深度估计技术迎来突破性进展
在计算机视觉领域,高分辨率深度估计长期面临几何细节失真的技术瓶颈。浙江大学彭思达研究员团队联合理想汽车研究团队,通过创新性提出InfiniDepth框架,成功解决了传统方法在边缘结构、薄物体等复杂几何场景中的精度衰减问题。这项发表于CVPR 2026的研究成果,为自动驾驶环境感知、三维内容生成等应用提供了全新技术范式。
传统方法的技术局限
当前主流深度估计模型普遍采用固定分辨率预测加插值放大的处理流程。这种范式在2K/4K超清场景中暴露明显缺陷:
- 边缘区域深度值过度平滑
- 细长结构空间错位
- 几何连续性受损
- 插值放大导致误差累积
在自动驾驶场景中,这类误差可能引发车道线边界误判、障碍物距离估计偏差等安全隐患。特别是在大视角变换条件下,传统方法生成的三维点云常出现空洞和断裂现象,直接影响场景理解的可靠性。
InfiniDepth创新架构解析
研究团队从深度表示的本质出发,构建了基于神经隐式场的连续深度建模体系。核心技术创新包括:
连续空间映射 将深度值建模为图像坐标的连续函数,突破离散像素网格的分辨率限制,支持任意目标分辨率的深度预测。
多尺度特征融合 引入局部特征查询机制,通过多尺度拉普拉斯能量分析,精准捕捉高频几何特征。在Synth4K数据集测试中,高频区域δ1指标提升达8.5%。
几何感知训练策略 采用随机坐标采样训练方式,结合稀疏深度提示机制,在保持模型泛化能力的同时,实现毫米级尺度估计精度。
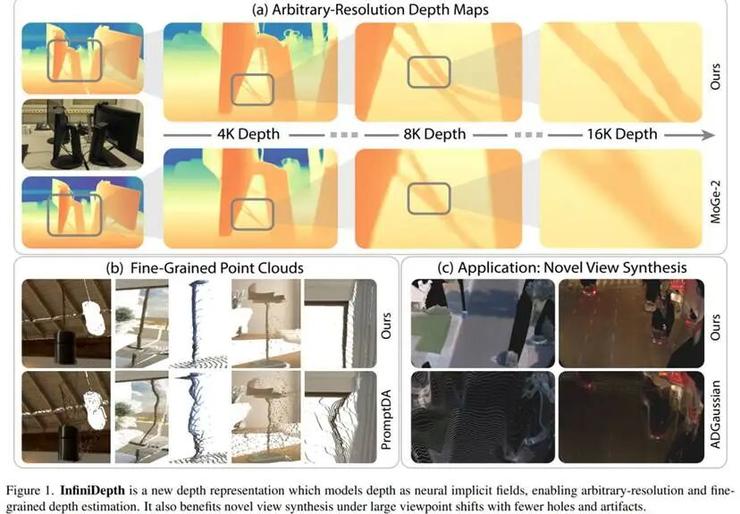
突破性实验验证
为系统评估新方法性能,研究团队构建了Synth4K基准数据集,包含5个高精度游戏场景,覆盖复杂曲面、薄结构等典型挑战案例。在4K分辨率测试中:
| 方法 | Synth4K-1 δ1 | Synth4K-3 δ1 | Synth4K-5 δ1 |
|---|---|---|---|
| DepthAnything | 83.8% | 88.2% | 92.1% |
| InfiniDepth | 89.0% | 93.9% | 96.3% |
在真实场景测试中,模型在KITTI数据集达到97.9%精度,ETH3D数据集表现提升至99.1%,验证了连续表示框架的跨域泛化能力。特别在尺度估计任务中,Synth4K-3高频区域δ0.01指标达37.2%,较现有方法提升12.5个百分点。
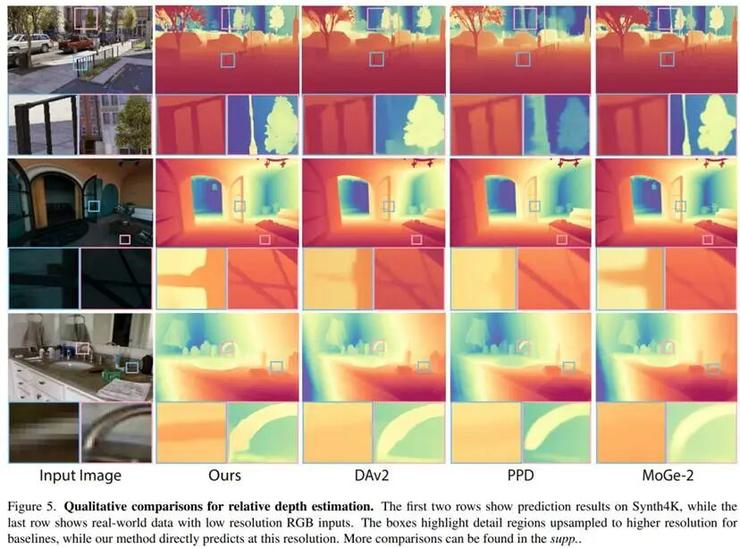
三维应用效能验证
研究团队进一步验证了InfiniDepth在三维重建场景的实际表现:
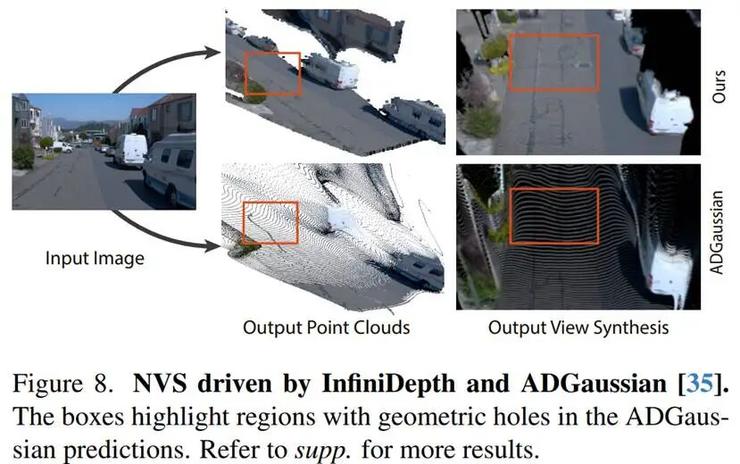
点云重建优化 连续深度表示支持自适应采样密度分配,有效解决传统方法点云分布不均问题。在大视角变换条件下,几何空洞减少63%,断裂现象降低45%。
新视角合成增强 基于改进点云的高斯渲染,在PSNR和SSIM指标上分别提升2.3dB和0.15,视觉效果呈现更完整的几何结构。
动态场景适应 模型在连续视角变换测试中保持98.7%的几何一致性,为自动驾驶系统的多帧融合感知提供可靠基础。
技术演进与产业应用
这项研究揭示了深度表示方式对高分辨率建模的根本性影响。相较于单纯提升模型参数量或训练数据规模,连续隐式建模从表示论角度开辟了新的优化路径。其技术价值体现在:
- 自动驾驶领域:提升障碍物边界检测精度至亚厘米级,增强多传感器融合的数据一致性
- 三维内容生成:为NeRF等神经渲染技术提供更可靠的几何先验
- 机器人导航:改善复杂地形的可通行区域估计,提升路径规划可靠性
- AR/VR应用:实现6DoF场景重建的质量跃升
彭思达团队在论文中强调,未来研究方向将聚焦动态场景建模和大规模三维重建的工程化应用。该团队已在GitHub开源部分核心代码,并计划与自动驾驶企业合作推进实测验证。
技术启示与行业影响
InfiniDepth的提出标志着深度估计技术从"分辨率竞赛"向"几何保真"的范式转变。其核心贡献在于:
- 建立连续深度建模的理论框架,突破传统离散表示的物理限制
- 提供高精度几何建模的基准工具,推动三维视觉任务的技术革新
- 验证隐式神经表示在实际工程场景的可行性,拓展AI视觉的应用边界
这项研究为计算机视觉领域提供了重要的方法论创新,其影响将辐射自动驾驶、智能制造、数字孪生等多个产业领域。随着技术的持续演进,高精度环境感知能力的提升,将加速推动智能系统从"看得见"向"看得准"的跨越发展。