CVPR 2026深度解析:计算机视觉如何跨越屏幕,重塑物理世界的行动法则?
当全球顶尖的计算机视觉学者与机器人专家在丹佛和维也纳之间“双城赶场”时,一个清晰的技术融合信号已经发出。CVPR 2026现场所呈现的,远不止于论文接收率的数字游戏,而是一场关于AI能力边界重新定义的预演。核心议题的焦点,已经从如何更精准地“看懂”一张图片或一段视频,转向了如何让AI系统基于视觉理解,在充满不确定性和复杂物理规律的现实世界中“动手”完成任务。

从数据洪流到物理法则:研究范式的根本性转变
本届大会高达16,092篇的投稿量和约25%的录用率,延续了顶会竞争的激烈态势。然而,数量背后更值得关注的是质量的转向。论文列表与密集的Workshop议程共同指向一个共识:计算机视觉的研究前沿,正从信息空间的表征学习,大踏步迈向对物理空间的因果理解与交互控制。
这种转变体现在两个层面:一是研究对象的“实体化”,即视觉系统处理的目标从像素阵列转向了具有质量、摩擦、形变等属性的物理对象;二是任务目标的“行动化”,即评估标准从识别准确率、生成逼真度,转向了任务完成成功率、操作鲁棒性和物理常识合理性。例如,一个模型不仅要识别出“这是一个水杯”,还需要预测“如果以某种角度和力度推动它,它会如何移动、是否会倾倒”,并最终生成一套机械臂的抓取和放置动作序列。这要求模型内嵌对物理定律的隐式或显式理解。
中国力量的全栈式崛起:从底层基建到顶层应用
中国学术界和产业界在本届CVPR上的表现,堪称一次生态实力的集中检阅。高校论文产出榜单上,上海交通大学、浙江大学、中国科学技术大学等机构名列前茅,显示了深厚的基础研究积累。而更具标志性意义的是中国企业在产业生态链上完成的完整布局。
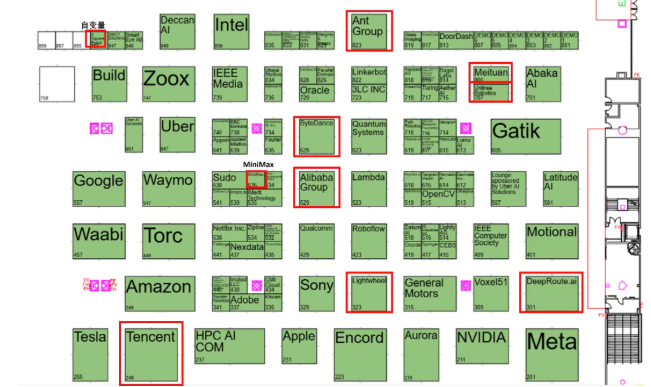
这种布局呈现出清晰的层次感:
- 算力与基础设施层:阿里云、腾讯云、潞晨科技等提供了从底层算力到高效训练框架的支持。
- 模型与算法基座层:字节跳动、MiniMax、百度等公司在多模态大模型(VLM)和视觉-语言-动作(VLA)模型上持续投入,构建通用的认知与决策能力基座。
- 数据与评估层:如Nexdata(数据堂)等企业,专注于构建稀缺的具身智能数据集,包括真实的机器人遥操作数据,为模型训练提供高质量的“燃料”和评测基准。
- 硬件与本体层:宇树科技、Linkerbot、智元机器人等公司,直接研发和提供机器人硬件本体,特别是高自由度的灵巧手,让算法的“大脑”有了可执行的“躯体”。
- 系统集成与垂直应用层:元戎启行、小鹏汽车等在自动驾驶领域,美团在即时物流机器人领域,推动技术的最终落地。
这条覆盖“软硬件-数据-应用”的全栈链条,意味着中国AI产业已具备从技术研发到产品闭环的内生动力,不再局限于单一环节的创新。
技术路线的碰撞与融合:VLA与世界模型的共生之道
大会期间最受关注的产业对话之一,莫过于特斯拉与小鹏汽车在“具身智能基础模型部署”Workshop上的同台。两者虽然都秉持“纯视觉”技术路线,但其分享揭示了当前技术探索的两大支柱。

特斯拉Autopilot负责人Ashok Elluswamy系统性地阐述了如何将自动驾驶视为更广泛的机器人平台的一部分。其FSD系统上下文长度的显著提升,意味着模型在进行决策时,能够考量更长时间跨度的历史信息,这对于理解复杂的、连续性的物理交互场景至关重要。特斯拉展示的Robotaxi避让视频,正是这种长时序理解与瞬时决策能力结合的体现。其战略核心在于,构建一个统一的、能够同时服务于自动驾驶汽车和人形机器人Optimus的“物理世界基础模型”。
小鹏汽车刘先明的观点则更具辩证性。他明确指出,当前业界关于“模块化堆叠”与“端到端世界模型”的争论,或许是一个伪命题。在他看来,视觉-语言-动作模型(VLA) 和 世界模型 并非替代关系,而是互补的:
- VLA模型 的核心是学习“行为范式”,即从海量的人类演示数据(如驾驶视频)中提炼出“在这种情况下,一个熟练的驾驶员会如何操作”。它擅长模仿和泛化已知的专家策略。
- 世界模型 的核心是学习“物理规律”,即预测在给定动作下,环境状态将如何演变。它擅长推理和应对未知的、长尾的极端场景。
两者的融合,才能形成一个既懂得“标准操作流程”,又能在意外发生时基于物理常识进行推理和干预的稳健系统。小鹏宣布其第二代VLA模型已量产落地,且用户辅助驾驶里程占比突破50%,证明了这条融合路径在现阶段的有效性。
真机验证:从仿真沙盘到物理世界的终极考场
任何关于具身智能的宏伟蓝图,最终都需要在物理世界中接受检验。本届CVPR首次大规模引入真机挑战赛,成为技术落地能力的“试金石”。其中,GigaBrain Challenge竞赛设置了从仿真到真机的全链路赛道,结果极具说服力。
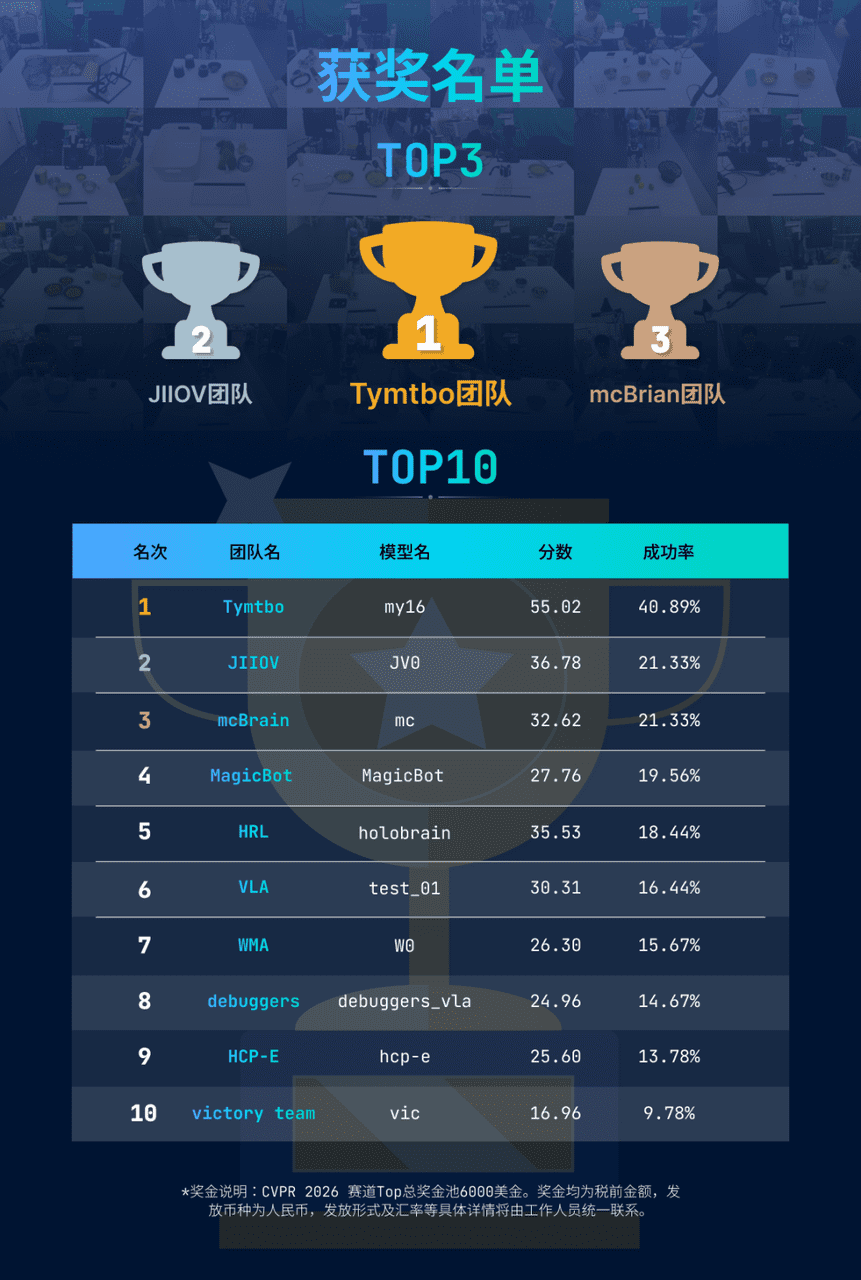
小米机器人团队在RoboChallenge真机赛道中夺冠,其模型“my16”在包含双臂灵巧操作、柔性物体操控等高难度任务的测试中,取得了超过40%的成功率,是唯一突破此门槛的参赛者。这一成绩的含金量在于:
- 任务复杂性高:涉及多种反常识的物理交互,对模型的泛化能力要求极高。
- 评估标准严格:要求使用统一模型连续完成多项任务,考验的是系统的综合能力而非单项特长。
- 真机环境不确定性:与完美仿真的环境不同,真实世界存在传感器噪声、执行器误差、环境干扰等无数变量。
小米采用的“S1/S2双系统架构”,结合了大型模型的规划能力与经典控制器的精准执行能力,并引入长短期记忆模块来保持任务执行的连贯性。这种“分层融合”的设计哲学,与特斯拉、小鹏在自动驾驶领域的技术思路异曲同工,都指向了在追求端到端理想的同时,兼顾系统可靠性、可解释性与安全性的工程实践智慧。
结语:视觉作为桥梁,连接认知与物理
CVPR 2026清晰地勾勒出计算机视觉领域的未来图景:它的使命不再是仅仅充当人类世界的“镜子”,去反射和记录信息;而是立志成为连接数字认知与物理现实的“桥梁”和“手眼”。
这场技术革命的影响将是深远的。在工业制造领域,智能机器人能更灵活地适应非标零部件的分拣与装配;在家庭服务场景,机器人可以真正理解“整理房间”、“准备餐食”等复杂指令背后的物理步骤;在医疗康复中,辅助设备能基于视觉实时理解患者的运动意图和身体状态,提供更精准的助力。
当然,挑战依然巨大。如何让模型获得真正可泛化的物理常识?如何保证在开放物理环境中行动的安全性与伦理性?如何降低海量真实机器人训练数据的获取成本?这些都是横亘在理想与现实之间的关键课题。但无论如何,CVPR 2026已经证明,学术界和工业界正以前所未有的决心和协同,致力于打破CV与机器人之间的“物理结界”。当视觉系统开始学会“动手”,我们迎来的将是一个AI与物理世界深度交融的新阶段。