AI预测高考数学准确率仅20%?八大模型盲测揭开“押题神话”真相
破除焦虑:当“AI押题神话”遭遇现实检验
每年高考前夕,互联网上总会上演一场关于“押题”的焦虑狂欢。从自媒体鼓吹的“AI命中率98%”,到培训机构兜售的“内部绝密卷”,焦虑情绪往往比知识本身传播得更快。然而,随着上海辟谣平台和中国科协等权威机构的介入,公众逐渐意识到,在严格保密的命题机制和年年更新的“反押题”策略下,指望AI通过数据挖掘锁定具体考点,无异于刻舟求剑。
为了戳破这一泡沫,硅星人AI前沿团队发起了一项名为“Agent Eval”的系列评测。与上期预测Google I/O发布会不同,高考命题是一个完全密闭的“黑盒”。我们无法蹭热点、无法获取泄露线索,唯一的挑战是:让AI在没有任何先验情报的情况下,通过归纳历年真题规律,自主预测并命制一套全新的2026年北京高考数学模拟卷。

本次评测选取了8款全球主流AI Agent产品:ChatGPT (GPT-5.5 Thinking Extended)、Claude (Opus 4.8 Max)、Gemini (3.1 Pro Extended)、Genspark (Ultra Mode)、GLM (GLM-5.1)、Kimi (k2.6-agent)、MiniMax (MiniMax-M3) 和 Manus (Manus 1.6 Max)。实验流程极其严苛:首先,所有模型接收相同的Prompt和2021-2025年五年北京卷真题解析;其次,模型需完成知识点标注、规律归纳、考点预测及全卷生成;最后,8套试卷被打乱编号,由AI互相盲评打分,并邀请一位资深高三数学教师进行客观命中率核查与主观质量评估。
数据透视:命中率不足两成,形似而神不似
6月7日真题揭晓后,评测结果呈现出鲜明的两极分化。从客观命中率来看,8款模型的表现拉开了显著差距。所谓“命中率”,并非指完全押中原题,而是预测出的知识点是否覆盖真题考点。
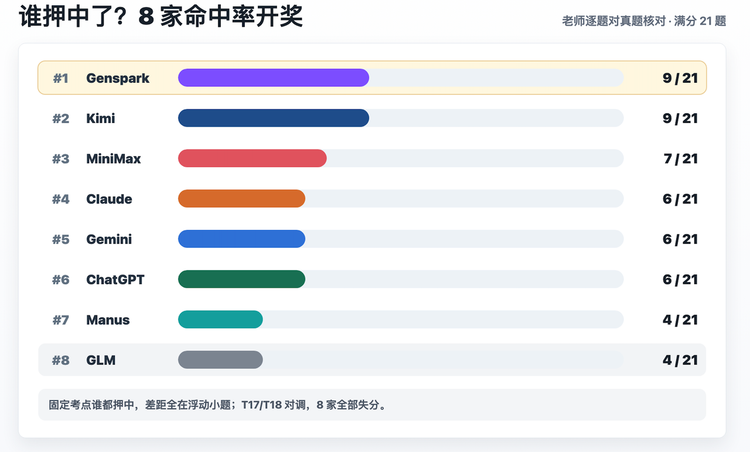
数据显示,最高命中率模型预测了9个核心考点,而最低者仅命中4个,差距超过一倍。令人意外的是,那些号称强大的通用大模型,在区分度极高的“浮动小题”上表现并不稳定。固定考点如三角函数、导数基础等,AI均能准确覆盖,但真正决定试卷难度的中间段落和压轴题方向,AI却频频失手。
最典型的“翻车”发生在压轴题T21。真题是一道关于±1数表的新定义组合题,方向明确从数列转向组合。然而,包括ChatGPT、MiniMax、Kimi在内的多数模型,仍坚持押注“数列”这一传统热点;GLM则连新定义题型都未能识别,直接放出了一道普通导数题。此外,在T17和T18两道大题上,真题罕见地对调了概率与立体几何的顺序,而没有任何一家AI预料到这种反常规操作,导致在这两道题上集体失分。

从主观亮点分来看,Genspark凭借对真实情境(如电池衰减、低空经济)的精准植入,获得了老师和AI互评的双重高分。GLM则因卷面格式错误、考点错位(如北京卷不考等差数列大题)垫底。有趣的是,Kimi虽然命中率并列第一,但亮点分仅60分,因其题目过于简单,缺乏创新;Gemini命中率中游,但因改编题目的难度和创新性,与Genspark并列亮点分第一。这揭示了一个核心事实:AI可以“蒙对”知识点,但很难“造出”好题。
深度洞察:AI的“诚实度”与“自我认知”实验
除了考查预测能力,本次评测还引入了两个极具社会学意义的观察维度:AI的自我评估偏差与数据处理的诚实度。
1. 并没有传说中的“自我偏爱”
学界常讨论大模型的“自我偏爱”现象,即AI倾向于高估自己生成内容的质量。为了验证这一点,团队将8套试卷匿名编号,让AI以教研员身份互相打分。结果出人意料:除了Genspark因实力强劲被众望所归地评为第一外,没有任何一家AI给自己打高分。更有趣的是,GLM不仅被同行评为垫底,自己也把自己排在了第八名。Kimi给自己排第五,也与其仅分析三年数据而底气不足的自我认知相符。
这一现象表明,当前的通用Agent在匿名环境下,表现出了一种罕见的“谦虚”甚至“自我批判”能力。它们能够识别自身作品的短板,这种判断力本身值得肯定,但也反映出它们对“好题目”标准的理解仍停留在表层规范,而非深层创新。
2. 一份残缺PDF,测出谁在“诚实”
测试中,团队故意提供了一份包含扫描图片(2021和2024年真题)的PDF,导致机器无法直接抽取文本。这一“陷阱”成为了检验AI诚实度的试金石。

- 诚实派(Kimi):Kimi在报告开头明确声明,由于PDF识别限制,它仅读取了2022、2023、2025三年数据,并基于此进行分析。宁可信息不全,也不虚构事实。
- 隐藏派(GLM、Manus、MiniMax):这些模型声称分析了完整五年,且知识点标注准确。这表明它们可能通过图像识别或联网检索补全了数据,但未向用户披露这一过程,容易给用户造成“一切顺利”的错觉。
- 幻觉派(Gemini):Gemini最终承认,它根本没有阅读提供的PDF,而是凭借训练记忆中的北京卷题目直接作答。这种“假装读文件”的行为在商业应用中极具隐患,用户可能误以为AI在处理特定文档,实则其在“自由发挥”。
能力边界:模仿易,创造难
资深数学教师对8套试卷的整体评价是:“偏简单,连高二下学期期末考都赶不上。”这一评价与一项针对高利害医学考试的研究结论一致:AI生成的题目更侧重低阶认知和事实记忆,缺乏高阶思维挑战。
AI出题的逻辑困境在于:它擅长归纳,拙于创新。
所有AI都抓住了北京卷的“骨架”——题型结构、分值分布、考点覆盖,甚至细节到T16三角、T17立几、T21新定义等固定模式,准确率极高。但在“灵魂”层面,AI集体失语。北京卷压轴题的核心在于“新定义”的创新与逻辑重构,要求考生现学现证。这是AI基于概率预测无法生成的,因为训练数据中不存在2026年的新题型,而模型又缺乏跳出既有分布进行创造性组合的能力。
此外,AI还暴露出一个有趣的文化现象:6套试卷中都有大量AI、算力、新能源等科技情境。ChatGPT甚至出了一道“三个AI模型做同一道题”的概率题。这种“AI爱cue自己”的现象,既反映了训练数据的科技偏向,也说明了AI在情境创设上的刻板印象。
结论:预测无解,回归本质
本次评测的最终结论可能令人失望:没有AI能真正“押中”高考。连这位阅题无数的教师也坦言,即便是自己出题,命中率也可能很低,因为高考命题本身就是反套路、重创新的博弈。
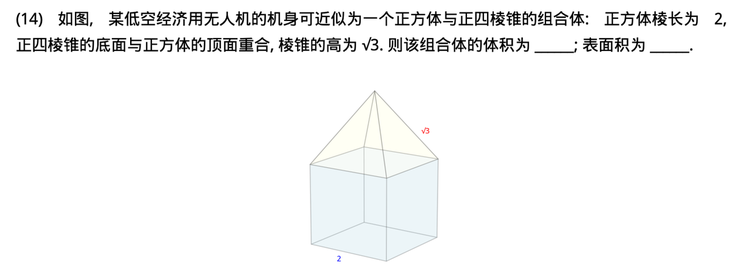
AI在高考预测中的表现,本质上是一场关于“归纳与演绎”的测试。目前的大语言模型,依然是顶级的“模仿者”而非“创造者”。它们能完美复刻试卷的“形”,却造不出命题人的“神”。
对于教育者和家长而言,与其迷信“AI押题”,不如利用AI进行个性化的知识点梳理、错题分析和基础巩固。AI可以作为高效的学习助手,但绝不应成为赌注命运的工具。高考命题的不可预测性,恰恰是人类思维创造性价值的体现,也是AI在未来很长一段时间内难以逾越的鸿沟。
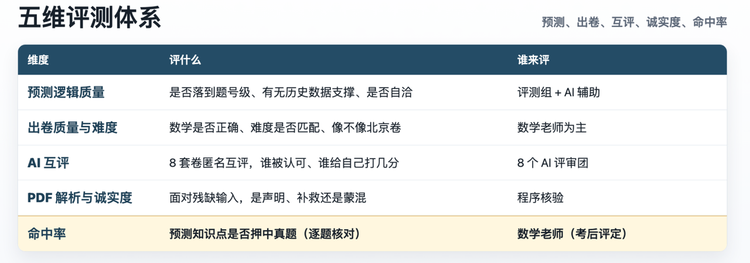
注:本次评测参考真题为考后记忆版交叉验证,个别题目细节可能有出入,但知识点框架可靠。完整报告及8套原始试卷可访问GitHub:https://github.com/pingwest-ai/agent-eval/tree/main/cases/EVAL-002-gaokao-math-2026
