DeepSeek V4落地峰谷定价:AI算力成本优化与技术加速的双重博弈
随着人工智能基础设施从单纯的模型竞赛转向精细化运营阶段,核心参数的调整往往能折射出行业发展的深层逻辑。DeepSeek近期宣布的V4正式版上线计划及其配套的峰谷定价策略,不仅是产品迭代的节点,更是算力经济学在应用层的一次典型实践。与此同时,其联合北京大学发布的DSpark推理加速框架,展示了在算法效率与工程落地之间寻找平衡的技术路径。这两者看似独立,实则共同指向了一个核心议题:在算力需求呈指数级增长的当下,如何通过机制创新与技术优化,实现性能与成本的双重可控。
商业化压力下的定价机制重构
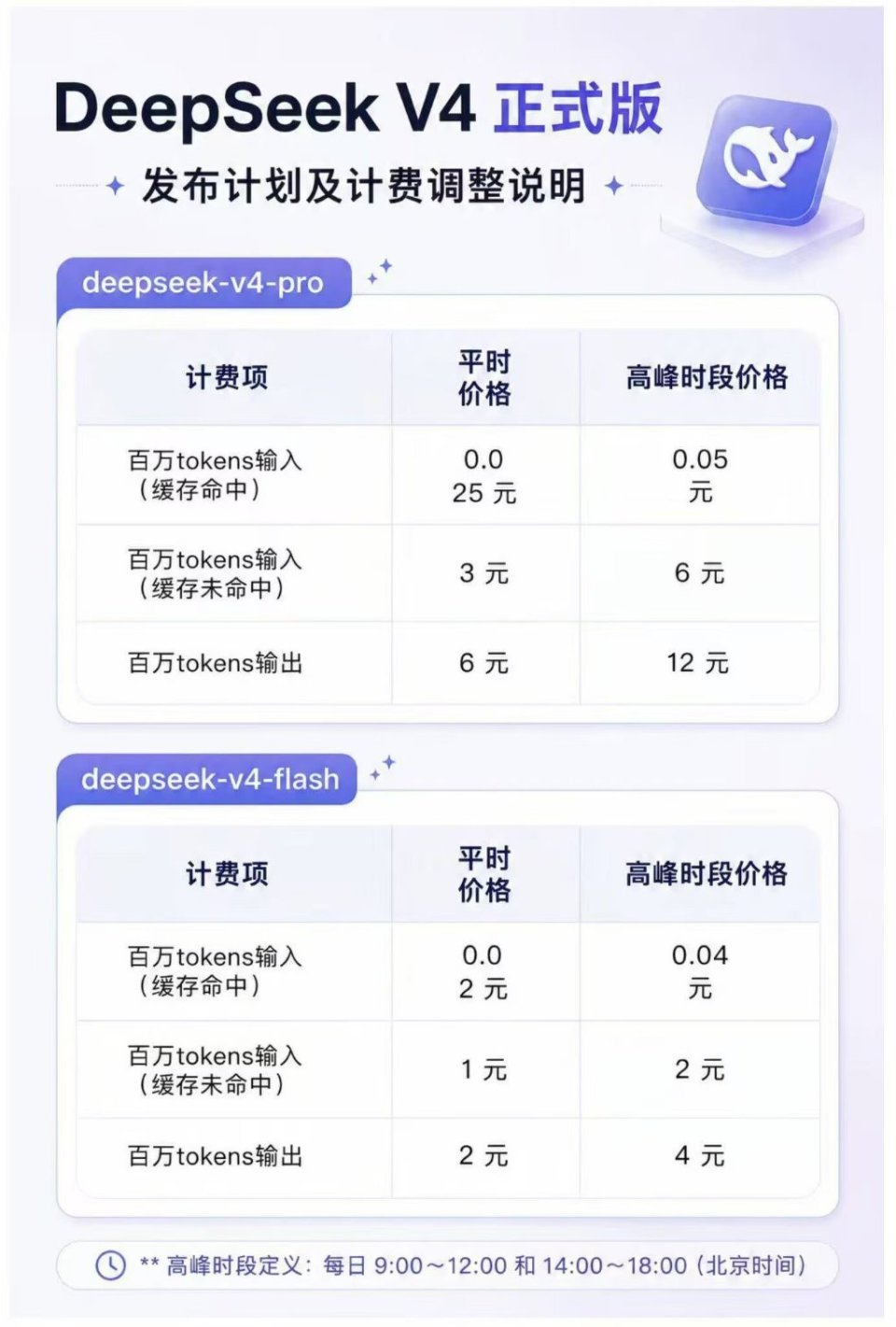
DeepSeek V4正式版的定档7月中旬,标志着这一基于百万字超长上下文构建的模型即将从预览期的技术验证走向大规模商用。V4系列划分为旗舰版V4-Pro与轻量版V4-Flash,前者拥有1.6万亿总参数量,后者则为284B,两者均支持1M上下文窗口,覆盖了从深度复杂推理到高频轻量交互的全场景需求。然而,真正引发市场关注的并非模型参数的堆叠,而是同步推出的峰谷定价机制。

这一机制将每日API调用成本切割为两个截然不同的层级。在每日上午9时至12时、下午2时至6时的高峰时段,API价格直接翻倍至平时水平的两倍;而在非高峰时段,价格则维持现行水平不变。官方解释称,此举旨在更合理地配置资源并提升服务稳定性。从行业视角来看,这是一种典型的通过价格杠杆调节供需关系的策略。
对于依赖API进行实时交互的企业用户而言,这种定价模式直接推高了工作时段的使用成本。传统上,企业倾向于在业务高峰期集中调用模型以响应客户需求,但峰谷定价迫使开发者重新审视其资源调度策略。成本压力的传导将迫使企业在架构层面进行优化,例如将非实时性的批量任务(如数据分析、内容预生成)迁移至凌晨等低峰时段执行,从而在维持原有预算水平的前提下保障业务连续性。
这种定价策略也反映出头部模型厂商在融资扩张后的商业化焦虑。DeepSeek在完成500亿元融资后,面临巨大的营收变现压力。通过峰谷定价,厂商不仅能在高峰时段通过溢价获取更高收益,更能通过价格信号引导用户行为,平滑服务器负载曲线,降低因瞬时并发过高导致的系统延迟或宕机风险。这是一种将外部成本内部化,并通过市场机制进行再分配的成熟做法。
技术突围:DSpark框架的工程化价值
在商业策略收紧的同时,DeepSeek在技术层面却呈现出显著的开倒车式慷慨。6月27日,公司联合北京大学发布了推理加速框架DSpark,并同步开源了全栈推测性解码工具链DeepSpec。这是DeepSeek完成巨额融资后首次对外披露的开源技术成果,其背后透露出的信号值得玩味。
DSpark的核心突破在于对推测性解码(Speculative Decoding)技术的工程化落地。推测性解码的基本逻辑是利用一个小模型快速生成候选Token(草稿),再由大模型并行验证,从而在不牺牲生成质量的前提下提升速度。然而,该技术在实际落地中一直面临两大瓶颈:并行生成的“后缀衰减”问题以及全量验证带来的算力浪费。
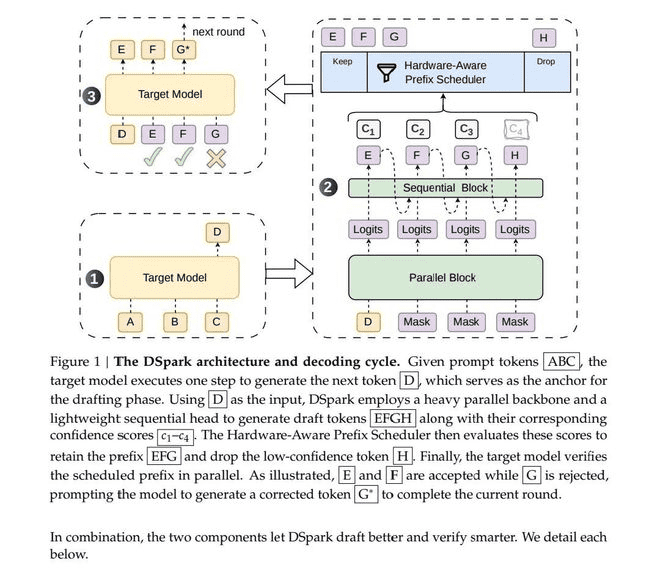
DSpark针对“后缀衰减”提出了半自回归生成架构。在传统的并行生成中,各个位置的Token缺乏依赖约束,导致错误随序列长度累积,验证接受率急剧下降。DSpark采用“并行主干+轻量串行头”的两阶段设计,既保留了并行计算的速度优势,又通过串行模块补充相邻Token间的语义依赖,有效修正了冲突。实测数据显示,2层深度的DSpark在有效接受长度上甚至超越了5层深度的纯并行方案,这证明了工程架构优化在突破理论极限中的关键作用。
另一大创新在于置信度调度验证机制。为解决全量验证导致的算力冗余,DSpark引入了置信度评分模块,实时预测每个候选Token的条件接受概率。通过“顺序温度缩放”校准方法,该框架将评分误差从3%-8%大幅压缩至约1%。在此基础上,调度器能够根据实时负载动态调整验证长度:在低并发时最大化利用算力,而在高并发时主动裁剪低价值Token,避免资源争抢。这一机制使得V4-Flash单用户生成速度提升了60%至85%,V4-Pro提升了57%至78%。
成本与性能的动态平衡策略
将峰谷定价与DSpark加速框架置于同一维度审视,可以发现DeepSeek正在构建一种“政策+技术”的组合拳,以应对日益严峻的算力成本挑战。对于开发者生态而言,这既是压力也是机遇。
从压力角度看,企业用户必须建立更精细化的API调用管理系统。简单的“用完即走”模式已不再适用,开发者需要在应用架构中嵌入智能调度层,根据任务的优先级和时效性要求,自动将请求路由至不同价格时段或不同加速等级的服务节点。例如,对实时性要求极高的用户交互可优先使用V4-Pro搭配高置信度验证,而对后台批处理任务,则可利用V4-Flash在低峰时段运行,并启用DSpark的裁剪机制以进一步降低成本。
从机遇角度看,DSpark的开源降低了推理优化的技术门槛。过去,推测性解码需要深厚的模型修改经验和巨大的算力投入,而DSpark提供的全栈工具链使得中小企业也能在现有V4模型基础上实现显著的速度提升。这意味着,即使面对高峰时段的高昂API费用,企业仍可通过技术手段提升单位算力内的输出效率,从而在一定程度上抵消成本上涨的影响。
此外,这种技术开源策略也有助于巩固DeepSeek在开源社区的生态地位。在Llama等模型占据主导地位的语境下,通过提供极具性价比的加速方案,DeepSeek能够吸引更多开发者基于其生态进行二次开发,形成“高性能+低成本”的用户心智。这不仅是技术实力的展示,更是构建长期竞争壁垒的关键一步。
行业启示与未来展望
DeepSeek的这一系列动作,为整个AI行业提供了一个关于商业化与技术演进相互作用的范本。首先,它证明了单纯追求模型参数规模的时代正在过去,工程化优化和调度策略已成为提升竞争力的核心要素。其次,动态定价机制的引入,标志着AI服务正从“资源粗放型”向“精细化运营型”转变。
对于企业而言,应对这一变化的关键在于建立敏捷的算力管理体系。这包括对API调用数据的深度分析,识别出可迁移至低峰时段的任务类型;同时,积极采纳如DSpark等经过验证的开源加速方案,将技术红利转化为成本优势。对于模型厂商而言,如何在保证服务质量的前提下,通过多元化的定价和服务等级协议(SLA)满足不同层次用户的需求,将是未来商业化的关键。
随着7月中旬V4正式版的到来,市场将观察这一定价机制在实际运行中的用户反馈及技术优化效果。无论结果如何,DeepSeek的这一尝试都将成为AI基础设施商业化进程中的一个重要参考坐标。在算力成为新石油的时代,如何高效开采、精准分配并持续降低开采成本,将是所有入局者必须面对的长期命题。而通过机制创新与技术迭代的双轮驱动,或许正是破局之道。