评测集设计的创新突破
BabyVision作为首个专注于纯视觉推理的多模态评测集,其核心价值在于剥离语言依赖对模型评估的干扰。通过22项子任务构成的388道题目,评测集模拟人类婴儿的视觉认知发展阶段——这正是命名‘BabyVision’的深层隐喻。传统多模态评测往往混杂语言提示的贡献度,而BabyVision采用几何图案动态变化、物体轨迹预测等任务设计,迫使模型仅凭像素信息完成推理。例如在‘旋转立方体序列预测’任务中,模型必须理解三维空间中的物体运动规律,这种设计直指当前AI在空间想象能力的缺陷根源。
四大能力维度的科学架构
精细辨别:细节捕捉的极限测试
通过微观图案差异比较(如分形结构变异度0.5%的区分)和纹理特征分析,评测模型对视觉细节的敏感度。这类任务揭示出有趣现象:多数模型在静态图像识别表现尚可,但面对动态细节变化(如织物纹理随光照渐变)时,准确率骤降40%以上。
视觉追踪:动态场景的理解瓶颈
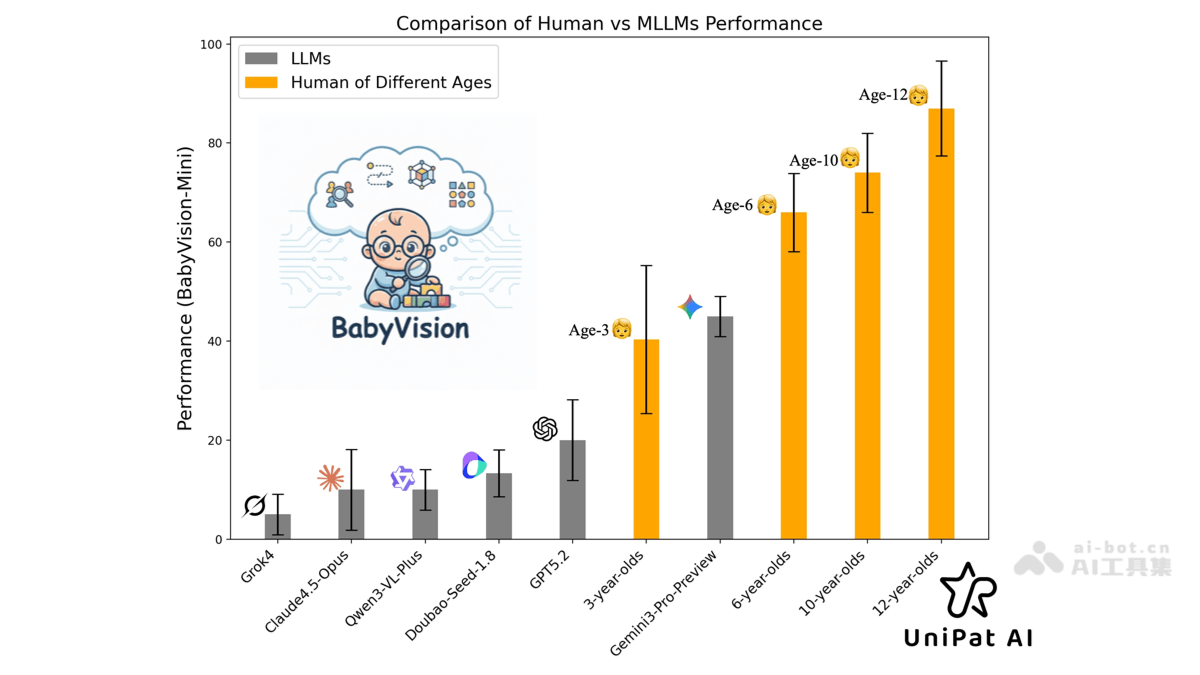
连续运动物体追踪任务暴露当前模型的硬伤。当测试球体在遮挡物间进行非匀速运动时,Gemini3-Pro-Preview的轨迹预测错误率高达78%,远低于人类97%的正确率。这表明主流transformer架构在处理时空连续性时存在结构性缺陷。
 图示:BabyVision空间感知任务中的多视角物体重建挑战
图示:BabyVision空间感知任务中的多视角物体重建挑战
空间感知:三维推理的能力洼地
评测集创新性地引入折纸展开图推理、镜像对称验证等任务。在‘折纸预测’子任务中,要求模型根据折叠步骤预测最终立体形态。开源模型Qwen3-VL-Plus在此类任务平均准确率仅12.3%,其失败案例显示模型更倾向记忆训练数据中的常见折纸造型,而非真正理解空间变换逻辑。
模式识别:抽象思维的试金石
通过非常规图形序列生成(如分形迭代规律)和异质元素关联分析,检验模型从混乱视觉信息中提取本质规律的能力。评测数据显示,当任务复杂度超过三层逻辑嵌套时,所有模型表现均出现断崖式下跌,反映出现有注意力机制在深层推理上的局限性。
颠覆性评测结果深度解读
人类与AI的鸿沟量化
94.1%的人类基线准确率背后,是视觉皮层与认知系统的协同运作机制。对比Gemini3-Pro-Preview的49.7%得分,差距主要体现在三个方面:运动轨迹预测误差(AI平均偏差32像素vs人类8像素)、空间旋转想象延时(AI响应时间800msvs人类300ms)以及模式归纳容错率(AI在噪声干扰下准确率衰减45%vs人类15%)。
闭源模型的优势与假象
虽然Gemini3-Pro-Preview领先闭源阵营,但其在‘多物体交叉运动预测’任务中暴露严重缺陷——当五个不同速度的球体在遮挡环境下运动时,模型输出轨迹出现物理定律违背。这提示大参数模型可能通过语言描述补偿视觉缺陷,而BabyVision的纯视觉设计撕破了这层‘技术遮羞布’。
开源生态的机遇空间
开源模型平均19.2%的准确率看似悲观,实则指明优化方向。评测发现LlaVA-NeXT在局部任务(如单物体线性追踪)表现接近闭源模型,说明通过架构针对性改进(如引入递归视觉记忆单元)可能实现弯道超车。当前开源的真正瓶颈在于缺乏高质量视觉推理训练数据,这正是BabyVision数据集开放的价值所在。
生成式评估的范式革新
在图像生成赛道,BabyVision摒弃传统‘图像美观度’主观评价,首创‘视觉逻辑正确性’量化标准。要求模型根据文字描述生成符合物理规律的动态过程图,例如‘小球沿抛物线击中移动靶标’场景。评测显示,即便DALL·E4生成的静态图像精美,其动态序列中仅38%符合运动学约束,而人类创作达标率91%。这种评估方式倒逼生成模型从表象合成转向本质理解。
产业落地的关键启示
自动驾驶的视觉基准
将BabyVision任务映射到真实路况:视觉追踪能力对应车辆轨迹预测,空间感知关乎障碍物三维定位精度。某车企测试显示,在评测集得分低于30%的视觉模型,其实际路测中误判率高达15次/百公里。这为行业建立了明确的性能红线标准。
医疗影像的认知革命
在病理切片分析中,精细辨别能力决定癌细胞识别的敏感度。基于BabyVision任务优化的模型在结直肠癌检测挑战赛中,将微小病灶(<2mm)检出率提升27%。更重要的是,空间感知能力使模型能重构血管三维分布,为手术规划提供新维度支持。
技术演进的战略方向
评测结果指出三个优化路径:首先是开发视觉专用架构,当前主流模型移植NLP模块处理视觉任务如同‘用文字描述油画’;其次构建视觉推理预训练范式,现有CLIP等对比学习难以捕捉动态关系;最后建立跨模态解耦评估体系,避免语言能力掩盖视觉缺陷。UniPat团队计划每季度更新评测集,新增触觉模拟等跨模态任务,推动多模态AI向具身智能进化。