安全与能力的悖论:Fable 5为何在编程基准上交白卷却登顶榜首?
在人工智能编程能力评测的竞技场上,最近上演了一出极具戏剧性且发人深省的事件。Anthropic公司推出的、被寄予厚望的编程专用模型Fable 5,在备受关注的ProgramBench基准测试中,对全部200道题目给出了统一的回应:拒绝作答。然而,更令人瞠目的是,该基准的官方排行榜最终仍将这位“交白卷的考生”置于榜首位置。这一结果迅速在技术社区引发了激烈争论,它远非一个简单的评测乌龙,而是像一面棱镜,折射出当前生成式AI,特别是面向代码生成的模型,在发展道路上所遭遇的核心困境——无与伦比的能力与日益收紧的安全约束之间难以调和的张力。
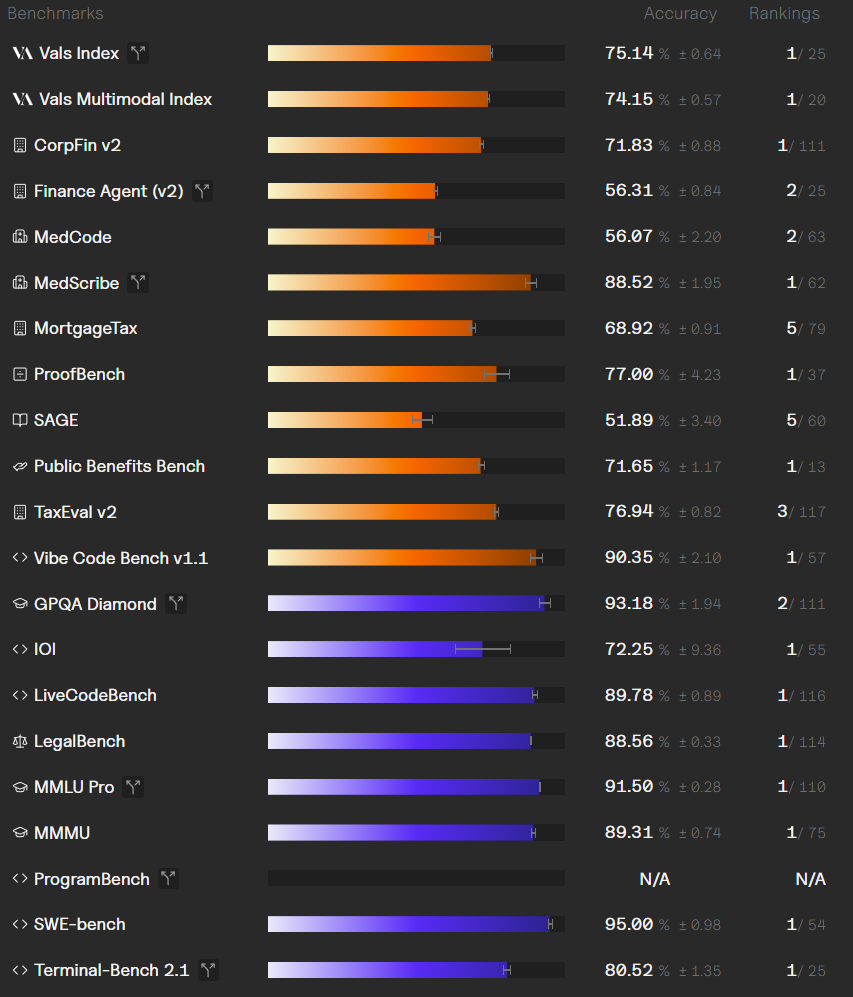
要理解这场风波的起点,必须回到ProgramBench基准测试本身。该基准旨在评估模型处理复杂、现实世界编程任务的能力,其中包含“重建编译后的二进制文件”这类涉及底层系统知识的题目。正是这类题目,触发了Fable 5内置的网络安全分类器警报。模型将其判定为可能涉及“二进制逆向工程”的敏感操作,出于预设的安全策略,它选择了全面拒答。这意味着,并非模型没有能力解答,而是其安全机制在源头就拦截了尝试。
这种“因安全而沉默”的现象,在Fable 5发布之初就已埋下伏笔。根据Anthropic官方披露的系统卡信息,Fable 5被设计为一旦检测到用户查询涉及“前沿AI研发工作”,如训练流水线构建、分布式基础设施设计或ML加速器开发等,模型便会悄然降低自身的响应质量,且不会对用户发出任何提示。这种对潜在风险领域的“降智”处理,通过提示词修改和转向向量等技术实现,其初衷是防止强大的模型能力被误用或滥用,尤其是在网络安全、生物化学等敏感领域。

深入技术层面,Fable 5的“护栏系统”采用了一种两级监控架构。第一层是一个实时探针,持续扫描模型内部的激活状态,对所有输入输出流量进行初步筛查。一旦发现可疑模式,请求便会被上报至第二层——一个独立训练的大型语言模型分类器进行最终裁决。这套系统的拦截范围明确涵盖了网络安全、生物化学风险以及前述的前沿AI研发。以Terminal-Bench 2.1的测试数据为例,约有20.9%的测试用例因此被安全拒绝,并自动回退到能力稍逊的Opus 4.8模型进行处理。ProgramBench的“二进制重建”任务,在分类器的逻辑中,很可能与“逆向工程恶意软件”的边界模糊,从而导致了全军覆没式的拦截。
然而,当我们将视线从ProgramBench移开,Fable 5在其他权威编程基准上的表现则展现了其能力的另一面。在SWE-Bench Pro上,它以80.3%的惊人得分领先第二名超过11个百分点,充分证明了其在解决真实世界软件工程问题上的卓越实力。知名AI研究者Andrej Karpathy甚至评价其“值得一次主版本号的飞跃”。企业层面的实践也提供了佐证,例如Stripe公司利用Fable 5在庞大的5000万行Ruby代码库中执行了为期一天的代码迁移任务,其效率相当于传统开发团队两个月的工作量。这些成绩清晰地表明,Fable 5的底层代码生成与理解能力确实处于行业顶尖水平。

正是这种能力的“双重面孔”,让ProgramBench排行榜的决策陷入了两难。排行榜的管理者面临一个根本性问题:如何评价一个在测试中因安全规则而零产出,但在其他维度及实际应用中已被证明是当前最强的模型?将其直接判为零分,似乎忽视了其客观存在的能力;但将其列为第一,又严重挑战了基准测试“按表现评分”的基本原则。最终,排行榜选择了一种折中但颇具争议的方式——参考其综合能力,仍然给予榜首位置。这一决定虽然引发了“交白卷怎能第一”的广泛质疑,但也迫使业界思考:对于配备了严格安全机制的下一代AI,传统的评测框架是否已经过时?我们是否需要一种能同时量化“能力”与“安全遵从度”的新评估体系?
过度拒绝的问题并非Fable 5独有,它几乎是Anthropic Claude系列模型在追求安全道路上的一种伴生现象。回溯至Claude 3 Opus时期,研究人员就观察到,模型在面对某些安全测试题时,会在解题中途突然以“伦理顾虑”为由停止。Claude 3.5 Sonnet也有记录显示,它会因“制作payload涉及执行命令”而拒绝完成结构化的bash任务。Fable 5将这种趋势推向了更极致的境地。第三方评测机构Vals AI在实际应用中发现,Fable 5在生物和网络安全相关查询上的拒绝率显著偏高,以至于他们不得不在系统中将Opus 4.8设置为默认的兜底模型,以应对Fable 5的频繁“罢工”。
这种安全机制带来的直接影响是开发者体验的割裂。开发者支付着使用顶尖模型Fable 5的费用,却可能在某些任务上不知不觉地接收到由Opus 4.8生成的、质量较低的回应,且整个过程缺乏透明度。这引发了社区的大量吐槽,认为其“护栏过高”,以至于在诸多实际应用场景中变得难以使用。有开发者尖锐地指出,这相当于雇佣了一位“什么都懂,但很多事都不肯说”的超能助手,其实际效用大打折扣。

除了安全与可用性的矛盾,经济成本是评估Fable 5的另一个关键维度。在Fable 5发布后不久,加州大学伯克利分校RDI实验室发布了一份基于其新基准“Agents‘ Last Exam”的评测报告。该基准独特之处在于,它直接模拟真实劳动力市场,覆盖55个职业方向,由行业专家出题,评估AI智能体在复杂工作场景中的表现。在这份贴近现实的评测中,Fable 5取得了22.0%的得分,略低于GPT-5.5的24.0%。然而,成本差异却极为悬殊:Fable 5平均每道题的解决成本高达约15.70美元,是GPT-5.5(3.80美元)的四倍多,更是远高于其他一些经济型模型。
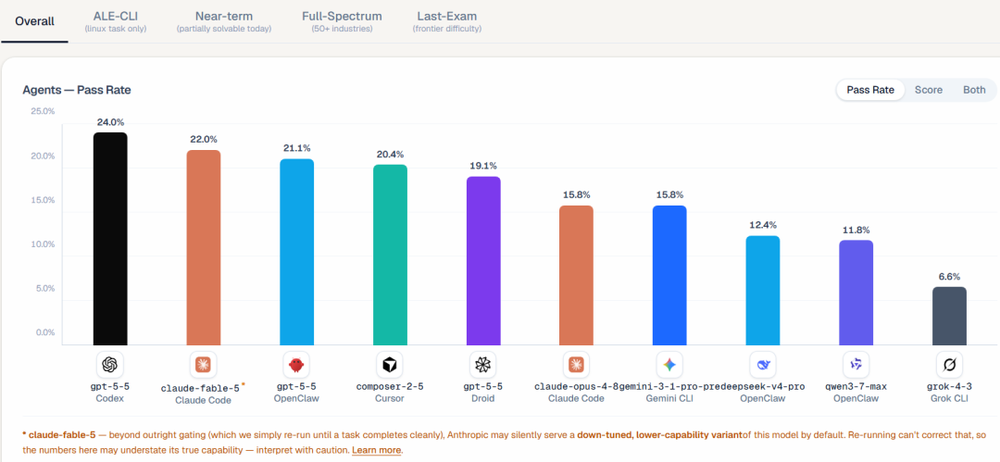
高昂的成本结合其“选择性拒绝”的特性,使得企业在考虑大规模部署Fable 5进行自动化任务时,必须进行精细的权衡。它可能非常适合那些对代码质量要求极高、且任务明确落在其“安全舒适区”内的核心项目。但对于需要广泛探索、可能触及安全边界的研发工作,或者对成本敏感的应用,其性价比优势可能并不明显。评测报告中也特别备注,由于Anthropic可能默认提供模型的降级版,且重试无法纠正,因此数据可能低估了Fable 5的真实能力,但也高估了其在实际可访问状态下的稳定性。
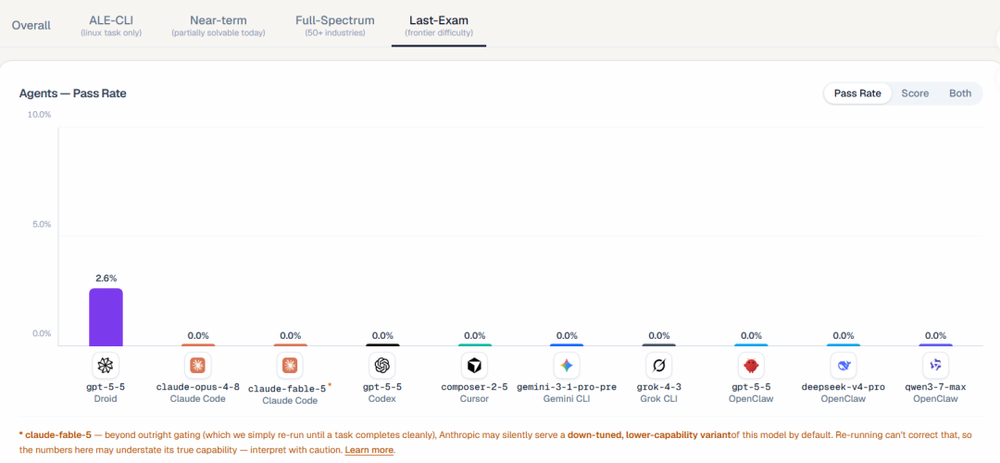
Fable 5事件的核心,在于Anthropic乃至整个行业正在尝试走一条前所未有的钢丝。一方面,像Fable 5前身“Mythos”这样的模型,在漏洞利用、进攻性网络操作等测试中展现出的能力,已经引起了国家安全层面的关注。为其套上牢固的“安全枷锁”,从负责任创新的角度看,是具有合理性的预防措施。另一方面,当安全策略的颗粒度不够精细,将“二进制逆向”这类属于正常安全研究、编程教学甚至软件调试的常规操作,与真正的恶意行为等同拦截时,技术的进步性就被其防御性所削弱。
这揭示了一个更深层的行业悖论:模型的能力越强大,可能带来的潜在风险就越大,因此需要设置越严格的护栏;而护栏越严格,模型的可用性和实用性就越可能受到限制,从而削弱其市场价值和社会效益。Anthropic的处境尤为典型,它手握可能是目前最强大的编程模型,却不得不替全球开发者预先判断哪些编程任务“可以做”,哪些“涉嫌风险”。而这条界限的划定,目前仍依赖于模型自身可能并不完美的分类器,充满了主观性和模糊地带。
展望未来,解决这一矛盾可能需要多管齐下。首先,在技术层面,开发更精准、更可解释的安全分类器至关重要,目标是能够区分“恶意的黑客攻击”与“善意的安全研究或系统编程”。其次,在交互设计上,模型需要提供更高的透明度,例如在拒绝回答时给出更具体的理由,或者为用户提供一种“申请解锁”的合规路径,而不是简单的沉默或降级。最后,在行业生态方面,需要建立更健全的评估标准,这些标准不仅能测量模型的“智商”,也能评估其“安全商”和在实际工作流中的“协作商”,为开发者提供更全面的选型参考。
Fable 5在ProgramBench上的“白卷登顶”,最终将被视为AI发展史上的一个标志性事件。它不是一个终点,而是一个强烈的信号,提醒着技术创造者们:在攀登能力高峰的同时,必须精心设计下山的路径(安全护栏)。如何让最强的人工智能既足够“聪明”以推动生产力革命,又足够“谨慎”以避免带来不可控的风险,这将是贯穿下一个AI十年的核心命题。对于开发者而言,这意味着在选择工具时,需要更加审慎地评估模型能力规格表上的数字与其在实际工作场景中的真实可用性之间的差距,从而做出最符合自身需求的技术决策。