的不足,而是机器人缺乏对时间维度的理解能力。当前的视觉语言行动模型虽然能够理解图像与指令,但在连续任务中仍然只能依赖当前观测做决策。一旦任务变成长步骤流程,例如拿起物体、移动、放置再到关闭装置,就容易出现动作重复和决策中断的问题。
时间感知的核心挑战
传统机器人系统基于"看到什么就做什么"的即时反应机制,在短任务中表现良好,但在长序列任务中容易出现动作不连贯和决策漂移。问题的根本不在于视觉能力不足,而在于缺乏对时间的建模能力。
机器人需要具备的不仅是感知当前状态的能力,更需要记住过去并预判未来的能力。这种时间理解能力正在成为决定机器人系统是否真正可用的关键因素。
HiF-VLA模型的技术突破
HiF-VLA模型不再简单依赖历史图像或未来画面预测,而是创新性地以"运动"作为时间信息的核心表达。这种方法使模型能够同时建模过去的变化、当前状态以及未来趋势,从而实现更稳定的连续决策。
运动信息相比图像更适合用于表示时间变化,因为图像中包含大量静态信息,而运动信息只保留了真正发生变化的部分,因此更加高效且更具表达力。这一发现对机器人研究带来了直接影响,使原本从感知到动作的单向过程转变为同时考虑过去、现在与未来的决策过程。
实验验证与性能表现
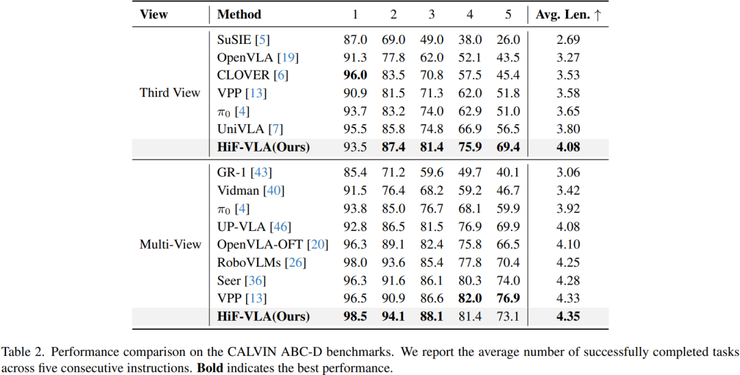
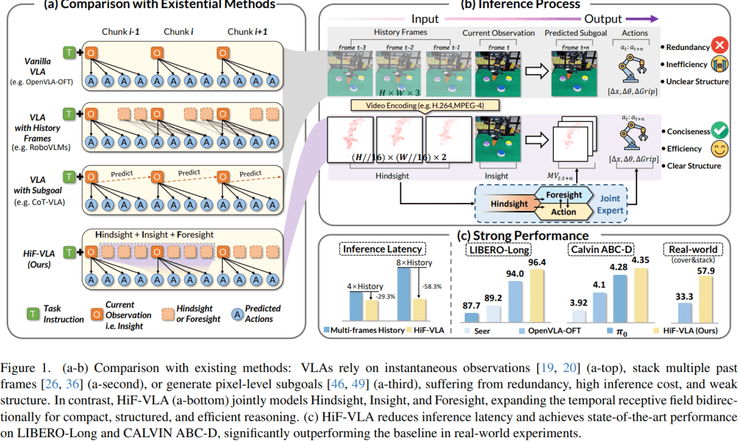
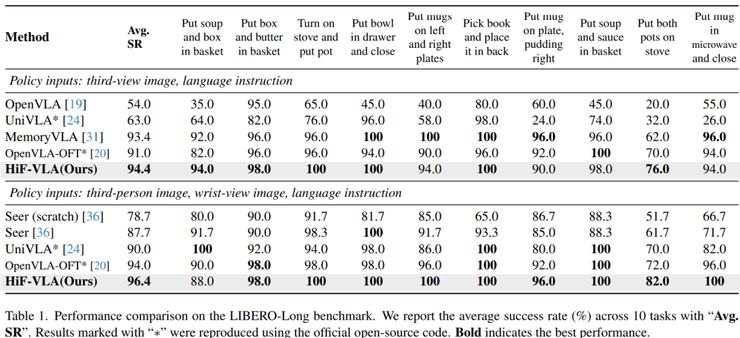
在LIBERO-Long长序列任务测试中,HiF-VLA模型展现了卓越的性能。研究主要测试机器人是否能够连续完成多个动作,例如拿取物体、放置以及关闭装置等。结果显示,该模型在单视角条件下的成功率达到94.4%,在多视角条件下达到96.4%。
作为对比,当前较强的方法OpenVLA-OFT在单视角下为91.0%,多视角为94.0%。这意味着HiF-VLA在单视角下提升了3.4个百分点,在多视角下提升了2.4个百分点。更重要的是,在10个具体任务中,有多个任务的成功率达到100%,而最低的任务也达到了76%,说明整体性能稳定。
在CALVIN跨环境泛化任务中,研究在A、B、C三个环境中训练模型,并在未见过的D环境中进行测试。评价指标是连续成功完成任务的数量,即在不中断的情况下能够连续完成多少个步骤。结果显示,该方法在单视角下达到4.08,在多视角下达到4.35,相比基线提升约0.25个任务。
这个提升具有重要意义,因为该指标一旦中间某一步失败后续任务将不再计入,因此数值越高说明模型在长时间连续决策中的稳定性越强,也体现了更好的长期规划能力。
计算效率的优势
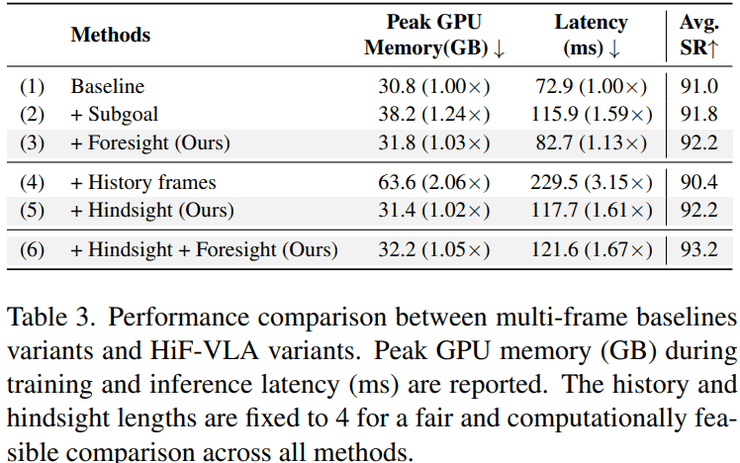
在效率与计算成本方面,研究深入分析了性能提升是否以计算开销为代价。结果显示,当引入基于图像的未来子目标预测时,成功率为91.8%,但延迟增加到115.9毫秒,比基线慢1.59倍。当采用历史帧堆叠时,成功率反而下降到90.4%,延迟上升到229.5毫秒,是基线的3.15倍。
相比之下,HiF-VLA方法在只加入未来推理时,成功率为92.2%,延迟为82.7毫秒,几乎没有额外开销;只加入历史信息时,成功率同样为92.2%,延迟为117.7毫秒;同时加入两者后,成功率达到93.2%,延迟为121.6毫秒。
整体来看,该方法在提升成功率的同时,计算成本远低于堆叠历史帧的方法,说明使用运动信息比直接使用图像历史更加高效。这一发现对于实际应用具有重要意义,因为计算效率直接关系到机器人的实时响应能力。
时序长度扩展能力
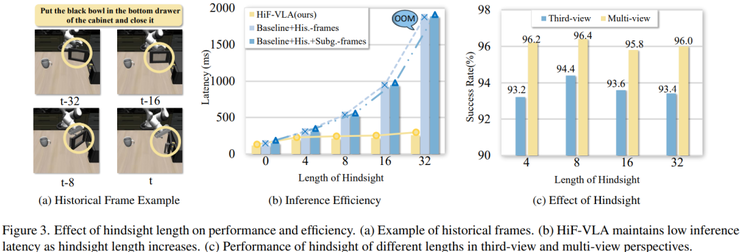
在时序长度扩展能力测试中,研究逐步增加历史长度,从4到8,再到16和32。结果表明,当长度为8时性能最佳,单视角为94.4%,多视角为96.4%,继续增加长度反而会导致性能下降,其原因在于信息过多带来的冗余干扰。
在延迟方面,传统方法的计算成本会随着历史长度线性增长,当长度为8时延迟增加约4.5倍,而HiF-VLA方法的延迟基本保持稳定,仅有轻微增长,说明其在时间维度上具有更好的扩展性。
真实环境验证
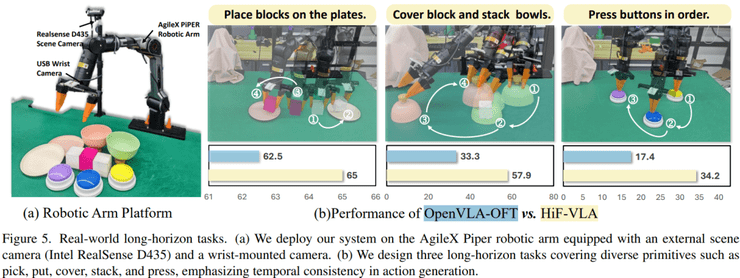
在真实机器人实验中,研究设置了多个长序列任务来验证实际效果。在按顺序按按钮任务中,基线方法的成功率为17.4%,而HiF-VLA方法提升到34.4%,接近翻倍。在覆盖与堆叠任务中,基线为33.3%,该方法达到57.9%,提升了24.6个百分点。
在放置任务中,基线约为62.5%,该方法约为65%,提升较小但表现更加稳定。分析认为,基线方法难以判断按钮是否已经被按下,因为状态变化较为细微,而HiF-VLA方法能够利用时间变化信息来识别状态转变,因此在复杂任务中表现更好。
技术实现细节
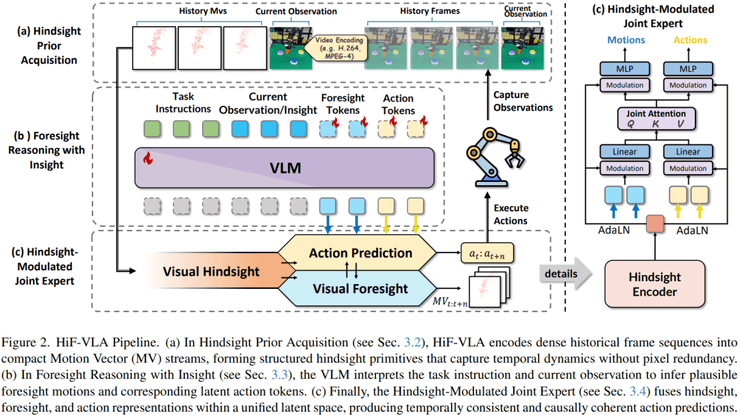
在模型架构设计上,HiF-VLA同时接收三类信息:当前画面作为对当前状态的感知信息,历史运动作为对过去动态变化的表达,以及语言指令用于提供任务目标。这种设计使模型能够在时间维度和语义层面进行联合决策。
研究团队设置了系统的对比实验,包括仅使用当前观测信息的方法、通过堆叠历史图像引入时间信息的方法,以及通过预测未来图像作为子目标的方法。实验结果表明,使用运动信息替代图像来表示时间变化能够有效减少冗余信息并提高建模效率。
在消融实验中,研究进一步分析了不同设计选择对性能的影响。历史长度实验表明最优长度为8,过短无法提供足够信息,过长则会引入冗余。在历史信息使用方式上,将历史信息注入决策模块比直接输入视觉语言模型效果更好,成功率从92.8%提升到94.4%。
范式转变的意义
这项研究推动了一种新的智能范式,从"看到就做"的视觉语言行动模型到"边想边做"的世界行动模型。过去的系统更像是被动反应的执行者,只对当前输入做出即时回应;而在新的范式下,机器人开始具备连续决策的能力。
这种变化的意义在于,机器人不再只是完成单步动作,而是能够理解一整段过程,并在过程中不断调整自己的行为。这意味着具身智能的发展正在从"感知驱动的反应系统"走向"时间驱动的推理系统"。
当模型真正具备这种能力时,机器人才能在复杂、动态的真实环境中稳定工作,而不仅仅是在受控场景中完成预设任务。这种能力的提升对于机器人在制造业、服务业、医疗等领域的实际应用具有深远影响。
未来发展方向
HiF-VLA模型的研究为机器人时间感知能力的发展开辟了新的方向。未来研究可以进一步探索如何优化运动信息的提取和表示方式,以及如何将这种方法扩展到更复杂的环境和任务中。
同时,该方法与其他先进技术的结合也值得深入研究,例如与强化学习、元学习等方法的融合,可能带来更强大的机器人学习能力。在工程应用方面,如何将该方法部署到不同类型的机器人平台,并确保其在各种环境下的稳定性,将是下一步研究的重点。

这项研究不仅解决了机器人连续决策的技术难题,更重要的是提出了一种新的思考方式:让机器人从被动执行转向主动思考。随着技术的不断进步,我们有理由相信,具备时间感知能力的机器人将在未来发挥更加重要的作用。