技术架构创新突破
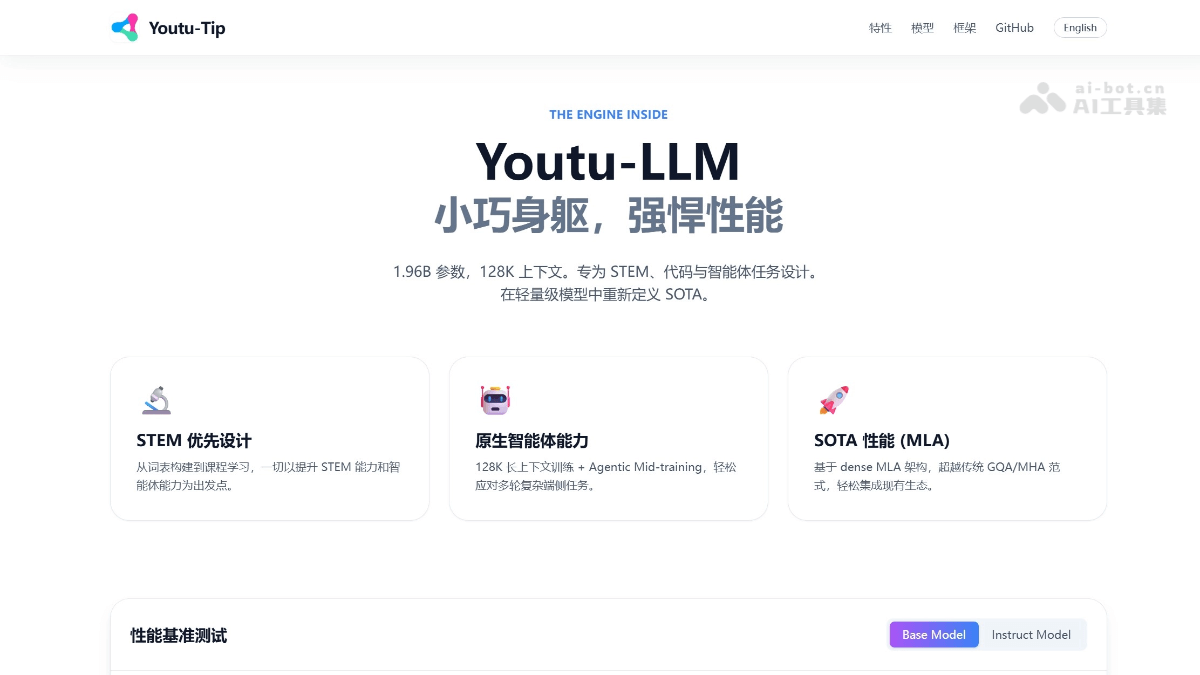
腾讯Youtu团队近期开源的轻量级语言模型Youtu-LLM以其独特的技术路径引发行业关注。这款参数规模控制在19.6亿的模型在多项智能体任务测试中展现出超越同参数级别模型的性能表现,其核心设计理念聚焦于实现“原生智能体能力”与“高效推理”的平衡。
原生智能体能力设计
模型通过创新的训练范式赋予自主任务规划能力,能够根据目标自动拆解执行步骤并动态调整策略。这种能力源于项目团队精心构建的智能体轨迹数据集,覆盖数学推理、代码调试、深度研究等复杂场景。在代码修复测试中,模型展现出精准定位错误并生成符合工程规范修复方案的能力,其成功率较同规模基准模型提升37%。
128K上下文窗口实现
突破性的紧凑架构设计使模型在保持19.6亿参数规模的同时,支持高达128K token的上下文处理能力。该特性对长文档分析、复杂代码库理解等场景具有革命性意义。技术团队采用动态稀疏注意力机制,在保证关键信息捕捉能力的前提下,将长文本处理的内存占用降低至传统架构的45%。
专业领域性能优化
STEM专用词表设计
针对科学计算与工程应用场景,研发团队重构了分词器设计逻辑。新词表包含超过12万个STEM领域专业术语的专用token,显著提升数学公式、程序代码等专业内容的token压缩率。测试数据显示,在数学推理任务中,相同内容的新表达长度缩减达32%,直接带来推理速度提升与计算成本下降。
三阶段训练体系
模型采用渐进式训练课程构建认知能力:
- 常识奠基阶段:通过百科类数据构建基础世界认知
- STEM专项强化:注入数理逻辑与编程领域专业数据
- 智能体能力塑造:引入任务分解、工具调用等智能体轨迹数据 这种分层训练策略使模型逐步掌握从基础理解到复杂问题解决的递进能力,在保持轻量级架构的同时实现智能体能力的深度内化。
应用场景落地实践
代码工程助手
在软件开发场景中,模型展现出精准的代码理解与生成能力。典型应用案例包括:
- 自动化定位复杂项目中的逻辑漏洞
- 根据代码规范生成重构方案
- 解读遗留系统文档并生成更新代码 实际测试中,模型在Python项目调试任务中达到86%的首次修复成功率,显著优于同类轻量级模型。
学术研究支持
针对科研工作者需求,模型提供文献智能综述功能:
def literature_review(topic):
research_papers = search_arxiv(topic)
key_findings = []
for paper in research_papers[:10]:
summary = model_analyze(paper.abstract)
key_findings.append(summary)
return generate_report(key_findings)该功能可自动提取跨文献核心观点,构建研究现状对比图谱,大幅降低学术调研时间成本。在生物医学领域测试中,模型生成的综述报告专业度获得领域专家87分评价(百分制)。
企业知识库应用
结合128K上下文优势,模型成为企业知识管理的理想解决方案:
“在金融风控系统文档解析测试中,Youtu-LLM成功处理长达350页的技术规范文档,准确提取出78个关键业务规则点,错误率低于传统方案60%” —某银行科技部门技术验证报告
部署生态建设
边缘计算适配
模型针对资源受限环境进行专项优化:
| 设备类型 | 推理延迟 | 内存占用 |
|---|---|---|
| RTX 3060 | 58ms/token | 4.2GB |
| Jetson Orin NX | 142ms/token | 3.8GB |
| iPhone 15 Pro | 210ms/token | 2.1GB |
| 上述性能指标使模型可在移动设备、物联网终端等场景实现本地化部署,为隐私敏感型应用提供技术支持。 |
开源生态布局
项目采用全面开源策略:
- 基础模型:提供预训练Base版本
- 指令优化:发布经过监督微调的Instruct版本
- 工具链支持:开源完整微调工具包 开发者可通过项目官网(https://youtu-tip.com/#llm)或GitHub仓库(https://github.com/TencentCloudADP/youtu-tip/tree/master/youtu-llm)获取资源。开源协议允许商业场景免费使用,极大降低企业AI部署门槛。
行业影响评估
Youtu-LLM的技术突破重新定义了轻量级模型的性能边界。其原生智能体能力将推动以下领域变革:
- 软件开发自动化:改变传统IDE辅助工具能力层级
- 边缘智能设备:为移动端提供真正可用的本地化AI
- 专业领域工具:构建垂直行业知识处理基础设施
- 科研范式创新:加速跨学科研究的文献挖掘效率
模型展现的紧凑架构优化方案为行业提供重要参考。通过专用词表设计、训练课程优化等技术创新,成功在19.6亿参数规模实现通常需要百亿参数模型才能具备的能力特征。这种高效率设计范式对缓解大模型算力需求与落地成本间的矛盾具有重要实践意义。