机器人为何需要‘有依据地行动’?GuidedVLA 如何让 VLA 更可控可解释?
一、从“能动”到“懂动”:机器人行动的解释性瓶颈正在凸显
当机器人在工厂拧紧一颗螺丝时,只要重复精度足够高,问题尚可容忍;但一旦环境变得复杂——比如桌面物品散乱、目标物体部分遮挡、光照剧烈变化——机器人便可能突然失灵。此时,人们最关心的已非“它能否动”,而是“它为什么停下了?”
这个问题直指当前主流视觉-语言-动作模型(Vision-Language-Action, VLA)的结构性缺陷:多数端到端 VLA 将“感知→推理→动作”压缩为单一神经网络流,动作由隐式特征解码输出。这种设计虽提升了训练简洁性与端到端性能上限,却也带来了严重的黑箱性——模型输出一个抓取动作,却无法说明它是基于哪个物体、哪段任务进度、还是哪块空间区域做出的判断。
在静态、理想实验室环境中,这种隐式机制尚可维持基本鲁棒性;但真实世界并非如此。一项任务往往包含多阶段序列操作(如“抓取→移动→对准→插入→释放”),且每个阶段对不同信息敏感:抓取阶段依赖目标定位精度,移动阶段关注路径语义,插入阶段则高度依赖空间几何约束。当模型不能显式处理这些分工时,失败便会以“系统性漂移”形式扩散:一次目标误判引发后续步骤连锁错误,而工程师只能通过重训模型或添加数据盲目调优,效率极低。
正如复旦可信具身智能研究院团队所指出的:可控性与可解释性不是VLA的附加属性,而是其走向高阶泛化任务的基础设施。
二、GuidedVLA 的设计哲学:显式引导,而非端到端黑箱重构
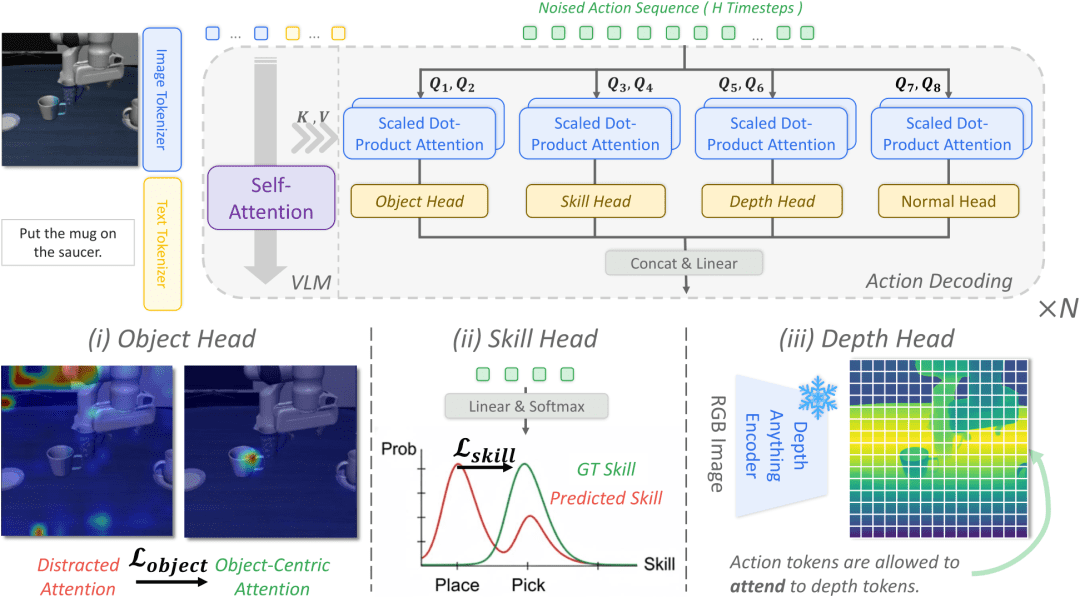
面对上述挑战,GuidedVLA 提出一种“最小扰动式增强”思路:在保留原有主干网络能力的前提下,于动作解码器中引入三类专业化注意力头(Attention Heads),分别承担目标(Object)、技能(Skill)、深度(Depth)三种任务相关因素的显式建模。其结构设计遵循三大原则:
1. 显式分工,而非隐式学习
团队并未增加新参数暴力堆叠模块,而是对已有 Transformer 解码器的注意力头进行“责任分配”:
- Object Head:固定若干头专门关注目标物体掩码区域,抑制背景噪声与干扰物,提升鲁棒性;
- Skill Head:使特定注意力路径与任务阶段标签对齐,强化对“当前应处于抓取/移动/放置哪一阶段”的敏感度;
- Depth Head:引入冻结的深度编码器(如 ZoeDepth)输出特征,注入几何先验,弥补 2D 图像对空间关系建模的不足。
这三类注意力头并非替代主干网络,而是在其之上形成可插拔、可归因的控制分支。
2. ControlNet 式残差适配:平稳迁移,零初始化防护
为避免新增引导干扰已有知识,GuidedVLA 采用**零初始化投影(zero-initialized projection)**策略:
- 主干注意力分支正常执行原始动作生成;
- 新增的 factor-specific 分支经线性变换后,以残差形式与主分支融合;
- 初始权重为零,因此训练初期仅轻微扰动;
- 随训练推进,梯度逐步激活引导能力。
该机制确保模型在学习新引导时,不会因早期剧烈扰动而陷入局部最优或破坏预训练能力,大幅提升了训练稳定性。
3. 自动化标注流水线:大幅降低数据成本
监督三类头需要对应标签:
- 目标掩码:由 Qwen3-VL 生成 point prompt,再通过 SAM2 在视频段中传播;
- 技能标签:由 Qwen3-VL 根据任务描述与预定义技能本体生成;
- 深度引导:直接使用冻结深度编码器输出,无需人工标注。
实测表明,该流水线处理 50 个 episodes 仅需约 4 分钟(对比人工需 43.5 分钟),且 92% 的 episodes 无需人工修正——效率提升超 10 倍,标注成本逼近监督学习边缘。
三、从仿真到真实:GuidedVLA 的多场景验证
3.1 仿真基准:鲁棒性提升显著
在 LIBERO-Plus 上,团队测试了 7 类扰动下的泛化能力:相机视角偏移、机器人初态扰动、语言指令变化、光照变化、背景纹理更换、传感器噪声、物体布局改变。
| 方法 | 总成功率 |
|---|---|
| π0 基线 | 68.2% |
| GuidedVLA | 75.4% |
进一步单头消融实验揭示分工的针对性优势:
- Object Head 在含干扰物、小目标任务中优势突出(+5.8%);
- Skill Head 在多阶段任务中显著提升(如“夹→移→放”三步任务成功率+6.2%);
- Depth Head 在几何敏感任务(如插拔、按压)中单独贡献达 +8.7%。
这证明:三类分工并非简单堆叠,而是实现了问题类型与建模能力的精准匹配。
3.2 RoboTwin 2.0:高难度操作任务中突破瓶颈
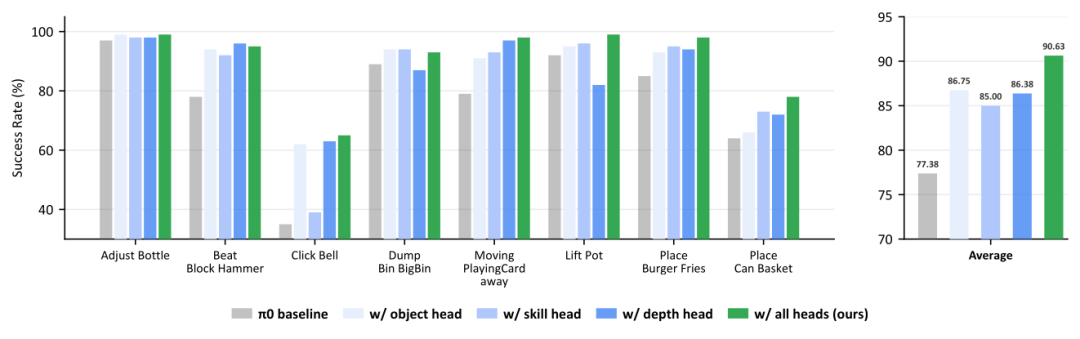
在 RoboTwin 2.0 的 8 项随机化操作任务中,GuidedVLA 将 π0 的平均成功率从 77.38% 提升至 90.63%。关键案例包括:
- Click Bell:需精准控制 Z 轴位移。Depth Head 使成功率从 35% → 63%(+28%);
- Beat Hammer Block:要求锤头与金属块严格对齐。Depth Head 带来成功率从 78% → 96%(+18%);
- Lift Pot:需稳定抓取、防倾覆抬升、避免碰撞桌面。Skill Head 在该任务中单头表现最优。
这些结果清晰表明:当任务依赖某一类因素时,专业化引导头能定向补足短板。
3.3 真实机器人平台:家庭与实验室任务双验证
团队在双臂机器人平台 ALOHA AgileX 与 PSI-Bot RealMan 上部署了 GuidedVLA:
- ALOHA:执行水果分拣、叠碗、桌面清洁;
- PSI-Bot:处理实验室场景——将透明烧杯放入加热套、套叠烧杯、烧杯放置到加热台等。
测试聚焦于透明物体定位难、几何约束紧的挑战性任务。每任务运行 20 次,结果表明:
| 测试场景 | Base Policy | GuidedVLA | 提升幅度 |
|---|---|---|---|
| In-Domain 平均 | 55.8% | 75.8% | +21.5% |
| Scene 平均 | 44.2% | 67.5% | +52.7% |
| Lighting 变化 | 57.5% | 79.2% | +37.7% |
尤其在“透明烧杯插入加热套”任务中,Base Policy 多次因无法感知烧杯深度与套口对齐失败,GuidedVLA 凭 Depth Head 实现稳定对接,成功率从 21% 提升至 72%。
四、可解释性不再“玄学”:从定性观察到定量归因
GuidedVLA 的最大创新在于:将“可解释性”从主观叙事转化为可测量、可优化的工程指标。
论文对三类引导头的注意力分布与任务成功率进行定量分析:
- 目标注意力集中度:当 Object Head 在目标区域内的注意力比例从 0.25 提高到 1.0,任务成功率从 61.3% → 77.4%(+16.1%);
- 阶段识别准确率:Skill Head 的技能分类准确率提升,成功率从 66.2% → 77.7%(+11.5%);
- 深度特征依赖度:Depth Head 中真实深度特征占比从 0 → 1.0,成功率从 15.0% → 76.2%(+61.2%)。
这些数据揭示一个关键事实:当模型“有意识地”关注目标、阶段与深度时,性能提升不是线性平滑的,而是呈现阶跃式增长。
这为机器人系统提供了前所未有的“失败诊断接口”:当任务失败时,工程师可直接查询:
- 目标注意力是否偏离?→ 优化 Object Head;
- 技能识别是否错乱?→ 重构 Skill Head 的阶段边界;
- 深度估计是否失效?→ 调优 Depth Head 输入或校准传感器。
五、未来路径:从可控VLA走向可扩展具身智能
GuidedVLA 所代表的,是一种面向真实部署的务实范式转变:
- 从“黑箱泛化”到“白箱可控”:不再追求单一参数空间的最大性能,而是构建可理解、可干预的决策结构;
- 从“全量重训”到“模块增强”:通过插件式设计,让旧模型快速升级为可解释新系统;
- 从“人工经验驱动”到“数据-指标双驱动”:以注意力分布、阶段识别率等指标指导训练优化。
未来,这类方法可进一步扩展至:
- 多模态引导(加入触觉、力控信号);
- 层级化引导(对长程任务进行更细粒度阶段划分);
- 闭环自适应(引导策略本身可在线调整)。
机器人要真正进入人类生活空间,不仅需要“手脚灵巧”,更要“耳聪目明且知其所以然”。GuidedVLA 正在为具身智能打下一座“可解释性地基”——让每一次成功都清晰可溯,每一次失败都罪责分明。