在人工智能的发展历程中,理查德·萨顿2019年发表的《苦涩的教训》正在以出人意料的方式被验证。这位强化学习领域的奠基者用简洁的语言道出了一个深刻洞见:人类精心设计的领域知识和专家规则,最终都会输给让机器自主试错的方法。七年后的今天,这一判断在Agent浪潮中找到了新的注解。
Chatbot的天花板与Agent的突破
2023年ChatGPT的爆发让对话框式交互成为标配,但到了2024年底,用户活跃度的下滑暴露出Chatbot模式的根本局限。一问一答的交互无法适应真实工作的多步骤特性,更重要的是,每次对话都是孤立的,模型无法积累上下文和经验。
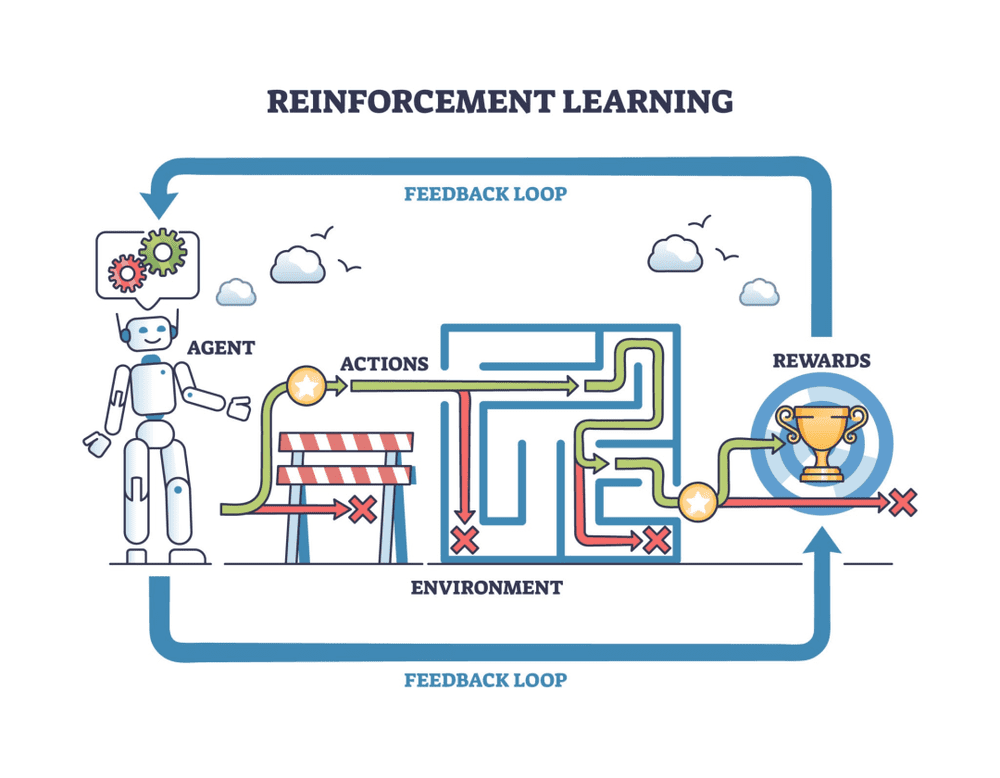
Agent的出现打破了这一僵局。与Chatbot仅仅输出答案不同,Agent需要自主完成整个工作流程。以安排出差行程为例,Agent会经历需求理解、数据查询、方案制定、反馈修正等完整环节。每一步都携带着明确的因果信号——调用接口失败意味着需要备用方案,用户反馈指导着后续优化方向。
这种交互产生的数据质量远超传统训练数据。它不是简单的语言模式匹配,而是智能体与现实世界博弈的实录。模型从中获得的不是更多知识,而是更强的推理能力和自我纠错能力。
两种发展路径的分野
2024-2025年,头部AI公司的发展策略出现明显分化。OpenAI和Google等公司继续专注于提升模型在基准测试上的表现,而Anthropic选择了不同的道路。
Anthropic为Claude推出的Computer Use功能看似笨拙,却让模型获得了直接操作现实世界的能力。随后推出的Model Context Protocol(MCP)开放协议,进一步扩展了模型与外部工具的连接范围。这种策略的核心在于:模型能力的提升不仅来自参数规模,更取决于与环境的交互方式。
OpenAI虽然也通过Function Calling、Assistants等功能探索工具调用,但其庞大的Chatbot用户基础形成了某种路径依赖。让数亿用户从问答模式转向任务指派模式,需要改变的是用户的心智模型。
交互数据的独特价值
Agent在真实任务中产生的决策轨迹具有不可替代的训练价值。这些数据包含目标设定、行动选择、环境反馈、错误修正等完整环节,形成了标注因果结构的优质训练材料。
相比之下,Chatbot对话产生的数据信息密度极低。无论是写诗、编程还是知识问答,这类交互本质上都是语言模式的重复预测,无法提供因果推理所需的信号。Agent给模型喂的是"决策的骨骼",而Chatbot只能提供"语言的影子"。
跨学科的智慧共鸣
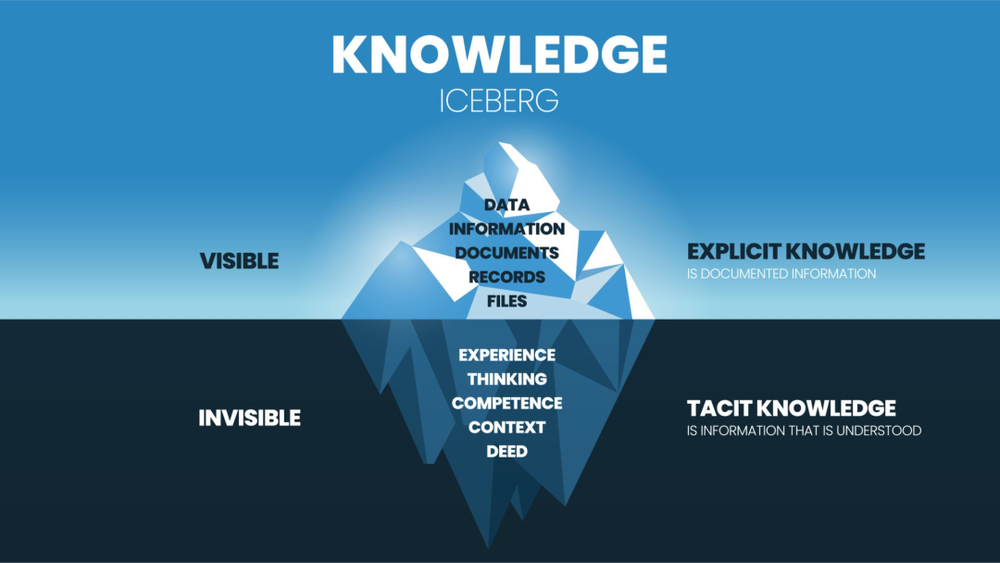
萨顿的强化学习理论与经济学、哲学领域的某些观点形成了有趣的呼应。哈耶克在《知识在社会中的利用》中指出,任何个人或组织都无法掌握复杂经济体所需的全部知识,有价值的知识是分散且隐性的。
这一观点与强化学习的核心逻辑高度契合:智能不是被设计出来的,而是在与环境的交互中自发形成的。哈耶克所说的"致命的自负"——人类试图设计出比自发秩序更好的系统——与萨顿批评的人工特征工程有着相似的逻辑缺陷。
波兰尼提出的"默会知识"概念进一步深化了这一认识。人类知道的远多于能说出来的,这种隐性知识无法通过文本训练获得,却能在Agent的行为轨迹中得到体现。当Agent在执行复杂任务时,其决策序列本身就包含了大量难以言传的判断逻辑。
现实世界的挑战与机遇
尽管Agent路线前景广阔,但实际推进面临诸多挑战。真实世界不是可以无限重启的虚拟环境,Agent的试错成本可能很高。一次越界操作可能导致交易失败、客户投诉甚至法律风险。
更复杂的是现实世界的反馈信号往往高度嘈杂且延迟。当某个策略最终见效时,很难区分这是模型推理的成果还是外部环境的偶然因素。这种因果归因的模糊性给模型学习带来了巨大困难。
然而,这些挑战恰恰是Agent进化必须面对的"苦涩"。DeepSeek-R1的成功表明,即使在受控环境中,通过强化学习也能显著提升模型的推理能力。这为Agent在真实世界的部署提供了重要参考。
能力生成机制的转变
Agent带来的最深刻变化在于能力生成机制的转变。传统模型主要依靠静态数据训练,能力上限被数据边界所限制。而Agent使模型能够从持续交互中获取进化燃料,形成了动态的学习循环。
这个循环的运转逻辑是:更好的Agent能力吸引更多用户使用,产生更多交互数据,进而训练出更强的模型。这种飞轮效应一旦启动,就能不断自我强化。
值得注意的是,Agent的价值不仅体现在任务完成效率上,更在于为模型提供了积累"经历"的机会。经历意味着时间维度和因果结构,这是形成真正判断力的基础。一个只有知识而没有经历的系统,很难应对真实世界的复杂性。
产业实践的启示
从产业实践角度看,Agent的发展需要平衡短期实用性与长期进化潜力。当前许多Agent应用看起来效率不高,甚至显得笨拙,但这种不完美恰恰是学习的前提。
企业引入Agent时,应该建立容错机制和反馈循环,让模型能够在安全边界内积累经验。同时,需要设计合理的评估体系,不仅关注任务完成率,还要考察模型的学习能力和适应性。
开发者生态的建设也至关重要。Anthropic的MCP协议之所以重要,是因为它降低了工具集成的门槛,让更多第三方能够参与Agent能力的扩展。这种开放策略有助于加速Agent在真实场景中的落地。
未来展望
站在当前时点展望,Agent浪潮还处于早期阶段。基准测试的竞争仍在继续,但单纯追求分数提升的边际收益正在递减。未来的突破更可能来自模型与现实世界交互方式的创新。
随着传感器技术、物联网设备和边缘计算的发展,Agent的交互范围将进一步扩大。从数字世界延伸到物理世界,从单一任务扩展到系统级协作,Agent的"经历"将变得更加丰富和多元。
这种进化不是一蹴而就的,需要在无数微小反馈中逐步积累。正如萨顿所强调的,智能的生长具有内在的必然性,只要提供足够复杂的环境和持续的交互机会。
最终,Agent可能重塑我们对人工智能的理解。它不再是静态的知识系统,而是具有学习能力和适应性的智能实体。这种转变的意义,将远超任何技术参数上的突破。