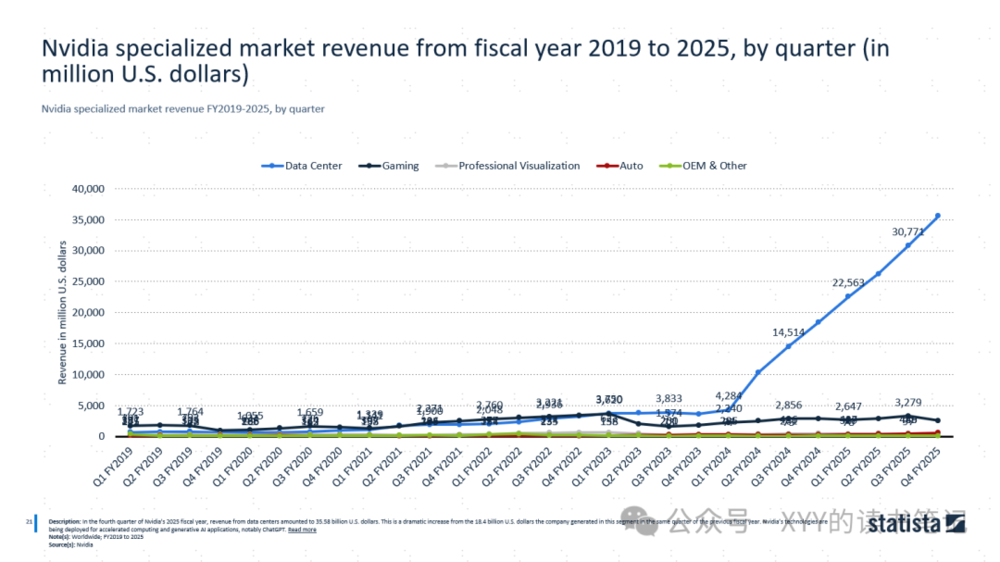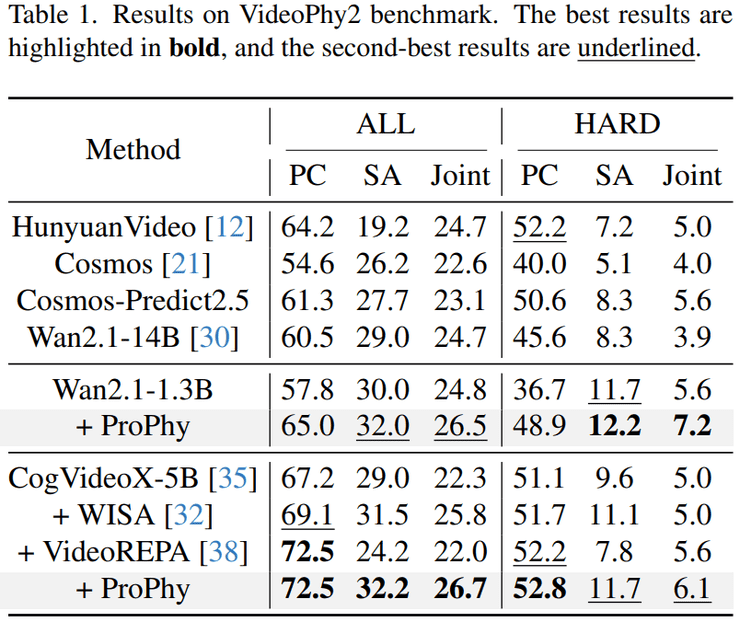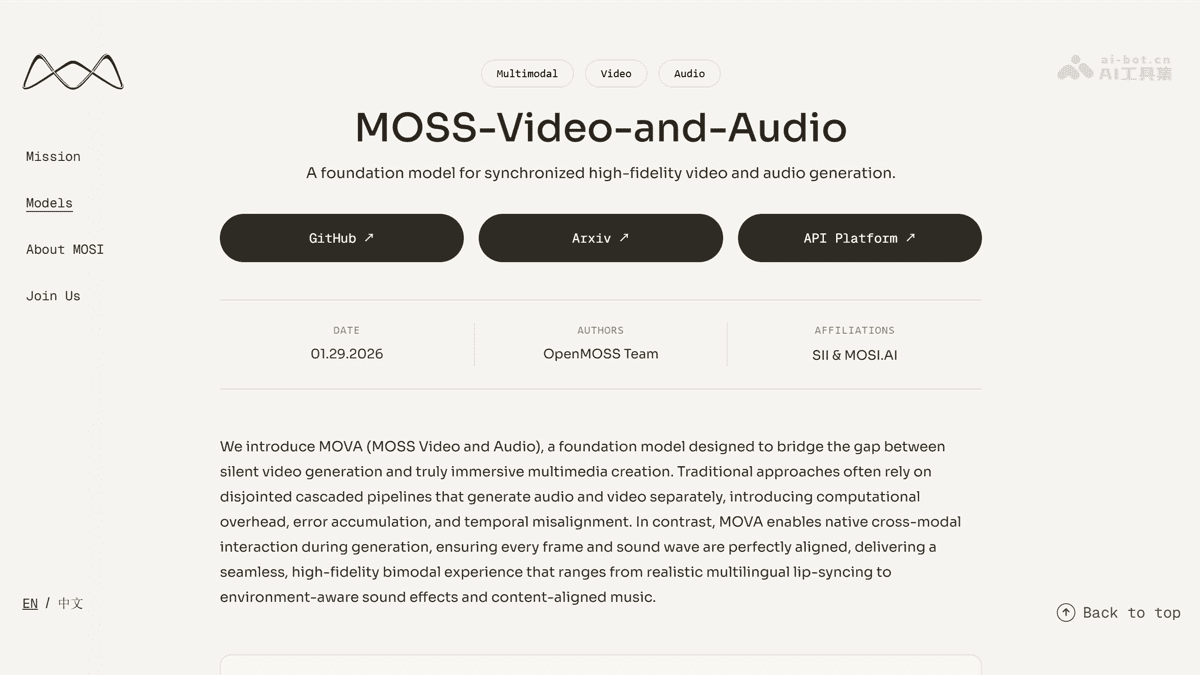
音视频生成技术的范式革新
传统音视频生成模型长期面临两大技术瓶颈:音画不同步导致的沉浸感缺失,以及多模态交互的低效性。MOVA模型的出现标志着中国团队在生成式AI领域的重大突破,其创新采用的异构双塔架构,通过视频扩散模型与音频扩散模型的深度耦合,配合双向桥接模块,实现了原生跨模态交互的技术跃迁。
在参数规模方面,MOVA采用320亿参数的MoE架构(推理激活180亿),在保证计算效率的同时,维持了高质量的生成效果。这种架构设计使得模型能够同步生成8秒时长的720p视频与配套音频,打破了传统生成模型"有画无声"的局限。
技术架构的突破性创新
异构双塔架构的深度解析
MOVA的核心创新在于其独特的异构双塔架构:
- 视频生成塔:配备14B参数的扩散模型,专门处理视觉信息生成
- 音频生成塔:搭载1.3B参数的扩散模型,专注音频信号处理
- 双向桥接模块:实现两塔隐藏状态的交叉注意力融合
这种架构的优势在于,视频生成过程中能实时感知音频节奏,音频生成也能根据画面动态调整。例如在人物对话场景中,模型可精准匹配嘴型与语音的时间节点,实现电影级的口型同步效果。
跨模态时间对齐机制
为解决视频(每秒30帧)与音频(44.1kHz采样率)的采样密度差异,MOVA引入Aligned ROPE机制:
- 建立统一的物理时间坐标系
- 通过精确缩放比例映射不同模态Token
- 实现音视频采样点的精准对应
实验数据显示,该机制将音画同步误差控制在±5毫秒以内,达到专业影视制作标准。
渐进式训练策略的演进路径
MOVA的训练采用三阶段渐进式方案:
- 基础对齐阶段:使用360p低分辨率数据集,使桥接模块快速掌握音视频对齐规律
- 稳定性强化阶段:逐步增加训练数据复杂度,提升多场景下的对齐稳定性
- 画质精修阶段:扩展至720p分辨率进行细节优化
这种策略有效解决了高分辨率下音画对齐的稳定性问题,训练效率提升40%以上。
应用场景的多维拓展
影视制作领域的变革
在电影分镜预览场景中,MOVA展现出显著优势:
- 制作周期缩短70%
- 单个分镜成本降低至传统制作的1/5
- 支持实时调整台词与画面同步效果
某动画工作室测试表明,使用MOVA制作预览片时,导演可即时验证创意构想,极大提升了前期制作效率。
短视频创作的效率革命
针对短视频领域,MOVA提供:
- 智能环境音效生成:自动匹配场景音效(如雨声、脚步声)
- 动态文字渲染:支持任意位置的清晰字幕生成
- 多语言口型适配:覆盖中英日韩等10种语言
数据显示,创作者使用MOVA后,单条视频制作时间从6小时降至45分钟,内容形式丰富度提升3倍。
技术演进的行业启示
MOVA的开源为AI生成技术生态带来深远影响:
- 技术普惠化:研究者可基于开源代码加速算法创新
- 应用标准化:提供统一的端到端音视频生成范式
- 产业协同化:促进影视、游戏、教育等行业的技术融合
值得关注的是,MOVA在HuggingFace平台的模型下载量已突破50万次,社区贡献的改进方案日均新增20+,展现出强大的技术生命力。
未来发展方向
尽管MOVA已取得突破性进展,但仍有提升空间:
- 时长扩展:当前8秒生成时长难以满足长视频需求
- 交互增强:实时生成场景的延迟优化
- 风格控制:更精细的艺术风格定制能力
据项目团队透露,下一代MOVA-X将支持30秒连续生成,并引入动态分辨率调节技术,在保证质量的同时提升计算效率。