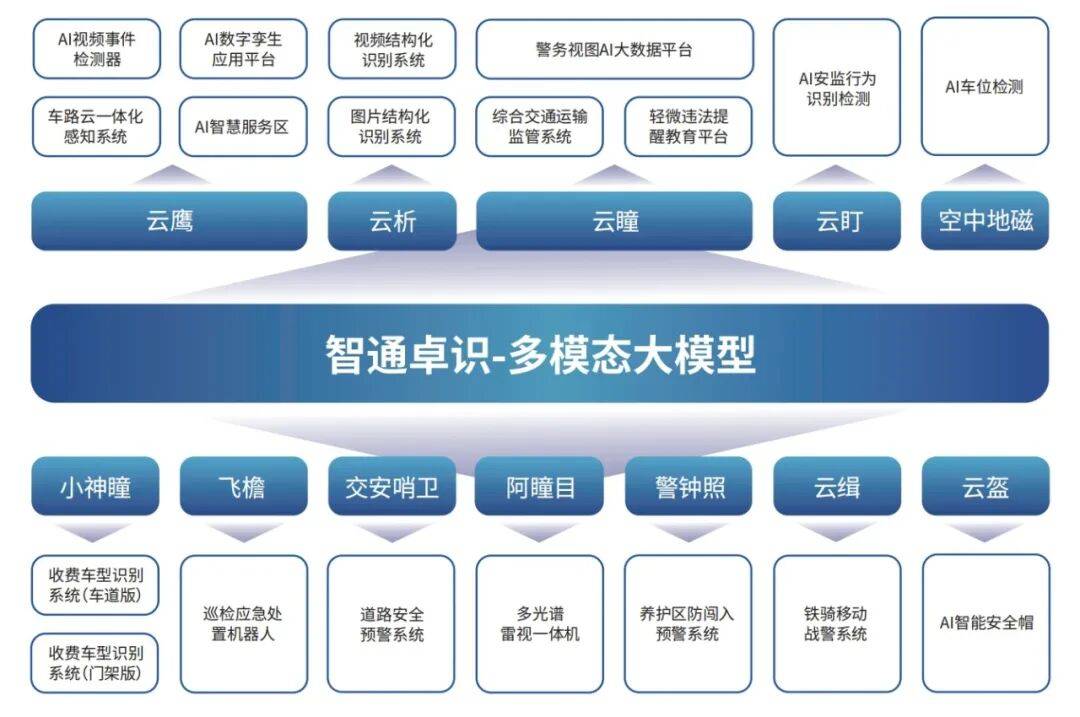
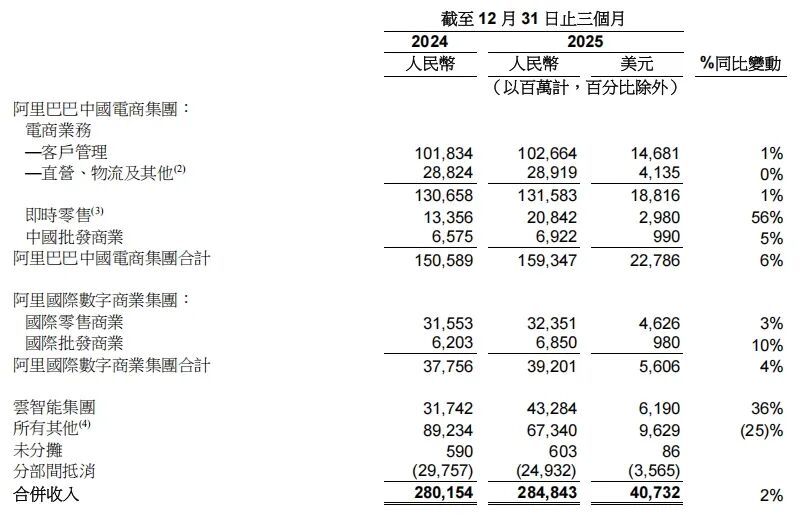
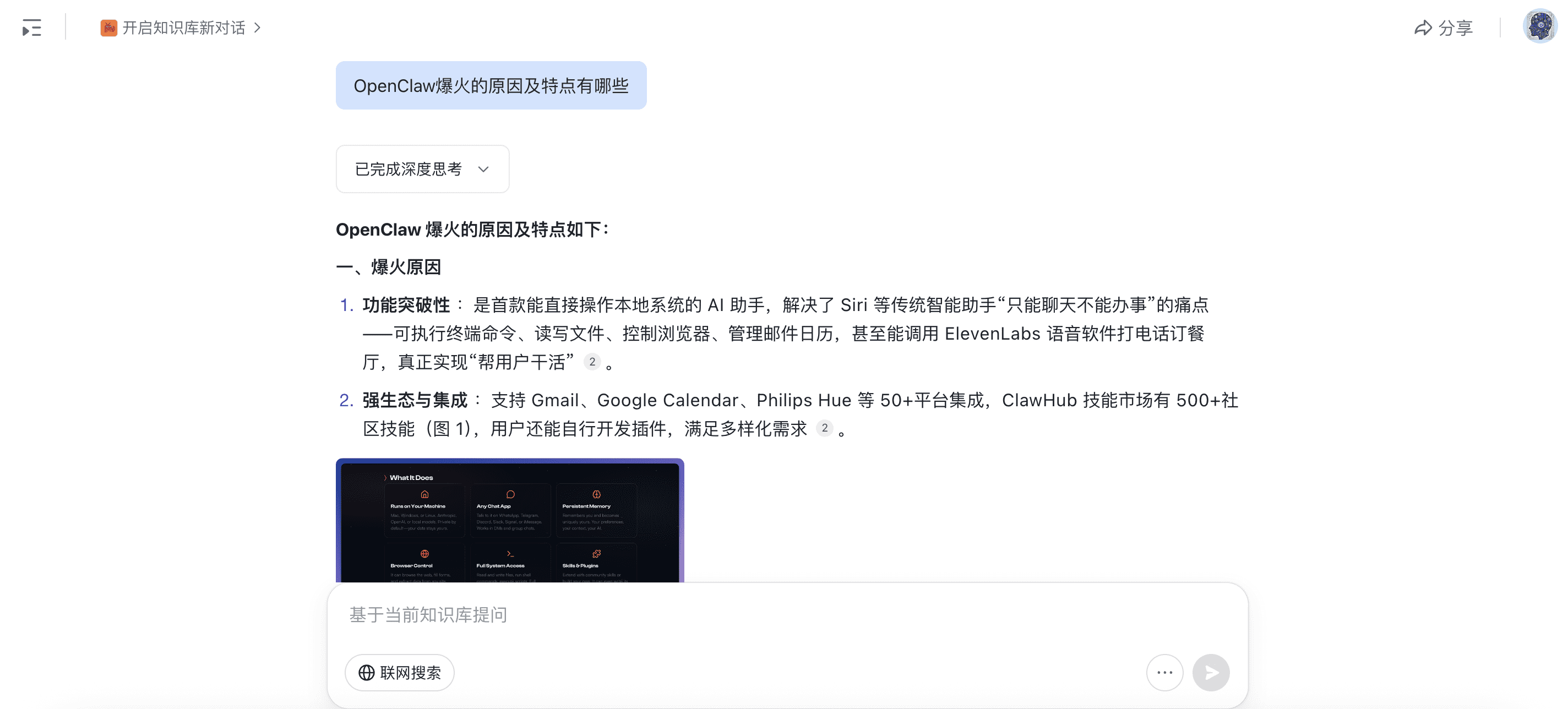
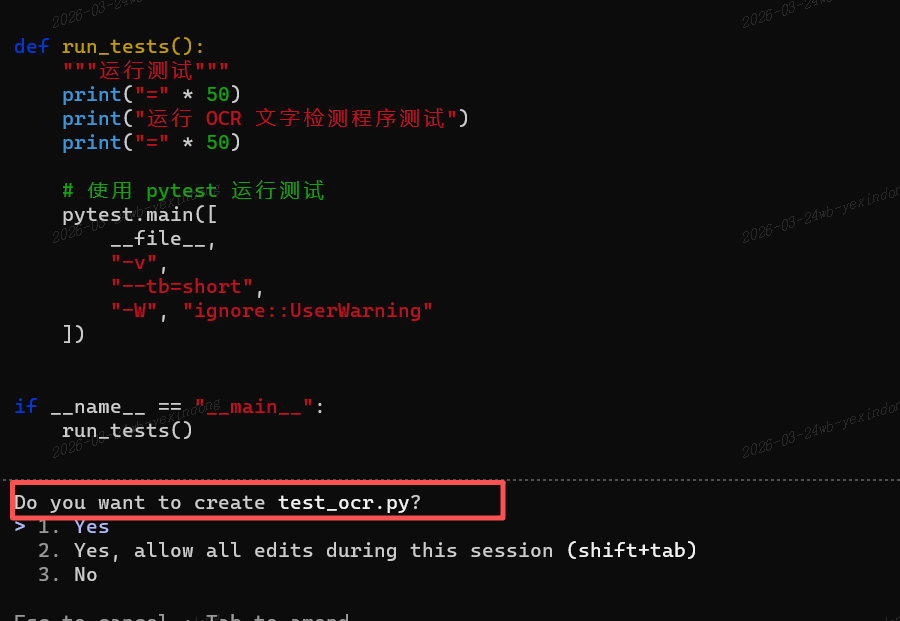
技术架构创新解析
该模型的核心创新在于视觉编码器的架构设计。通过22层窗口注意力层与4层全注意力层的交替堆叠,既保证了细粒度特征提取能力,又维持了计算效率的平衡。这种分层结构使得模型在处理720P高清图像时,推理时延可控制在160毫秒以内,较传统架构提升15%的吞吐量。
在坐标定位系统设计上,研发团队创造性地采用000-999千分位带填充相对坐标表示法。这种数值化处理方式将二维空间坐标转换为线性序列,显著降低了模型的学习难度。实际测试数据显示,在复杂场景目标定位任务中,定位精度较传统方案提升23%。
混合训练策略突破
为平衡不同长度样本的学习效果,模型采用加权逐样本损失与逐令牌损失的混合训练机制。这种双损失函数设计有效解决了长文本与短指令样本之间的学习偏差问题,在文档理解任务中,Markdown格式转换准确率达到91.7%。
在预训练阶段,团队完成3T+ tokens规模的集群训练,创新性地采用无突刺训练策略。这种稳定性控制技术确保在大规模分布式训练过程中,各节点参数更新保持同步,为后续微调提供了优质的基础模型。
工业场景应用实践
在智能制造领域,该模型已成功应用于精密零部件检测场景。通过实时视频流分析,系统可同时完成零件定位、缺陷检测和数量统计三项任务。某汽车零部件厂商的实测数据显示,检测效率较传统机器视觉方案提升40%,误检率降低至0.3%以下。
智能文档处理模块支持将扫描件中的表格自动转换为Markdown格式,并保持原有排版结构。这项功能在金融合同处理场景中,将人工录入工作量减少85%,且支持PDF、JPG等多种格式的混合输入。
端侧部署优化方案
针对昇腾310系列芯片的端侧部署需求,模型提供动态分辨率适配技术。该技术可根据设备算力自动调整输入图像分辨率,在保持识别精度的前提下,将内存占用降低30%。配合昇腾芯片的专用计算单元,使得4G内存设备也能流畅运行多模态推理任务。
在视频理解任务中,模型采用关键帧抽取与时空特征融合技术。通过分析短视频中的关键动作帧,结合时间维度特征,可将10秒短视频的内容理解耗时控制在500毫秒以内。这项技术已应用于电商平台的短视频内容审核系统,日均处理量达百万级。