CVPR 2026突破虚拟与物理边界:AI视觉系统如何真正「动手」了?
视觉系统的角色革命:从感知到行动
当传统计算机视觉还在讨论mAP和IoU时,CVPR 2026已经将技术演进的核心命题从“看清楚”转向了“看得懂+做得对”。这种转变最直观的体现,是会议议程中“具身智能”相关主题的爆发式增长——据不完全统计,本届CVPR近40%的Workshop和专题研讨会涉及物理环境交互、动作生成或实时决策。
一位现场参会的伯克利博士后向我们描述了这种变化:“以前提交论文, reviewers会问‘你的检测框精度够不够?’现在他们第一句往往是‘你们模型如何在模拟与现实之间弥合domain gap?’——这是本质范式的迁移。”
这种迁移在技术实现上体现为三重突破:
- 多模态融合的时空压缩:特斯拉FSD上下文长度从10秒跃升至30秒,意味着视觉系统不仅能处理当前帧,还能构建前3秒的动作链+后3秒的轨迹预测,形成12帧窗口的时空记忆闭环。
- 物理约束的内生建模:哈佛Yilun Du团队提出的“物理幻觉检测模块”,可在世界模型生成轨迹时自动标出违反重力/动量守恒的段落,显著降低Sim-to-Real迁移失败率。
- 动作空间的开放扩展性:小鹏刘先明强调“VLA与世界模型非二选一”,其第二代系统采用模块化解耦设计——基础动作库(低层)保持离散动作空间,而高层世界模型输出连续参数供 planner重采样。
中国力量:从量变到质变的三个维度
论文产出:数量优势转化为质量垄断
高校论文接收Top10中8所中国机构的分布呈现新特征:
| 院校 | 论文数 | 核心方向 |
|---|---|---|
| 上海交大 | 46 | 视觉-语言-动作三元组建模 |
| 浙大 | 40 | 3D物理渲染与生成 |
| 中科大 | 38 | 长时程机器人记忆架构 |
| 中山大学 | 36 | 野外场景泛化能力评测 |
| 西湖大学 | 22 | 极小团队高效协作范式 |
尤其值得关注的是西湖大学的“闪电战”模式:4位学者通过复用底层代码库(如OpenBot框架)、交叉投稿机制(同一系统投稿CVPR+ICRA),实现人均5.5篇产出,为高效科研组织提供了新范本。
产业部署:产业链条完整度跃升
中国企业的赞助层级清晰呈现产业布局:
- 基础设施层:阿里云(算力)、潞晨科技(Colossal-AI)构建算力底座;
- 模型底座层:字节(多模态基座)、MiniMax(轻量化VLM)提供模型选项;
- 数据层:Nexdata(VLM专用数据集)、Sudo(物理遥操作数据)解决数据瓶颈;
- 硬件层:宇树科技(足式机器人)、Linkerbot(灵巧手)、自变量(高精度执行器)完成执行闭环。
这种“软硬一体全栈覆盖”的态势,使中国在具身智能领域摆脱了以往“大模型依赖国外框架+机器人依赖进口底盘”的割裂状态。
赛事成果:真机赛道实现全包揽
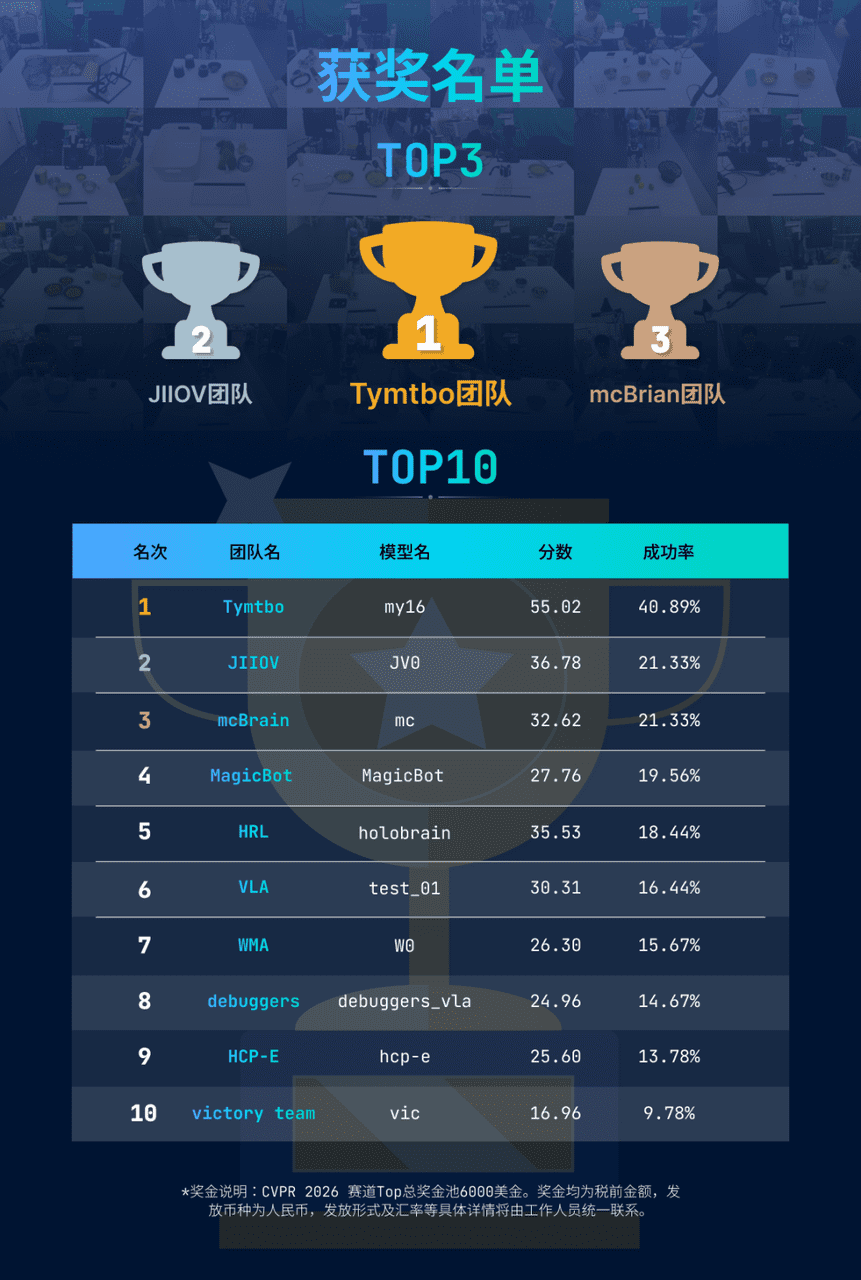
GigaBrain Challenge 2026的四个赛道结果极具代表性:
- RoboTwin仿真赛道:电子科技大学采用强化学习+物理约束损失函数,仿真成功率提升27%;
- GigaWorld评估器赛道:清华大学提出基于因果图的世界模型一致性评分标准;
- PhysClaw演示赛道:清华深研院实现柔性线缆穿孔(直径误差<0.5mm);
- RoboChallenge真机赛道:小米my16系统以40.89%成功率夺冠——这是该赛事设立以来首次有模型突破40%门槛。
关键技术突破:四项不可逆趋势
1. 3D理解成为视觉系统的“新基座”
UPenn的Jiatao Gu团队在Workshop上抛出的质问——“具身智能需要关心3D吗?”,在本届会议已演变为“必须关心+必须实时重建”。关键证据在于:
- 米家机器人团队将NeRF加速版嵌入视觉通路,在双臂抓取任务中将3D位姿估计延迟降至83ms;
- 上海AI Lab的EmbodiedAIinLife Workshop专门设置“3D幻觉诊断”环节,要求所有系统报告深度估计的不确定性分布。
2. 物理常识的可学习化
传统物理模型依赖手工设计约束方程,而CVPR 2026的突破方向是让系统从数据中自动发现物理规律:
- 牛津VGG组提出的D4RT框架,通过对比学习识别“违反常识”的物理交互序列;
- Meta提出的GNoME物理编码器,能在不预设重力/摩擦参数的情况下,从10万条机器人操作视频中复现牛顿第二定律。
3. 长时程记忆的工程化落地
小米my16系统的“S1/S2双系统”设计揭示重要趋势:
- S1系统(执行引擎):轻量化VLA模型,响应延迟<50ms;
- S2系统(认知推理):大型世界模型,每3秒触发一次推理;
- 记忆模块:通过稀疏索引+语义压缩,支持72小时连续运行的记忆回溯。
这种分层架构在RoboChallenge 30项任务中实现跨任务策略复用率38%,远超单体模型的12%。
4. 真实场景评测标准体系化
针对过去仿真评测与真实表现脱节的问题,本届会议推动三大改进:
- 干扰项引入:RoboChallenge任务中随机增加光源变化(±30%亮度)、物体表面反光等现实噪声;
- 跨平台一致性:要求同一模型在Boston Dynamics Spot与优必选Walker X上表现差异<15%;
- 人机协作压力测试:设置“人类突然干预”场景,评估系统从异常中恢复的能力。
未来战场:尚未解决的五大挑战
尽管技术进展迅速,但现场讨论暴露出五个关键瓶颈:
长期依赖的稀疏奖励问题:在需5分钟以上的长任务中,90%的系统在第3分钟后决策质量断崖下跌;
物理因果的反事实推理缺失:当系统被问“如果地板突然消失会怎样?”时,仅17%能给出符合物理定律的预测;
跨模态对齐的语义鸿沟:视觉特征与语言描述的嵌入空间在动作规划阶段出现>45%的错位;
能源效率的现实制约:最先进系统在连续运行8小时后需散热30分钟,远未达工业部署标准;
安全验证的闭环缺失:当前95%的评估仅测试成功场景,缺乏失败案例的系统性归因。
结语:结界打破后的重构
CVPR 2026最深刻的信号不是技术参数的提升,而是研究范式的根本重构:当视觉系统开始执掌物理世界的控制权,其评估标准、训练方法、验证体系都必须重塑。中国团队在论文、产业、赛事三个维度的全面发力,标志着从“技术跟随”进入“生态共建”阶段——但真正的里程碑,或许要等到某套系统能在无人干预下连续工作24小时,且性能波动<5%时才会到来。届时,我们或将见证:计算机视觉真正走出屏幕,成为物理世界的“数字神经末梢”。