01 当AI开始"健忘":用户体验背后的技术真相
日常使用AI助手时,经常会遇到令人啼笑皆非的场景:第一轮对话中明确告知自己海鲜过敏,到了第五轮咨询晚餐推荐时,模型却完全"忘记"了这个关键禁忌;或者刚刚表述完复杂的售后需求,切换到下一个对话窗口后就被要求重新描述问题。这些看似滑稽的交互失误,并非AI在"调皮",而是暴露了当前通用大语言模型在记忆机制上的先天缺陷。
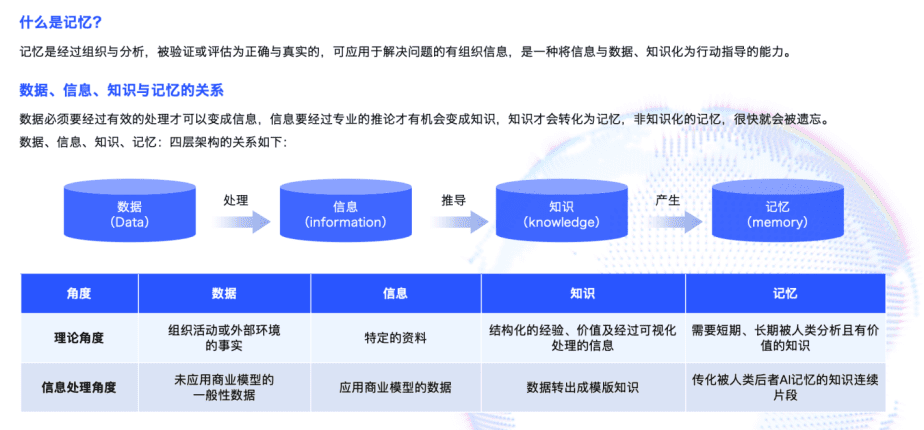
深入分析这些问题的本质,会发现大模型的"记忆缺陷"并非单一技术局限,而是多重技术挑战叠加的结果。主流大模型的上下文窗口通常限制在100k-200k tokens,随着对话轮次增加,早期关键信息容易被新的对话内容"挤出",这种现象在技术领域被称为"上下文挤出效应"。就像人类短期记忆容量有限一样,当新信息不断涌入时,旧记忆自然会被边缘化甚至遗忘。
更复杂的是,在企业级应用中,往往存在多个智能Agent协同工作的场景。咨询、售后、推荐等不同模块各自维护独立的记忆系统,彼此之间缺乏有效的数据共享机制,导致用户在不同服务场景间切换时需要反复提供相同信息。这种"数据孤岛"现象不仅严重影响用户体验,还会造成token资源的无效消耗,增加企业运营成本。
语义解析层面的挑战同样不容忽视。用户的表达习惯千差万别,模糊指代、口语化表达、多语种混用等情况非常普遍,这使得模型在定位和调用历史记忆时常常出现偏差。当用户的"我想要那个"无法准确对应到前文提到的具体物品时,记忆再精准也无法发挥作用。
这些问题直接制约着AI向"认知级个性化服务"的演进。在需要精准记忆的客服、医疗、教育等严肃场景中,大模型的记忆缺陷更是成为商业落地的核心障碍。企业不得不面对一个两难选择:要么忍受低质量的AI服务,要么投入大量资源进行人工干预和校准。
02 破局之道:借鉴人脑记忆机制的创新路径
针对大模型记忆困境,全球范围内的技术团队已经展开多轮探索。Meta FAIR实验室曾联合高校团队通过参数微调的方式优化模型性能,试图通过调整模型内部参数来增强记忆能力。然而这种方法面临一个根本性限制——新增参数容量有限,难以承载大量新知识,甚至可能导致模型出现"灾难式遗忘",即在学习新知识的同时丢失原有能力。美国和韩国的多个AI创业企业也尝试过类似路径,但始终未能找到平衡点。
传统解决方案的局限性在于,它们仍然在"修补"现有架构,而没有从根本上重构记忆系统。要真正突破大模型"准确率低、成本高、幻觉多、延迟高"的四重瓶颈,需要全新的思维范式。
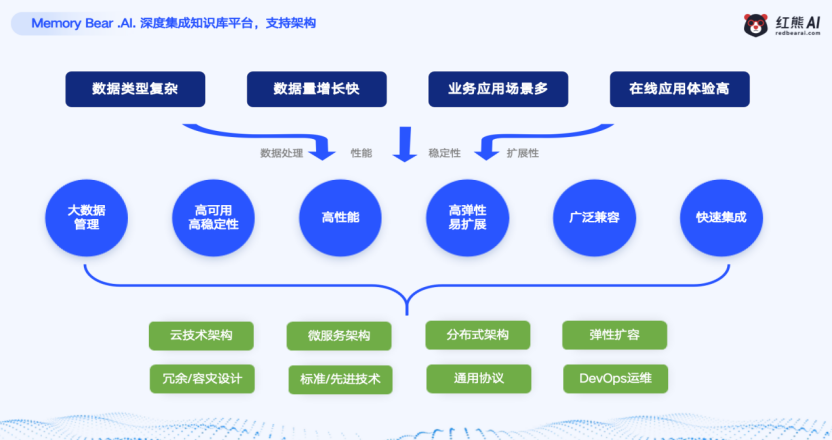
最近,一种借鉴人类大脑"海马体-皮层"协作机制的创新方案开始崭露头角。人类大脑中,海马体负责记忆的形成和短期存储,而大脑皮层则负责长期记忆的巩固和检索。两者分工明确又密切配合,构成了人类强大的记忆系统。如果能将这一机制移植到AI系统中,理论上就能解决大模型的记忆困境。
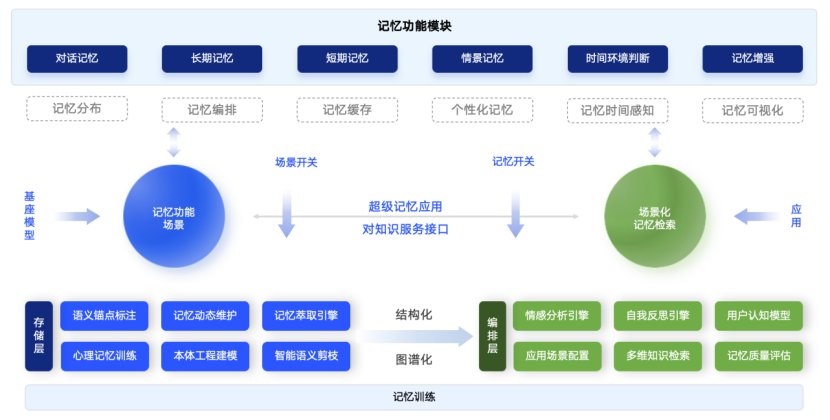
基于这一思路,技术团队构建了一套分层、动态、可演进的记忆体系。这套体系复刻了人类感知记忆、工作记忆、显性记忆、隐性记忆、情绪记忆五大模块,形成了从"数据输入"到"认知输出"的完整闭环。其中,显性记忆层通过结构化数据库存储可主动调用的信息,包括用户历史对话和行业知识库,支持精准查询与检索;隐性记忆层则作为独立于大模型参数的外部组件,专门管理AI的行为习惯、任务技能与决策偏好,使其能"无意识"地高效处理重复任务,类似人类的肌肉记忆。
这种设计的精妙之处在于,既保证了关键信息的精准存储,又实现了行为模式的自主优化。就像人类通过练习形成肌肉记忆一样,AI系统可以通过隐性记忆层自动积累处理经验,不断提升任务执行效率,而无需每次都经过复杂的推理计算。
03 核心技术突破:从静态存储到动态智能
传统AI记忆系统主要依赖关键词匹配进行信息检索,这种方式虽然简单直接,但无法理解用户表达背后的真实意图。新一代智能记忆系统通过构建动态语义网络,彻底打破了这一局限。
动态语义网络的核心价值在于实现了联想式记忆检索。举例来说,当用户提到"咖啡"时,系统不仅能找到用户历史对话中关于咖啡的直接记录,还能通过语义关联发现用户的"早晨通勤习惯",再结合当天的天气数据,智能判断用户此时更倾向于热咖啡还是冰咖啡。这种层层递进的联想能力,让AI开始真正理解用户的隐含需求,而不是机械地匹配关键词。
针对长期困扰业界的"高耗低效"问题,智能语义剪枝技术提供了创新解决方案。这项技术能够在保持语义完整性的前提下,精准识别并剔除冗余信息,实现97%的token效率提升和72%的语境偏移率降低。在实际应用中,这意味着AI可以用更少的计算资源处理更复杂的记忆任务,大幅降低企业使用成本。
幻觉问题一直是影响AI可靠性的核心痛点。通过语义锚点标注和多维检索引擎的组合应用,新方案有效抑制了幻觉生成的可能性。语义锚点为关键信息建立了"指纹"标记,系统在检索时可以快速验证信息的真实性和相关性;多维检索则从语义、时间、情感等多个维度交叉验证,确保输出结果的可信度。
存储与检索层面的优化同样值得关注。自我反思引擎借鉴了人类睡眠中强化记忆的神经科学原理,在离线周期中对记忆进行系统性梳理、重排和重要度重估。就像人类在睡眠中整理白天经历一样,AI系统可以在"休息"时优化记忆结构,提升长期表现。结合记忆遗忘引擎,系统能够在持续增量学习的同时保持稳定性,实现学习效率与抗遗忘能力之间的精妙平衡。
跨Agent协作难题也通过记忆共享引擎得到了彻底解决。统一的记忆中枢打破了不同智能体间的"数据孤岛",当用户在咨询、售后、推荐等场景间切换时,对话状态、历史偏好、关键诉求等信息可以实现无缝传递。用户无需重复描述,真正实现了"一次沟通,全程复用"的流畅体验。
04 性能验证:从实验室到市场的跨越
技术创新的价值最终需要通过实际数据来验证。在权威的LOCOMO数据集测试中,基于新型记忆机制的解决方案在核心指标上全面超越了Mem0、Zep、LangMem等现有主流方案,展现出压倒性的技术优势。基于图谱的版本将搜索延迟p50控制在0.637秒,成功破解了"高准确必伴随高延迟"的行业魔咒。

实验室数据固然重要,但商业场景中的实际表现更具说服力。某AI Agent互动服务平台接入该记忆系统后,实现了98.4%的AI自助解决率和70%的人工替代率。这意味着绝大多数用户问题都可以由AI独立处理,大幅降低了企业的人力成本,同时用户满意度也得到显著提升。
智能客服是该技术应用最成熟的场景之一。系统为每位用户创建动态记忆图谱,通过回溯过往交互历史与情感状态,实现跨Agent记忆共享。客服人员可以借助实时上下文推荐,将服务模式从被动响应转变为主动关怀。当系统识别到用户连续几次查询同类问题时,会自动提示客服人员可能存在深层次需求,从而提供更有针对性的解决方案。
05 场景落地:六大领域的深度变革
记忆技术的进步正在为多个行业带来实质性的业务价值。在精准营销领域,这项技术让"猜你喜欢"真正升级为"我记得你喜欢"。系统通过构建用户兴趣记忆图谱,追踪从首次点击到复购的完整旅程,实现超个性化推荐。某电商平台的实际应用数据显示,采用新记忆系统后,推荐准确率提升了35%,用户购买转化率提高了28%。
AI教育场景的变化同样令人印象深刻。传统在线教育系统往往只能记录学生的答题结果,而新一代记忆系统能够记住学生的每一次答题犹豫、学习方式偏好和情绪状态变化。当AI发现学生在解决某一类型问题时经常停顿思考,就会主动调整教学策略,提供更细致的步骤讲解。这种真正意义上的因材施教,让AI导师成为了每个学生的专属学习伙伴。
数字医疗领域的应用更是体现了记忆技术的社会价值。通过创建集中化的病史记忆,系统可以整合症状变化、过敏史、既往用药等关键信息,为医生提供全面的患者视图。这不仅有效解决了病史分散、复诊重复沟通的行业痛点,还能通过时间序列分析发现潜在的疾病发展趋势,为早期干预提供决策支持。
电商和零售场景的变革则更加直观。记忆系统通过分析用户浏览深度、加购行为、退货原因等多维度数据,精准建模用户的真实需求,实现秒级人货匹配。线下零售店则为每位VIP客户创建持久记忆档案,记录尺码、风格偏好与过往购买记录,无论员工流动还是跨门店服务,都能即时访问客户记忆,为线下零售注入了前所未有的个性化服务能力。
06 开放生态:推动行业协同进步
技术发展的最终目标是服务整个行业。通过开源核心记忆技术框架,开发者社区可以基于这一基础架构进行二次创新,加速技术迭代和应用探索。开源模式不仅能吸引更多人才参与记忆科学的研究,还能促进不同技术路线的交流融合,推动整个行业向前发展。
下一步的发展方向将聚焦于两个关键维度:一是深化与多模态大模型的融合,让AI不仅能够记住文本信息,还能有效处理图像、语音、视频等多模态记忆;二是优化订阅制服务模式,根据不同企业的实际需求提供更灵活、更经济的解决方案。预计未来一年内,基于记忆科学的AI应用将迎来爆发式增长,企业订阅服务市场有望实现50倍的业务扩张。
从长远来看,AI记忆技术的发展愿景是让人工智能从"工具级服务"真正迈向"伙伴级服务"。未来的AI将不再是机械执行指令的工具,而是能够理解用户、持续学习、共同成长的可靠伙伴。它就像一个无时无刻不在的朋友,"无处不在,又无处可见"——在你需要的时候恰到好处地提供帮助,在你不需要的时候安静地守候在一旁。
这场关于AI记忆的技术革命,不仅提升了大模型的智能化水平,更在重新定义人与AI的关系边界。当AI开始"记得"我们,它就不再是冰冷的机器,而真正成为了数字时代的认知伙伴。这个过程或许刚刚开始,但未来已经清晰可见。