PS-SR如何打破视频超分的‘不可能三角’?从春晚4K奇观看投机扩散新范式
鱼灯破水而出,凌空游弋于数字古城之上;火狮脚踏烈焰,在虚实交织的舞台奋力腾跃;一群通体透亮的剪纸奔马仿佛挣脱了物理束缚,在巨幅光影壁中疾驰;古典诗词如瀑布般垂挂,于天幕间翻卷流淌——2026年央视春晚合肥分会场《合韵满江淮》,凭借一系列极具想象力的超现实视觉奇观,将观众带入一个亦真亦幻的江淮意境。这些令人叹为观止的4K级画面,其流畅度、清晰度与虚实融合的无缝感,对底层视频素材的质量提出了近乎苛刻的要求。鲜为人知的是,支撑这七分钟视觉盛宴的一项核心技术,源自一项名为PS-SR(Pseudo-Single-Step Super-Resolution)的视频超分辨率框架。这项由智象未来团队提出的研究工作,因其在效率与质量之间取得的突破性平衡,被计算机视觉顶级会议CVPR 2026接收。
将天马行空的创意转化为可供全国直播的春晚级播出信号,远非简单的画面拼接。它要求技术团队在4K(3840×2160)的高分辨率下,高效处理海量的实拍素材与AI生成内容,并且必须保证每秒60帧的流畅播放中,每一帧都经得起逐秒审视与推敲。鱼灯鳞片的光泽反射必须与模拟的水波动态严格同步;剪纸奔马的肌肉线条在高速运动下不能出现丝毫的扭曲或畸变;所有由AI生成的特效元素,都需要与真人演员的实景表演严丝合缝地“生长”在一起,仿佛它们本就是物理世界的一部分。而实现这一切视觉奇观的基石,离不开一项关键的基础能力:视频超分辨率。没有足够清晰、稳定、真实的底层4K画面作为“画布”,后续所有极致的细节雕琢与虚实融合都将成为无源之水。

视频超分辨率技术旨在从低质量、低分辨率的输入视频中,恢复出高质量、高分辨率的视频序列。然而,当这项技术从实验室走向如春晚制作这般真实、严苛的应用场景时,一个长期存在的根本性矛盾便凸显出来:模型究竟应该追求极致的推理速度,还是极致的视觉质量?传统的基于卷积神经网络或Transformer的单步模型,推理速度快,易于部署,能够较好地保持输入输出的内容一致性。但其生成能力往往受限于模型容量与训练目标,在面对严重退化(如压缩伪影、运动模糊、噪声)时,倾向于输出偏平滑、保守的结果,难以“无中生有”地补出真实世界复杂的高频纹理,如细腻的皮肤质感、织物的复杂纹路或远处建筑的清晰轮廓。
另一方面,基于扩散模型的方案为视频超分带来了强大的生成先验。这类模型通过多步迭代采样的过程,能够从随机噪声中逐渐“塑造”出细节丰富、视觉上更加逼真的高清画面。它们擅长处理严重的信息缺失,能够生成令人信服的自然细节。然而,多步迭代的特性意味着高昂的计算成本与缓慢的推理速度。对于需要处理长达数分钟、分辨率达4K的春晚素材而言,使用标准的多步扩散模型进行增强,其时间成本是制作流程所无法承受的。近年来出现的单步扩散蒸馏方法试图破解这一困局,但简单的知识蒸馏往往导致单步模型难以完整继承教师模型在多步迭代中展现出的“创造力”,在复杂纹理生成上容易退化回平均化的预测,丢失视觉丰富度。
PS-SR框架的提出,正是基于一个核心洞察:在视频超分的多步扩散过程中,并非每一步的计算都同等“昂贵”或关键。第一步采样往往承担着确定画面全局语义、主体结构和低频内容的重任,这一步的准确性直接决定了输出内容的“根基”是否稳固。而后续的许多步骤,实际上是在这个稳固的基础上进行高频细节的反复细化与增强。因此,智象未来的研究团队设想,能否让一个强大的“基础模型”只负责执行这最关键的第一步,打好地基,然后让一个轻量级的“草稿模型”来高效地完成后续的细节补充工作?这种思路催生了“投机扩散”的概念。

PS-SR的推理流程清晰地体现了这种不对称的协作设计。整个系统由两个模型共同驱动:一个强大的基础模型和一个轻量的草稿模型。基础模型通常基于一个大规模预训练的视频扩散模型进行微调,它被赋予的任务是进行一次完整的前向传播,从低质量输入中预测出高质量视频的全局概貌。这一步的输出已经包含了正确的语义、稳定的结构和主要的低频信息,回答了“画面应该是什么”的根本问题。
随后,草稿模型登场。这个模型是基础模型的一个轻量化版本,例如通过剪裁部分网络层来实现。为了确保轻量化的草稿模型仍能获得强大的特征表示来指导细节生成,PS-SR采用了特征拼接与融合的策略:将基础模型对应网络层输出的丰富特征图提供给草稿模型,再通过一个轻量的全连接层进行维度调整与融合。这样,草稿模型无需从头开始理解整个视频内容,它只需要在基础模型已经提供的、高质量的“半成品”基础上,专注于推测并补全那些缺失的高频纹理和细微细节。在训练阶段,两个模型也各有侧重:基础模型需要在潜空间和像素空间进行综合训练,学习从低质到高质量的速度场,并借助对抗损失等提升视觉真实感;而草稿模型的训练则更聚焦于像素空间的细节修复,主要优化如L2损失、LPIPS感知损失等,以学习如何有效地进行局部增强。
最终,PS-SR实现了一种“1+x”的采样体验:一次完整的基础模型采样,加上多次快速的草稿模型细化步。它在形式上并非严格意义上的单步模型,但在计算效率上却无限接近于单步推理,同时保留了多步扩散模型所擅长的、渐进式的细节生成能力。这种设计巧妙地规避了传统单步模型生成能力不足与多步模型计算昂贵的双重缺陷。
然而,允许模型进行多步细化也带来了新的风险:模型可能在追求更高清晰度的过程中,逐渐偏离原始输入的内容,产生语义漂移。例如,为了让人脸看起来更“清晰”,模型可能会擅自改变人物的五官特征;为了增强建筑纹理,可能会重绘出原本不存在的窗户结构。这对于要求高保真还原的影视级应用是不可接受的。为了解决这一问题,PS-SR引入了其第二个关键创新:频域更新规则。
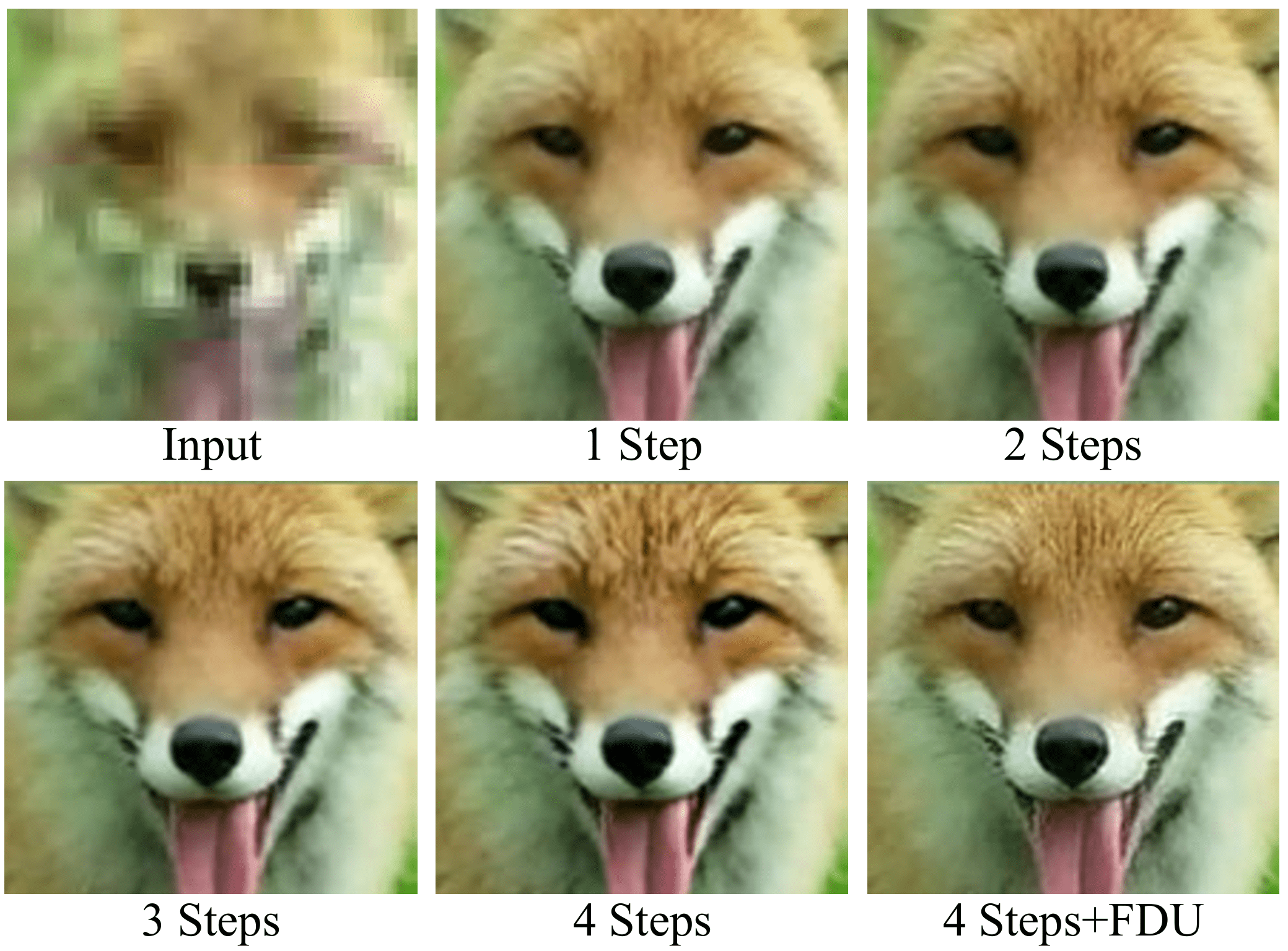
这条规则的核心思想是,在草稿模型进行后续细化时,严格限制其只能修改图像的高频成分,而必须完整保留前一步结果中的低频结构信息。具体实现上,PS-SR将当前帧与新预测帧转换到YUV色彩空间,并聚焦于携带大部分结构信息的亮度通道。通过高通滤波器提取出新预测帧相对于当前帧的高频细节增量,然后经过一个自适应的权重图进行调制,最后再与当前帧的低频内容以及色度通道重新组合,得到最终的输出帧。
这意味着,基础模型奠定了画面的“骨架”与“形体”,草稿模型负责为其增添“肌肤”与“纹路”,而频域更新规则则扮演了“质检员”的角色,确保草稿模型添加的每一笔细节都严格在既定轮廓内进行,不会越界成为内容上的重绘。消融实验清晰地展示了这一规则的重要性:当移除频域更新约束后,模型输出虽然可能在局部显得更锐利,但整体上会出现明显的结构偏移和内容不一致,破坏了视频超分任务最基本的忠实性原则。
那么,PS-SR在实际评测中的表现究竟如何?研究团队在多个标准数据集上进行了全面评估。在合成数据集方面,如UDM10、SPMCS和YouHQ40,PS-SR在PSNR、SSIM、LPIPS等多个客观质量指标上均取得了领先或极具竞争力的结果。例如在UDM10上,其SSIM达到0.7547,LPIPS为0.2444,均优于对比的多步扩散模型STAR、SeedVR以及单步蒸馏方法DLoRAL等。这些数据表明,PS-SR在具有清晰参考真值的情况下,具备出色的重建保真度。
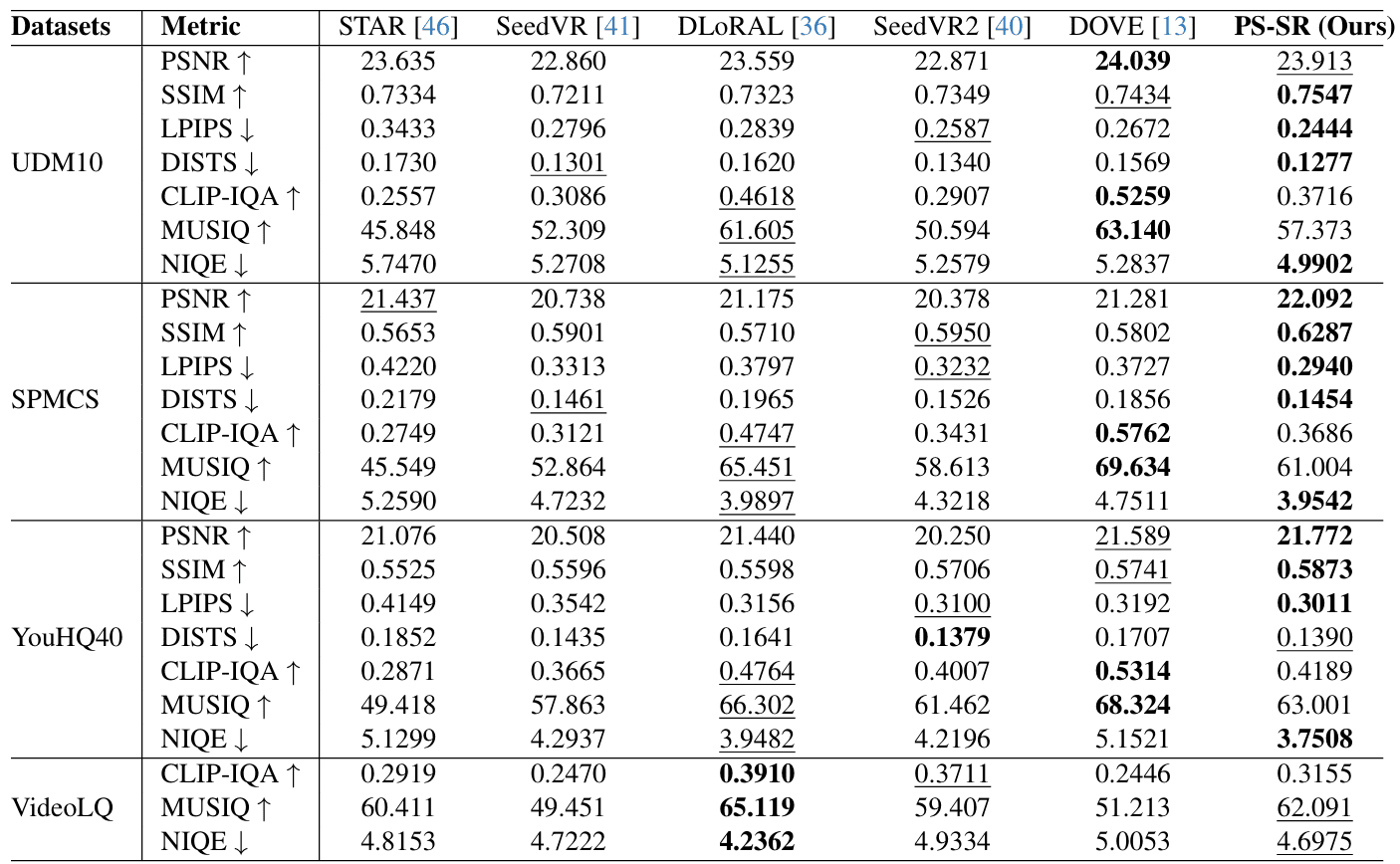
更重要的是,PS-SR的设计目标并非盲目追求无参考锐度指标的最高分。一些方法可能在CLIP-IQA或MUSIQ等衡量感知质量的指标上得分更高,但这有时是以牺牲内容一致性、引入过度锐化或伪影为代价的。PS-SR通过基础模型定调、草稿模型细化、频域规则约束的三重机制,旨在达成重建准确性、视觉细节丰富度以及输入内容一致性三者之间更优的平衡。这种平衡对于影视、广电等专业领域至关重要。
在时序一致性方面,PS-SR也表现出显著优势。视频超分不仅要求单帧质量高,更要求连续帧之间过渡平滑自然,避免出现闪烁、抖动或内容漂移。可视化对比显示,PS-SR处理后的视频序列,在运动物体的边缘和纹理区域,帧与帧之间的对齐更加稳定,由模型生成的新细节能够随着物体的运动而连贯地变化,有效减少了令人不适的视觉闪烁现象。

效率是PS-SR的立身之本。在NVIDIA A800 GPU上,对一段29帧、分辨率为720×1280的视频进行超分处理,经典的多步扩散模型STAR(15步)需要98.61秒,SeedVR(50步)更是高达188.93秒。而作为单步方法代表的DOVE耗时20.43秒。PS-SR采用“1+3”步的投机扩散配置,即1步基础模型加3步草稿模型,总耗时仅为21.11秒。这个时间仅仅比最快的单步方法DOVE增加了不到1秒,却相比SeedVR快了近9倍,相比STAR快了约4.7倍。这种效率提升使得将扩散模型级别的视频增强质量应用于长视频、高分辨率内容的生产流程成为可能。

PS-SR的成功实践,为高保真视频增强领域提供了一种极具启发性的新范式。它打破了长久以来困扰业界的“速度-质量-一致性”不可能三角的僵化认知。其意义远不止于提出了一个新的SOTA模型,更在于它展示了一种更加灵活、高效的计算资源组织方式。通过将计算任务进行角色化分配——让大模型做它最擅长的、决定性的全局推理,让小模型做它力所能及的、高效的局部优化——并在关键路径上施加内容约束,PS-SR证明了高质量的视频生成未必需要全程“重装行进”。
这种“伪单步”的哲学,本质上是对扩散过程的一种解构与重组。它承认多步迭代对于生成丰富细节的必要性,但质疑其每一步都必须由完整大模型执行的必要性。对于视频修复、历史影像高清化、流媒体低码率视频增强、实时通讯画质提升以及影视特效制作等广阔场景而言,PS-SR指明了一条兼顾极致画质、高效推理与工业级可靠性的技术路径。春晚合肥分会场那七分钟的视觉奇迹,正是这条路径上一次成功的压力测试与华丽亮相,预示着扩散模型正从学术研究的“炼金术”,稳步走向产业应用的“工程学”。