近年来,多模态大模型的发展正在不断推动视觉理解能力的提升。从图像分类、目标检测到视觉问答等任务,视觉系统已经能够在多种场景中实现较高水平的识别和推理能力。然而,在更复杂的层级视觉识别任务中,现有模型仍然存在明显不足。
现实世界中的许多视觉概念天然具有层级结构,例如生物分类体系中的"界—门—纲—目—科—属—种",以及商品分类、医学诊断等领域中的多层级标签体系。这类任务不仅要求模型识别具体类别,还需要理解不同类别之间的层级关系和语义结构。但目前多数视觉模型仍然基于扁平分类框架进行训练,在进行层级预测时容易出现分类路径不一致或层级关系冲突等问题。
与此同时,在开放世界环境中,视觉模型还需要具备识别未知类别的能力。以生物识别任务为例,现实世界中的物种数量远远超过现有数据集的覆盖范围,新的物种仍在不断被发现。当模型面对训练数据中未出现的类别时,往往难以进行合理推断。如何利用已有知识帮助模型理解类别之间的层级结构,并在有限数据条件下推断未知类别,逐渐成为当前视觉智能研究中的重要问题。

技术方法创新
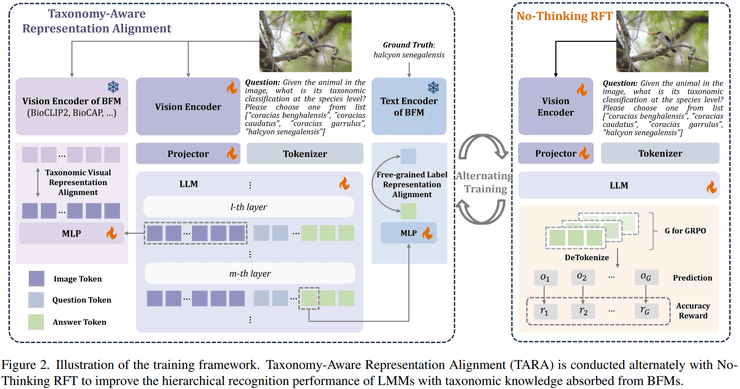
在这一背景下,研究人员提出了一种新的方法TARA(Taxonomy-Aware Representation Alignment)。该方法通过引入生物基础模型中的分类学知识,并将其与多模态模型的中间表征进行对齐,使模型能够学习到具有层级结构的视觉表示。
具体而言,TARA方法包含两个核心对齐模块:视觉表示对齐和标签表示对齐。在视觉表示对齐过程中,首先使用生物基础模型提取图像特征,同时获取多模态模型中间层的视觉特征,然后将两者映射到同一特征空间,利用余弦相似度进行对齐。通过这一过程,模型能够学习符合生物分类结构的视觉表示空间。
在标签表示对齐方面,研究人员将分类标签输入生物基础模型的文本编码器获得标签嵌入,然后将多模态模型生成答案的token表征映射到同一空间,并进行相似度对齐。这种方法使模型能够学习不同层级标签之间的语义关系。
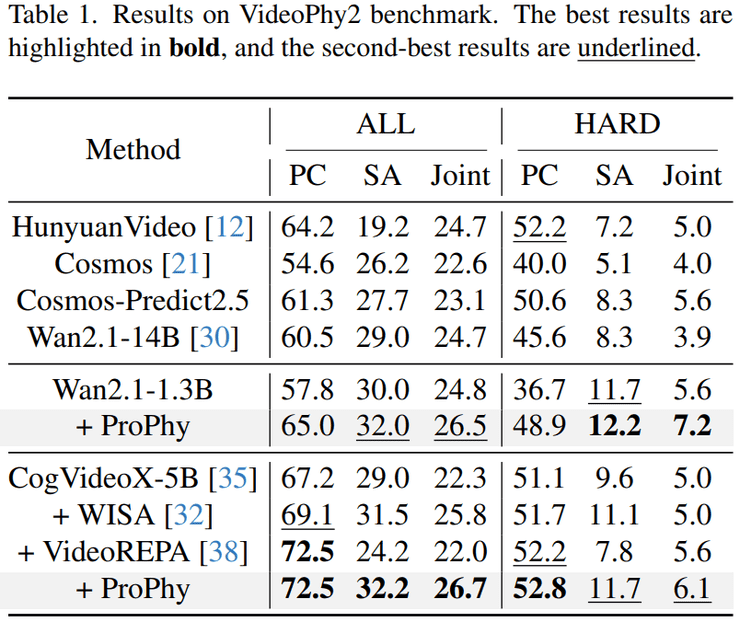
实验设计与结果分析
研究团队通过在多个数据集和多种评价指标下开展实验,对TARA方法在层级视觉识别任务中的有效性进行了系统验证。实验采用了iNaturalist-2021数据集,该数据集包含大量具有层级分类结构的生物图像,并划分为植物和动物两个子数据集。
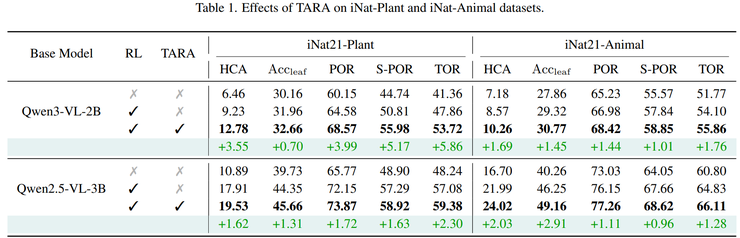
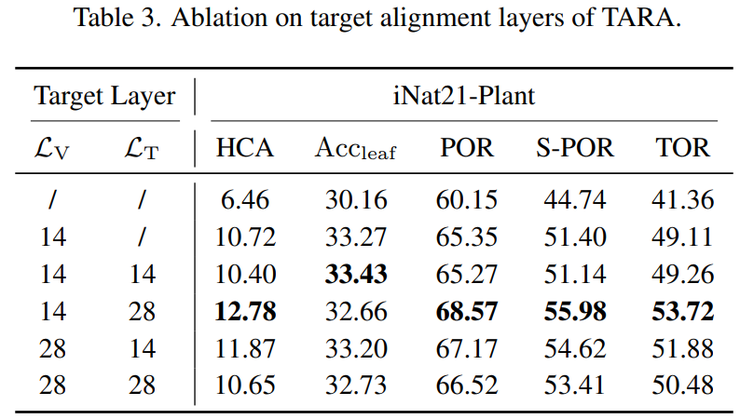
在已知类别识别能力测试中,实验结果表明,在引入TARA方法之后,模型在多个评价指标上均获得明显提升。在iNat21-Plant数据集上,Qwen3-VL-2B基础模型在经过强化学习微调后,层级一致性准确率由9.23%提升到12.78%,叶节点准确率由31.96%提升到32.66%。
对于规模更大的Qwen2.5-VL-3B模型,在植物数据集上的层级一致性准确率提升至19.53%,在动物数据集上的层级一致性准确率提升至24.02%,各项指标均持续提高。这些结果表明,TARA方法能够稳定提升不同规模多模态模型在层级分类任务中的整体性能。
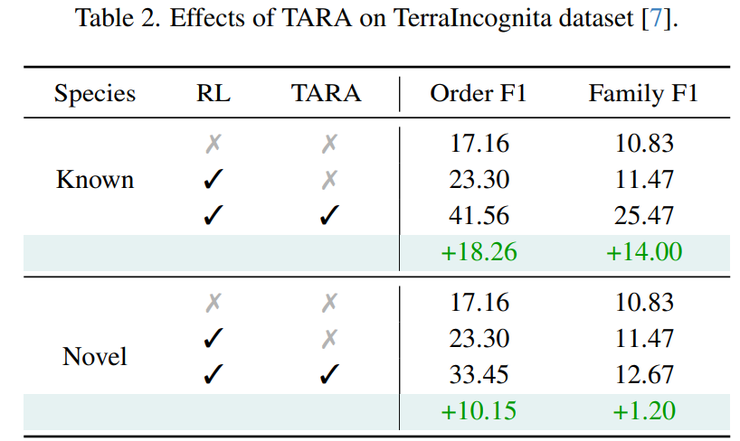
在未知类别识别能力验证方面,研究团队使用TerraIncognita数据集进行测试。该数据集包含大量稀有或未知物种图像,其中部分物种可能从未出现在训练数据中。实验结果显示,在已知类别场景下,Order F1从23.30提升到41.56,Family F1从11.47提升到25.47;在未知类别场景下,Order F1从23.30提升到33.45,Family F1从11.47提升到12.67。
这一结果具有重要意义,表明TARA不仅提升了模型对已知类别的识别能力,同时也显著增强了模型在面对未知物种时的泛化能力。这对于真实环境中的应用具有重要价值,因为在实际的生物识别任务中,模型经常需要处理训练数据中未包含的新物种。
表征能力分析
为了深入理解TARA方法对模型表征能力的影响,研究人员通过线性探针实验进行了进一步分析。实验从模型最后一层提取图像token表征,并利用线性分类器进行训练,在iNat21-Plant数据集上测试分类准确率。
实验结果表明,原始模型的分类准确率为13.30%,加入强化学习后提升到14.40%,在进一步引入TARA方法之后准确率提升到18.30%。这一结果说明TARA能够帮助模型学习到更加具有判别力的视觉特征表示。
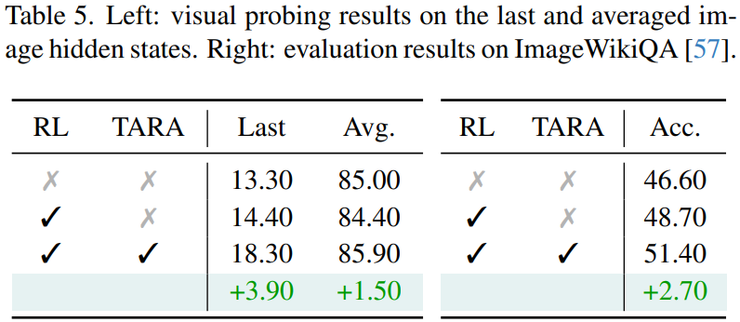
在分类型视觉问答任务方面,研究团队在ImageWikiQA数据集上对模型性能进行了测试。该数据集包含基于ImageNet图像的复杂视觉问答任务。实验结果显示,基础模型的准确率为46.60%,经过强化学习微调后提升到48.70%,在引入TARA方法之后进一步提升到51.40%。这一结果表明,通过增强层级视觉理解能力,可以进一步提升模型在复杂视觉理解和推理任务中的整体表现。
训练效率优化
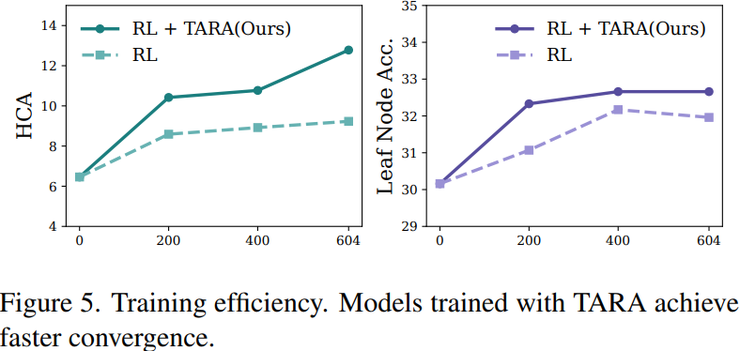
在训练效率方面,研究人员对模型训练过程中性能变化进行了详细分析。实验结果显示,在训练早期阶段,引入TARA的模型性能已经超过基线模型;在相同训练步数条件下,TARA模型的层级一致性准确率指标和叶节点准确率均高于未使用该方法的模型。
这一现象说明TARA方法能够加速模型的训练收敛过程。同时,由于TARA仅增加少量投影层,因此整体计算开销较小,对训练效率影响有限。这种高效的训练方式使得该方法在实际应用中具有更好的可行性。
数据集构建与评价体系
研究团队设计了一套完整的实验流程,其中包括模型训练方案、数据集构建方式以及评价指标体系的设计。在实验数据集方面,研究人员选取了多个具有代表性的公开数据集进行实验。
iNaturalist-2021数据集包含完整的生物分类体系,其中Plant子集包含4271个物种类别,Animal子集包含5388个物种类别。数据集中每个样本都具有六级分类结构,即Kingdom、Phylum、Class、Order、Family和Species六个层级,因此非常适合用于层级视觉识别研究。
除了iNat21数据集之外,研究团队还使用了TerraIncognita数据集来测试模型在开放世界环境下的识别能力。该数据集包含来自中美洲和南美洲生物多样性热点地区的昆虫图像,其中许多物种缺乏公开图像数据,并且部分物种可能尚未被科学界正式记录。
在评价指标设计方面,研究人员开发了多种专门针对层级识别任务的评价标准。Hierarchical Consistent Accuracy用于评估模型是否能够正确预测完整的分类路径;Leaf-level Accuracy用于衡量最细粒度类别的预测准确率;Point-Overlap Ratio用于统计预测路径中正确节点所占的比例。
这些评价指标的组合使用,能够全面评估模型在层级结构识别任务中的整体性能,为方法比较和性能分析提供了可靠的基础。
技术实现细节
在基础模型选择方面,研究人员采用Qwen系列多模态模型作为实验基础模型,包括Qwen3-VL-2B-Instruct和Qwen2.5-VL-3B-Instruct两种模型。这些模型在零样本视觉理解任务中表现良好,因此适合作为层级视觉识别研究的基础模型。
在训练方法方面,研究团队将强化学习微调方法与TARA表征对齐方法结合起来进行训练。采用No-Thinking强化学习微调策略,在分类任务中不进行显式推理反而能够获得更好的效果。奖励函数的设计为,如果模型预测结果正确则奖励值为1,如果预测结果不正确则奖励值为0。
在训练过程中,研究团队采用交替训练策略,使模型在两种目标之间不断优化。一方面通过强化学习优化分类任务,另一方面通过TARA进行知识对齐,从而使模型逐渐吸收生物分类学知识并提升层级识别能力。这种训练策略确保了模型在保持原有功能的同时,能够有效学习新的层级知识。
应用前景与推广价值
这项研究在理论和实际应用方面都具有重要意义。首先,在解决多模态模型层级识别能力不足的问题方面,TARA方法通过引入分类学知识,使模型在识别过程中能够更好地保持不同层级之间的逻辑关系,从而显著提升模型在层级分类任务中的一致性表现。
其次,在提升模型对未知类别的泛化能力方面,TARA利用生物基础模型中蕴含的分类学知识,使模型能够推断未知类别之间的层级关系,并在缺乏训练样本的情况下仍然完成识别任务,这对于开放世界识别任务具有重要意义。
在方法层面,研究提出了一种新的技术思路,即通过中间表征对齐的方式,将领域知识注入到多模态模型之中。这种方法不仅可以应用于生物分类任务,还能够推广到其他具有层级结构的应用场景,例如医学影像分类、商品分类以及知识图谱推理等领域。

在推动通用视觉理解系统发展方面,研究人员认为未来的视觉系统不仅需要具备识别具体对象的能力,还需要能够理解不同对象之间的结构关系。通过在模型训练过程中引入层级知识,多模态大模型可以逐步具备对结构化知识的理解能力,从而进一步发展成为能够理解复杂结构关系的视觉智能系统。
技术发展趋势
随着人工智能技术的不断发展,多模态大模型在层级识别任务中的应用前景广阔。TARA方法的成功表明,通过合理引入领域知识,可以有效提升模型在复杂识别任务中的性能。
未来,类似的技术思路可以扩展到更多的应用领域。在医疗影像分析中,模型需要理解疾病分类的层级结构;在商品识别中,需要把握商品分类的层次关系;在知识图谱构建中,需要处理实体间的复杂关联。这些场景都可以借鉴TARA方法的思想,通过表征对齐技术注入领域知识。

同时,该方法也提示我们在模型设计过程中需要更多考虑现实世界的复杂性。扁平化的分类体系往往难以应对真实场景中的结构化需求,而层级化的思维方式更符合人类的认知习惯。因此,未来的视觉智能系统需要进一步发展层级识别能力,才能更好地服务于实际应用需求。
这项研究为多模态大模型的发展提供了新的方向,展示了如何通过知识注入提升模型在复杂任务中的表现。随着技术的不断成熟,我们有理由相信,具备层级识别能力的视觉系统将在更多领域发挥重要作用,推动人工智能技术向更高水平发展。