从结构预测到智能体闭环:AI如何将药物发现从十年赌局变为可编程工程?
当前药物研发领域存在一个令人沮丧的“双十定律”:平均耗时超过10年,耗资超过20亿美元,而最终能够通过重重临床试验获得上市批准的候选药物,成功率不足10%。这一巨大漏斗的背后,是极其低效的分子发现起点。无论是依赖动物免疫、超大规模化合物库的随机筛选,还是从康复者血液中挖掘抗体,这些传统方法都带有强烈的偶然性与不可控性,本质上是在庞大的化学空间中盲目搜索。Latent Labs创始人Simon Kohl指出,问题的核心在于“我们从错误的分子出发”。如果能够从头开始,针对特定靶点精准设计出最有可能成功的药物分子,整个行业的效率与成本结构将被彻底重塑。
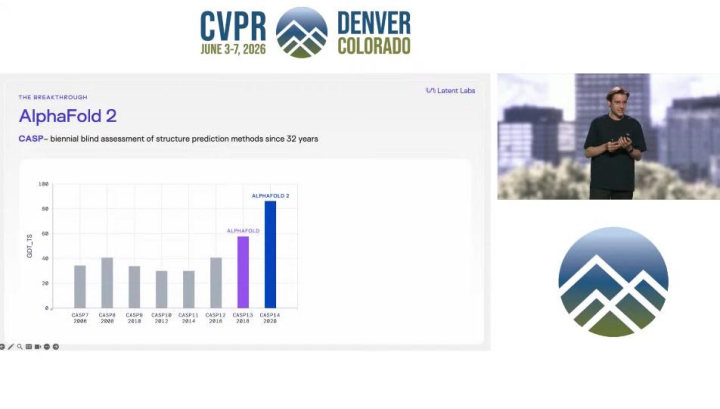
这一愿景的实现,依赖于计算生物学在过去五年中取得的指数级进步。其发展轨迹与人工智能的其他领域惊人地相似,遵循着“基础突破 → 工具涌现 → 应用爆发”的路径。2020年AlphaFold 2的横空出世,解决了困扰生物学界半个世纪的蛋白质结构预测问题,其预测精度已达到实验水平。这不仅仅是单项技术的胜利,更重要的是,它如同计算机视觉领域的ImageNet,为整个领域提供了一个可靠的“预测器”(Oracle)和评估基准,从而催生了“数据集-评估-预测器-生成器”的产业飞轮。当我们可以高精度地“看到”蛋白质的结构时,下一步自然就是学会如何“创造”具有特定功能的蛋白质,这正是生成式AI介入的起点。
蛋白质是生命的功能执行者,其特性决定了药物设计的苛刻性。它由20种氨基酸以特定序列组成,并折叠成复杂的三维结构。关键在于,结构决定功能,且蛋白质系统异常“脆弱”。一个氨基酸的突变就可能导致整个蛋白质结构坍塌、功能丧失,这与图像识别中改变一个像素通常不影响整体识别有着本质区别。这种“零容错”特性,使得药物设计必须达到原子级别的精度。因此,生成式药物设计可以被形式化为一个严格的条件生成任务:在给定靶点蛋白(包括其序列与三维结构)的条件下,生成一个能与之高特异性、高亲和力结合的分子。
Latent Labs推出的Latent—X1模型,正是这一范式的早期实践。该模型将靶点表示为原子点云,作为条件输入,利用去噪扩散模型从随机噪声开始,逐步“雕刻”出结合物的三维结构。其工作流程体现了“设计-验证”的闭环思想:指定靶点及精确结合位点后,由模型生成候选分子,再使用AlphaFold 2/3类结构预测模型进行交叉验证,评估预测结构与设计意图的一致性及结合置信度。最终,只有通过计算筛选的佼佼者才会进入湿实验室进行表达与结合测试。

作为通用蛋白结合物设计的基础模型,Latent—X1在纳米抗体、迷你结合蛋白等多种模态上展现了强大能力,其设计分子的亲和力可达纳摩尔至皮摩尔级别,已非常接近成熟药物的结合力标准。然而,生物制药的皇冠明珠是抗体药物。抗体设计被称为该领域的“圣杯”,因其结构更复杂、需要同时兼顾可变区与恒定区,且直接对应市场规模最大的生物药类别。2024年底发布的Latent—X2实现了零样本药物级抗体设计的突破。这意味着,模型可以针对一个全新的、从未在训练数据中出现过的靶点,直接设计出具有高亲和力的抗体,而无需针对该靶点进行任何额外的数据训练或模型微调。
更值得关注的是Latent—X2在“药物相似性”多目标优化上的表现。一个理想的药物分子不仅需要结合力强,还需具备高热稳定性、高表达量、低聚集倾向、低脱靶风险等多重属性。传统优化过程如同“打地鼠”,改善一个指标常导致另一个指标恶化。数据显示,Latent—X2的设计中,有近半数候选分子能一次性跨过所有关键属性的阈值,其综合品质已与已上市抗体药物相当。这揭示了生成式AI的另一个优势:它能够在广阔的化学空间中进行智能搜索,直接找到同时满足多个约束条件的“帕累托最优”区域,而非在局部进行艰难的权衡。

在针对“不可成药”靶点KRAS以及困难靶点离子通道NAV1.7的案例中,Latent—X2仅用少量设计(10个左右),其结合效力就能与通过万亿级化合物库筛选得到的最佳结果相媲美,甚至超越。这标志着研发范式的根本性转变:从依赖物理实体和运气的“大规模随机筛选”,转向基于计算和智能的“精准定向设计”。前者消耗数月时间和巨额试剂成本,后者仅需数天计算和数周验证,成本与效率的差异是指数级的。
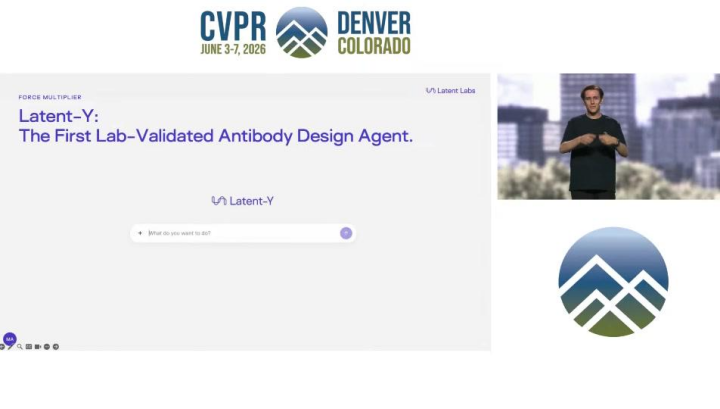
技术的演进并未止步于生成模型。真正的“可编程”意味着将复杂流程封装成简单的接口。Latent—Y作为全球首个实验室验证的抗体设计智能体,代表了这一方向的前沿。用户只需输入一条自然语言指令,如“生成一个阻断人IL-6的纳米抗体”,智能体便能自主完成后续所有步骤:解析靶点蛋白、检索相关数据库、分析结合位点、运行生成模型、进行结构验证与属性预测,最终输出经过初步筛选的候选分子序列。更有挑战性的测试表明,智能体甚至能直接阅读《科学》、《自然》等期刊的论文PDF,自行理解文中描述的生物学机制,并据此设计相应的功能性抗体。
尽管进展迅猛,该领域仍面临诸多深刻的开放性问题,这些问题是生物学完全“工程化”之前必须跨越的鸿沟。首先是蛋白质动力学问题。当前模型主要处理静态的蛋白质“快照”,但蛋白质在体内是动态的、柔性的,其功能往往依赖于构象变化。准确模拟这种动态行为对于设计酶催化剂或别构调节剂至关重要。虽然机器学习力场正在改进传统分子动力学的计算精度与效率,但要实现生理相关时间尺度的模拟,仍需要算法与算力的双重突破。
其次是人体内药物响应与系统性毒性的预测。这是将药物从实验室推向临床的最大障碍。一个分子在试管中能完美结合靶点,但在复杂的人体环境中可能无效,甚至产生意想不到的毒性。这本质上是一个复杂系统预测问题,依赖于对人体生理网络更全面、更精细的理解。解决之道不在于更复杂的理论推导,而在于大规模、标准化、机器学习友好的生物医学数据的积累。这包括多组学数据、临床影像数据、真实世界疗效数据等。只有基于足够高质量的数据,才能构建出可泛化的体内药效与毒性预测模型。
从更宏观的视角看,生成式AI驱动的药物设计正在引发产业链的重构。其影响可能层层外溢:最初是治疗性蛋白质与抗体的设计;随后是更复杂的多特异性药物、细胞治疗与基因疗法的载体设计;进一步地,AI可以用于设计新型研究工具(如高特异性探针),以加速基础生物学研究和靶点发现本身,从而解决“靶点瓶颈”问题。最终,当设计、验证、生产环节都实现高度自动化和智能化时,我们迎来的将不仅是个别药物的快速开发,而是一个能够按需响应、针对各种疾病快速生成个性化治疗方案的生物医学工程新范式。

回顾从AlphaFold 2的预测突破,到Latent—X系列的条件生成,再到Latent—Y的自主智能体,计算药物设计的发展轨迹清晰表明,生物学研究正在经历从“发现”到“发明”、从“观察”到“编程”的深刻转变。这个过程并非一蹴而就,它需要跨学科人才的深度融合(计算科学、结构生物学、化学、临床医学),需要持续的数据基础设施投资,也需要对湿实验室自动化与数字化进行长期投入。然而,其方向是明确的:通过将生物学的“语言”(序列、结构、相互作用)转化为计算机可理解和操作的代码,我们正在构建一套强大的“生物编程”工具集。这套工具集的成熟,终将使得针对特定疾病设计安全有效的药物,变得像今天为特定功能编写软件一样,成为一个可迭代、可优化、可规模化的工程过程。这不仅是制药工业的效率革命,更是人类拓展健康疆域的一次能力跃迁。