80%代码由AI合并:Anthropic揭秘Agent闭环开发的四大核心范式
模型角色的范式转移:从问答到闭环执行
在人工智能工程化的演进路径上,Anthropic近期披露的内部实践数据引发了行业的广泛关注。其研究产品经理Theo Chu在一场分享中指出,Claude模型已经深度嵌入Anthropic自身的工程工作流,超过80%的代码由Claude合并。这一数据不仅标志着大语言模型(LLM)在代码生成领域的成熟,更揭示了一个更为本质的转变:模型的角色正在从被动的“问答助手”向主动的“任务执行者”演进。
这种演进的核心在于**“Close the Loop”(闭合循环)**理念的落地。传统的AI应用往往止步于模型生成文本或代码,而闭环Agent则要求模型能够在一个包含反馈、验证和修正的完整环境中持续工作。这意味着模型不仅要输出结果,还要有能力验证自身输出的正确性,并在发现错误时自动调整策略。正如Theo所言,开发者需要适应这个新世界,构建能够面向未来而非仅仅满足过去需求的产品。

能力跃迁:SWE-bench数据背后的失败率下降
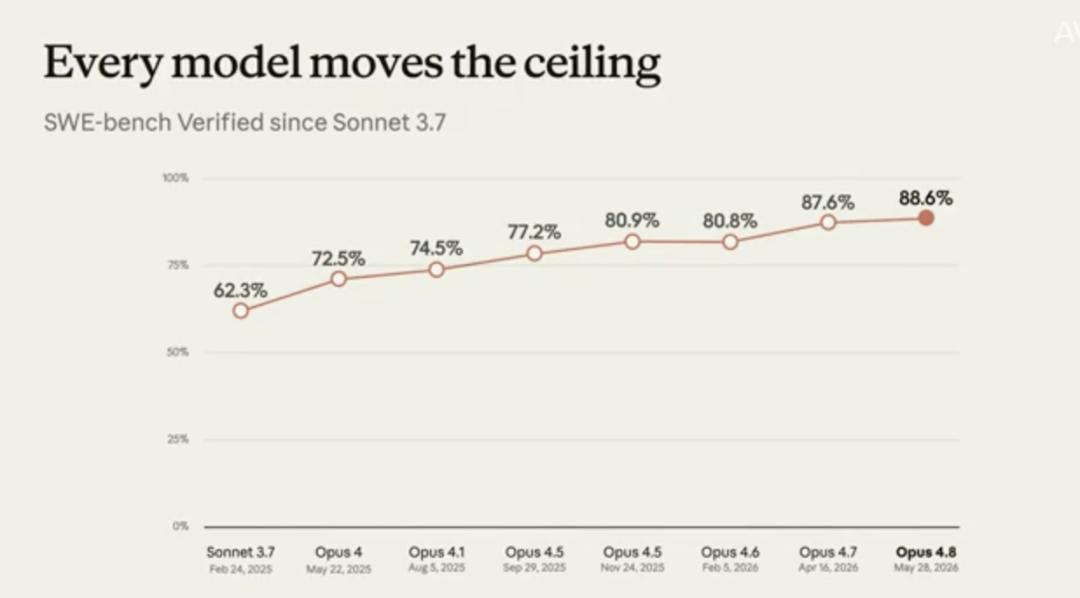
理解模型能力的真实提升,不能仅看“做对”的数量,更要看“做错”的频率。Theo Chu以Anthropic内部重要的编程评估基准SWE-bench Verified为例,展示了模型能力的质变。
SWE-bench由一系列真实的GitHub Issue组成,要求模型理解问题、修改代码并通过测试验证。数据显示,一年前的Sonnet 3.7在该基准上的得分仅为60%左右,而最新的Opus 4.8得分已达到88%。这看似28%的提升背后,隐藏着更深层的逻辑:模型在复杂任务上的失败率大约降低了三分之二。
失败率的显著下降意味着模型开始具备处理更长、更复杂、更接近真实生产环境任务的能力。在最新的Mythos和Fable系列模型中,该基准测试甚至出现了接近饱和的迹象。这表明,部分过去极具挑战性的任务,如今对模型而言已不再是瓶颈。对于开发者而言,这是一个重要的警示信号:如果仍使用12个月前的任务集来测试今天的模型,将会严重低估其真正的能力边界。
核心范式一:先规划,再行动
在新模型的能力图谱中,**自适应思考(Adaptive Thinking)**是最显著的突破之一。旧模型在面对复杂任务时,往往倾向于直接开始编写代码或调用工具,缺乏充分的规划。这种做法类似于安装家具时不看说明书,直接动手拼装,导致最终结果虽看似合理,但功能无法闭环,甚至出现严重偏差。
相比之下,Opus 4.8等新模型展现出强大的规划能力。它们会在内部深入思考任务规范,在预规划阶段捕捉潜在错误。开发者甚至能在逻辑推理链中看到诸如“实际上……”或“算了,还是……”的自我修正词汇。这种先思考后执行的模式,大幅减少了无效的工具调用和代码行数,提高了首次执行的成功率。
对开发者而言,这意味着产品体验设计需要为模型的“思考”留出空间。通过引入自适应思考机制,产品应根据任务复杂度动态调整模型的推理深度。简单问题快速响应,复杂任务则给予模型充分的规划时间,从而实现效率与准确性的平衡。

核心范式二:错误恢复与自我纠正
构建Agent的常见误区是过度关注工具调用的数量,而忽视了模型识别和修正错误的能力。旧模型常陷入“恶性循环”(Doom Looping):当任务失败并收到反馈时,它们往往只是机械地重试相同的方法,而无法真正理解失败原因或改变策略。
新模型的进步在于其具备了**错误恢复(Error Recovery)**能力。模型能够读取环境反馈,分析失败根源,并尝试不同的解决路径。这种能力对Agent产品至关重要,因为长任务中必然伴随错误。真正有价值的Agent并非永不犯错,而是具备从错误中恢复并迭代优化的能力。
为此,开发者需要重新设计Agent所处的环境,使其能够提供明确的验证信号。例如,在应用生成Agent中,赋予模型访问前端界面的权限,使其能够自主点击、测试并判断页面状态。这种“执行→验证→修正→再执行”的循环,正是Close the Loop的核心所在。通过环境反馈,模型可以避免无效的Token消耗,以更高效的方式完成任务。

核心范式三:长上下文与连贯性
长任务执行中的另一个痛点是“迷失主线”(Losing the Plots),即模型在执行过程中遗忘初始指令或上下文。新模型在上下文连贯性上实现了显著突破,能够稳定维持100万个Token甚至更长的上下文窗口。
这一能力提升使得开发者无需再将任务碎片化处理。相反,应将更完整的任务交给模型,如整个代码库、完整的产品需求文档等。当规划能力、错误恢复能力和长上下文能力叠加时,Agent的形态将发生根本性变化:它不仅能规划,还能在长周期内保持目标一致,通过自主行动和验证完成复杂流程。

开发者构建策略:为未来设计
面对模型能力的快速迭代,开发者需全面升级研发战术,以更好地利用新一代模型的特性。
1. 动态刷新评估基准(Evals)
不要依赖过时的评估标准。Theo指出,许多客户在新模型发布后感觉提升有限,往往是因为原有的Evals只测试了模型已熟练掌握的内容。开发者应面向未来设计Evals,将用户最新报告的失败模式及未来预期功能纳入测试用例。如果某些遗留问题已解决,应立即更新更难的题目,以真实反映模型能力。
2. 精简“脚手架”(Shrink the Scaffolding)
在旧模型时代,开发者需通过大量系统提示词、外部工具和约束补丁来弥补模型的不稳定性。然而,随着新模型指令遵循能力的增强,这些“脚手架”反而可能成为负担,甚至引发意外的错误。例如,Anthropic曾因新模型过于听话地执行过时指令而导致Bug。
开发者应精简提示词,针对意图编写简洁指令,给予模型更多自主权。通过减少对模型的过度约束,才能清晰识别其真正的能力边界,避免人为制造性能瓶颈。
3. 闭环设计与自主验证
构建自改进Agent的核心在于闭环设计。除了自适应思考和精简脚手架,还需赋予模型受控的行动权限。Anthropic在Claude Code中推出的“自动模式”分类器,即在开发者控制与模型自主权之间取得了平衡,自动甄别安全行动,防止误操作。
同时,应配备如“Computer Use”这样的自我质检工具,让Agent能够自主进行界面点击、代码测试等验证工作。通过环境的真实反馈,Agent实现代码的自我迭代与修正,从而真正发挥智能体的潜力。
结语与展望
Anthropic的内部实践表明,AI工程化已进入以“闭环”为核心特征的新阶段。模型不再仅仅是信息的提供者,而是任务的执行者和验证者。开发者需摒弃旧有的测试思维,拥抱自适应规划、错误恢复和长上下文等新能力,通过精简脚手架、动态评估和闭环设计,构建出真正具备自主改进能力的智能体。这不仅是技术的升级,更是产品开发哲学的根本转变。