DeepSeek V4峰谷定价落地:推理加速如何重构企业AI成本结构
随着人工智能技术从探索期走向深度应用期,模型的性能迭代与商业化运营策略之间的平衡,已成为行业发展的核心议题。DeepSeek近期宣布V4正式版定于7月中旬上线,并同步实施峰谷API定价机制,这一举措不仅标志着其技术能力的进一步成熟,更折射出大型语言模型在商业化进程中面临的资源约束与价值重构。与此同时,联合北京大学发布的DSpark推理加速框架的全量部署,展示了通过工程优化突破性能瓶颈的可能。这两项举措一正一反,一方面通过价格杠杆引导流量分布,另一方面通过技术革新提升单位算力的产出效率,共同构成了当前大模型服务优化的双重驱动力。
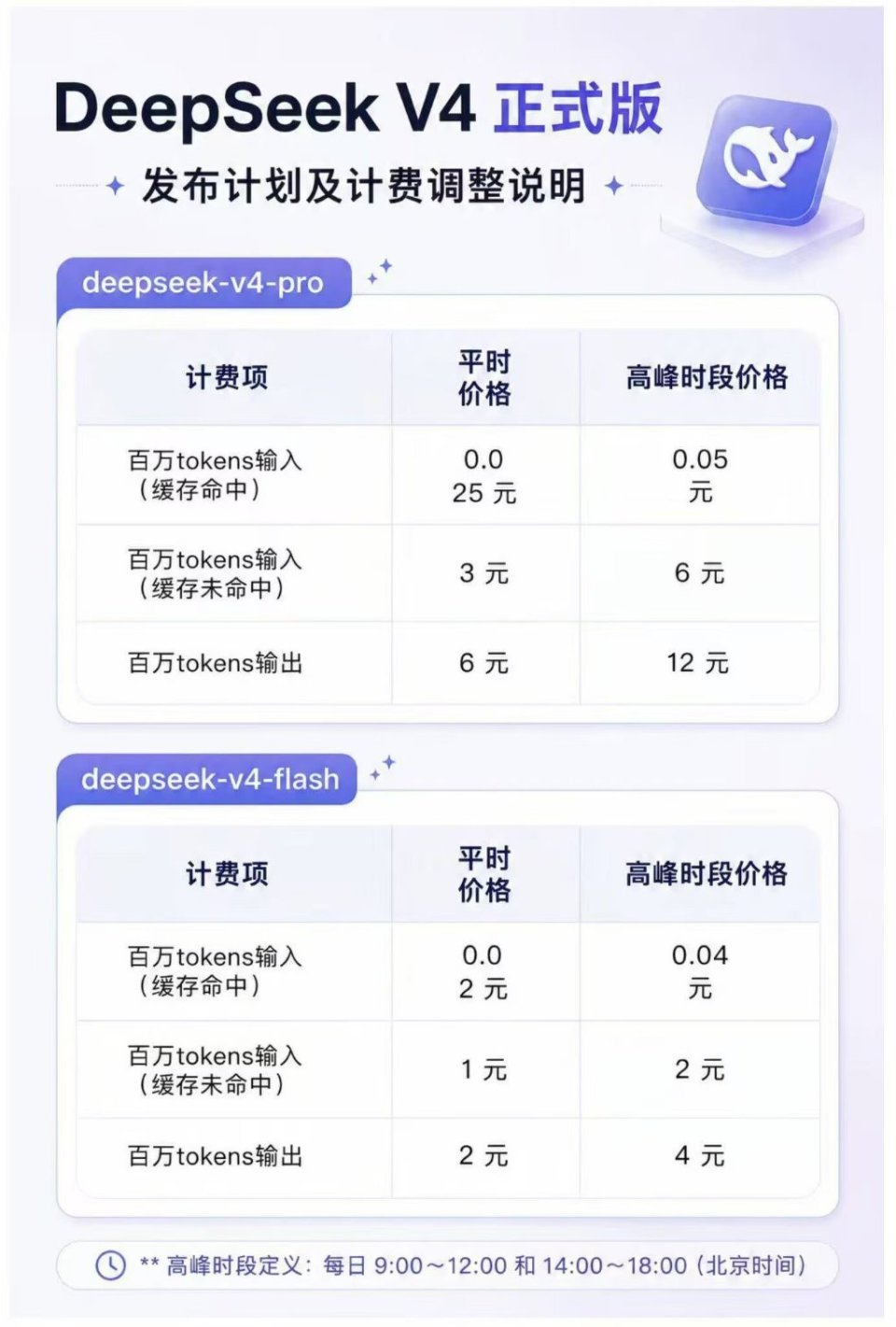
峰谷定价:资源约束下的商业化必然

DeepSeek V4正式版的推出,伴随着一套精细化的定价策略。根据官方公布的信息,API服务将实行“峰谷定价”机制,即在每日上午9时至12时及下午2时至6时的高峰时段,API调用价格为平时价格的两倍,而平时价格则维持现行水平不变。这一策略并非孤立的价格调整,而是基于算力资源稀缺性与服务稳定性考量的系统性解决方案。
从基础设施的角度来看,大模型推理对算力的消耗是巨大且非线性的。在业务高峰期,并发请求量的激增往往导致GPU集群处于满载甚至过载状态。若采用统一静态定价,无法有效调节用户行为,可能导致服务响应延迟甚至系统崩溃。通过引入价格弹性,DeepSeek旨在利用经济杠杆引导用户将非紧急的批量任务迁移至低峰时段,从而平滑算力需求的波动曲线。对于企业用户而言,这意味着API成本结构发生了根本性变化,单纯的“按需调用”模式不再适用,必须转向更精细化的“调度管理”模式。
这种定价机制对不同类型用户的影响呈现分化态势。对于实时性要求极高、无法调整调用时间窗口的主流业务场景,成本压力将显著增加;而对于数据分析、后台训练、异步内容生成等对延迟不敏感的场景,用户则可通过调整执行时间大幅降低运营成本。这要求企业重新审视其AI应用的架构设计,将“时间维度”纳入算力采购与调度的核心考量因素。
DSpark框架:工程优化突破性能瓶颈
在面临成本压力的同时,DeepSeek并未止步于运营策略的调整,而是通过在技术层面的深度创新来提升整体效能。6月27日,DeepSeek联合北京大学发布的DSpark推理加速框架,便是这一技术突破的集中体现。该框架并非对模型架构的根本性重构,而是在现有V4模型基础上,针对推理过程中的工程痛点进行了精准优化,特别是引入了全栈推测性解码(Speculative Decoding)工具链DeepSpec。
推测性解码的核心逻辑在于“用小模型推测,用大模型验证”。传统自回归生成模型每次只能生成一个Token,速度受限于大模型的前向传播时间。而推测性解码允许轻量级小模型快速生成多个候选Token(草稿),随后由大模型并行验证这些草稿的正确性。若验证通过,则一次性输出多个Token,从而显著提升生成速度。实测数据显示,部署DSpark后,V4-Flash单用户生成速度提升60%至85%,V4-Pro提升57%至78%。这一性能跃升,为企业在高并发场景下部分抵消峰谷定价带来的成本压力提供了技术底气。
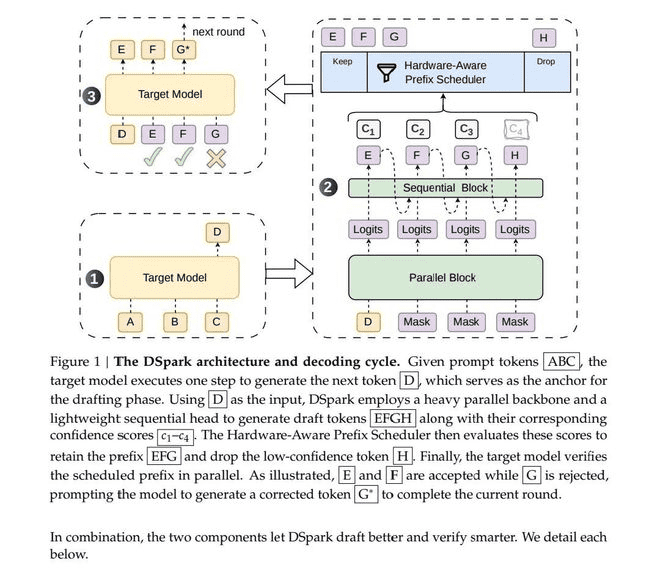
然而,推测性解码在实际落地中面临两大技术瓶颈:一是“后缀衰减”问题,二是全量验证导致的算力浪费。DSpark框架针对这两点提出了创新性的解决方案。
半自回归架构与置信度调度的技术突破
针对并行生成中出现的“后缀衰减”问题,即随着生成序列变长,错误累积导致验证接受率急剧下降,DSpark采用了“半自回归生成架构”。该架构设计了“并行主干+轻量串行头”的两阶段机制。并行主干保留了高速生成的优势,而串行模块则补充了相邻Token间的依赖关系,修正语义冲突。测试表明,采用2层深度设计的DSpark,其有效接受长度甚至超过了5层深度的纯并行方案DFlash。这一架构创新,在保持生成速度的同时,显著提升了预测的准确性,延长了有效生成的序列长度。
另一方面,针对全量验证造成的算力浪费,DSpark引入了“置信度调度验证机制”。通过增加置信度评分模块,框架能够实时预测每个候选Token的条件接受概率,并利用“顺序温度缩放”校准方法,将评分误差从3%-8%压缩至约1%。在此基础上,调度器能够根据实时负载动态调整验证长度:在低并发时充分利用算力,在高并发时主动裁剪低价值Token,避免资源争抢。这种动态自适应机制,使得系统在复杂多变的实际业务环境中,仍能保持高效的资源利用率和服务稳定性。
企业用户的策略重构与未来展望
DeepSeek V4的上线与DSpark框架的部署,不仅是技术产品的更新,更是对企业AI应用策略的一次重塑。对于决策者而言,理解并适应这一变化,需要从以下几个维度进行策略调整。
首先,建立分层级的API调用架构。企业应根据业务场景对延迟和成本的敏感度,将API调用分为实时交互类、异步处理类和批量计算类。对于实时交互场景,可考虑支付溢价以获取更稳定的服务体验;而对于异步和批量场景,则应充分利用峰谷定价机制,通过任务排队与调度算法,将工作负载迁移至低峰时段,实现成本最小化。
其次,深化推理优化技术的落地应用。DSpark等推理加速框架的开源与部署,降低了高性能推理的技术门槛。企业开发者应积极探索将推测性解码等技术与现有业务系统融合,通过提升单位时间内的Token生成量,间接降低单次调用的时间成本。这不仅能够缓解高峰时段的拥堵问题,还能提升整体系统的吞吐量。
最后,注重数据与调度的精细化运营。峰谷定价机制要求企业对自身的API使用模式有清晰的认知。通过监控历史调用数据,绘制出精确的流量潮汐图,企业可以更科学地制定调度策略。同时,结合DSpark的动态调度能力,实现算力资源的弹性伸缩,避免资源闲置或过载,从而在成本控制与服务品质之间找到最佳平衡点。
综上所述,DeepSeek V4正式版及其配套的定价策略与技术优化措施,共同构建了一个更加复杂但也更加灵活的大模型服务生态。对于行业参与者而言,这既是挑战,也是机遇。唯有紧跟技术演进步伐,优化自身架构与策略,方能在日益激烈的AI竞争中占据主动,实现技术与商业价值的双重突破。未来的大模型服务,将不再仅仅是算力的比拼,更是调度智慧与工程效能的综合较量。