
贵了50%却更“懒”?Claude Opus 4.7发布即翻车,用户怒吼:还我4.6!
0

最新文章

具身智能“部署态元年”来了,智元内部研判:具身“GPT-3”进度条已拉升至30%!【深度解读】(附完整版)(钛媒体APP首发)(作者:秦聪慧)(DeepWrite秦报局)(2026.04.17)(来自江苏)(35.9万阅读)(全文8600字)(视频时长26分钟)
7分钟前

Kimi的问题不在对手,而在起点:一场关于AI生产力的远征与挑战
10分钟前
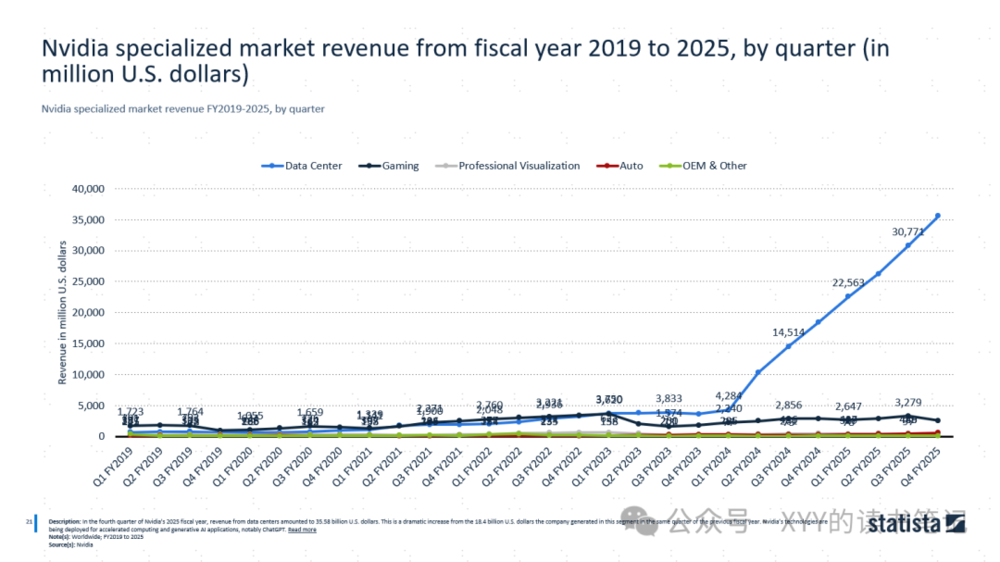
英伟达简史:基于愿景的运气(优化版):从扫厕所少年到AI时代霸主的崛起之路
56分钟前

上海AI实验室发布‘AGI4S珠穆朗玛计划’,构建中国科学智能创新中枢,邀全球科研力量共同定义未来
2小时前
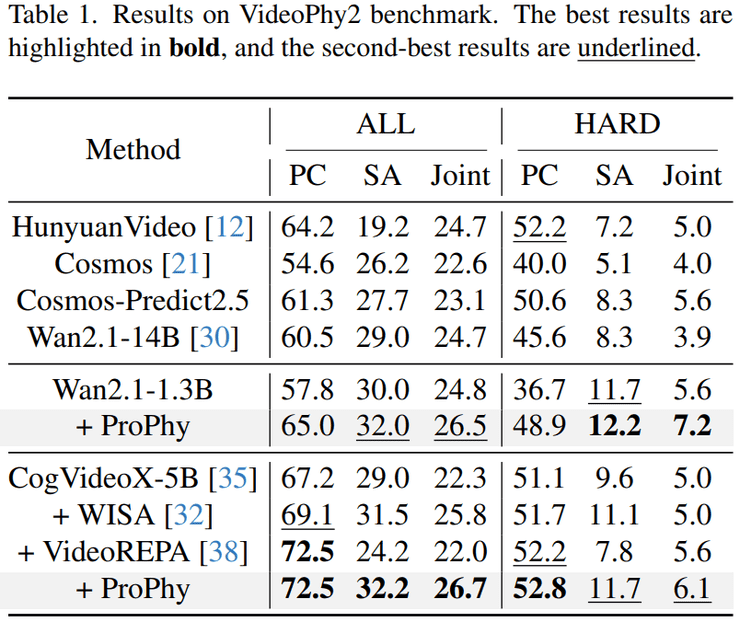
中山大学梁小丹团队论文:让视频生成从「看起来真实」到「物理上正确」丨CVPR 2026
2小时前

大模型不再只是生成:智象未来CTO姚霆谈AI如何开始‘完成’一个‘创作’
2小时前

【内容专家拆解】《截图不再是证据》:如何通过技术泄露制造科技爆款文
3小时前

日赚 2.3 亿,市值重回 A 股前三!宁王回应比亚迪“闪充”:跟我学的,构不成挑战?!
3小时前

富士,凭什么‘死而复生’?——从胶卷到科技集团的蜕变之路
23小时前

华为一句广告语,惹恼了“橘子海”:当科技巨头撞上独立乐队,谁在越界?
23小时前