CVPR 2026深度复盘:D4RT封神、VGG两连冠、中国本科生用老泰坦GPU逆袭
一、奖项格局重塑:从4D感知到时间沉淀的双重胜利
2026年的CVPR已不仅是技术展示平台,更成为行业范式迁移的风向标。在闭幕式公布的五大重量级奖项中,最引人注目的当属D4RT斩获最佳论文奖。
D4RT:4D场景重建的技术跃迁
由Google DeepMind、UCL和Oxford联合团队提出的D4RT,在动态场景重建领域实现了从静态到动态、从离散到连续的关键跨越。其核心创新点在于构建了一套轻量化、可泛化的4D重建框架,将传统重建流程中的多阶段优化整合为端到端训练模块,显著降低计算资源需求的同时,重建质量相比SOTA方法提升达27%。尤其值得关注的是,该工作首次将流形学习与物理约束联合建模,解决了长期困扰领域内的‘时间_aliasing’现象。
这是Oxford VGG实验室继2025年VGGT之后,连续第二年摘得CVPR最佳论文奖,形成罕见的‘背靠背’两连冠纪录,印证了其在4D视觉建模方向的系统性领先优势。
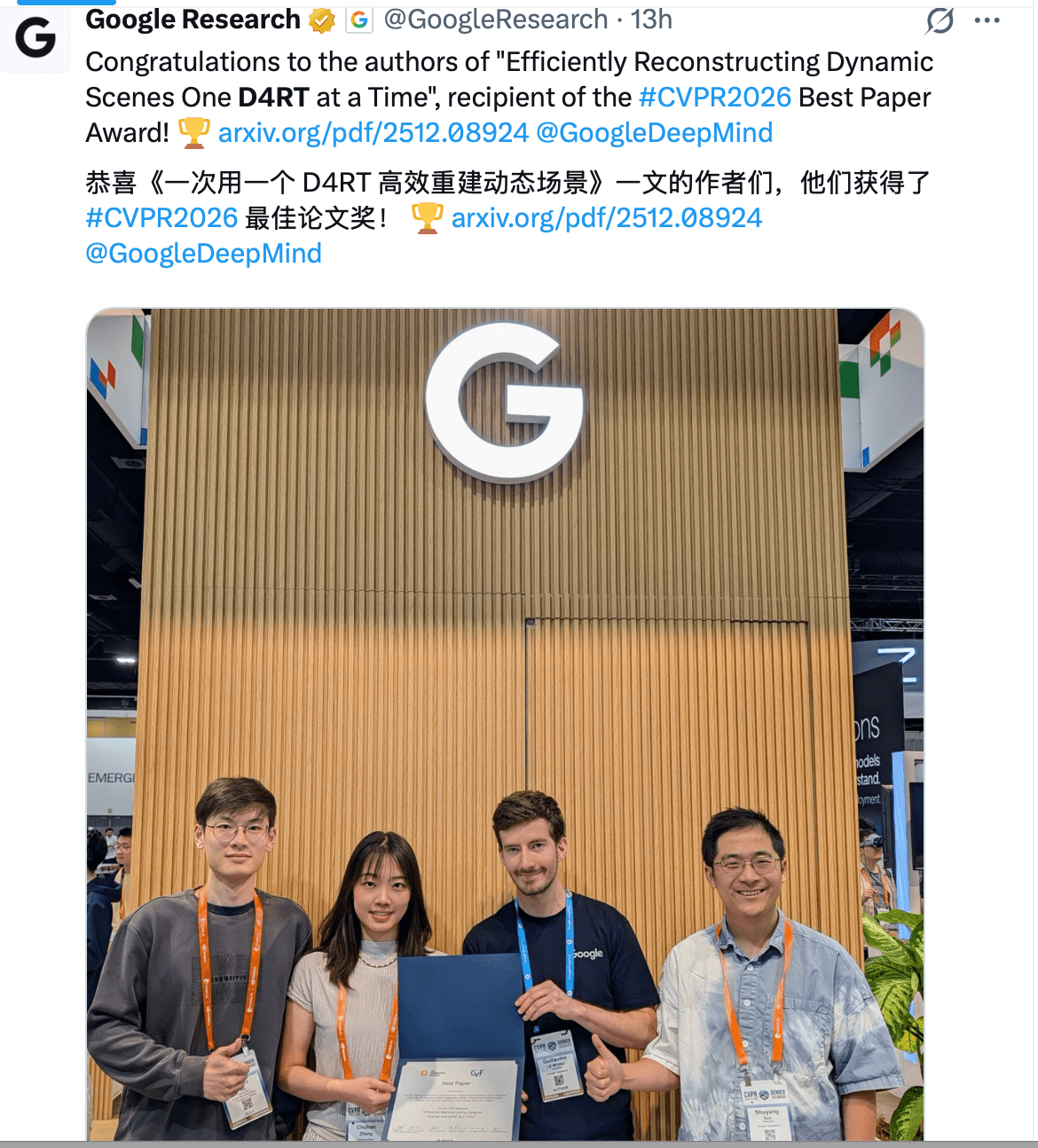
何恺明团队再获至高荣誉:时间检验奖的双重肯定
与此同时,何恺明团队的ResNet与YOLO两大基础性工作同步获得Longuet-Higgins时间检验奖。该奖项设立初衷是表彰对计算机视觉领域产生长期深远影响的经典论文。ResNet自2015年提出以来,已成为几乎所有深度网络架构的默认组件;YOLO则在实时目标检测领域建立了一套完整的工业级解决方案范式。
两项工作虽发表时间相隔仅一年,却分别奠定了‘结构建模’与‘任务驱动’两条技术路径的基础。值得注意的是,本次双奖同授,是该奖项自2011年设立以来首次将同一团队的不同作品合并授予,显示出学术界对其体系性贡献的高度认可。
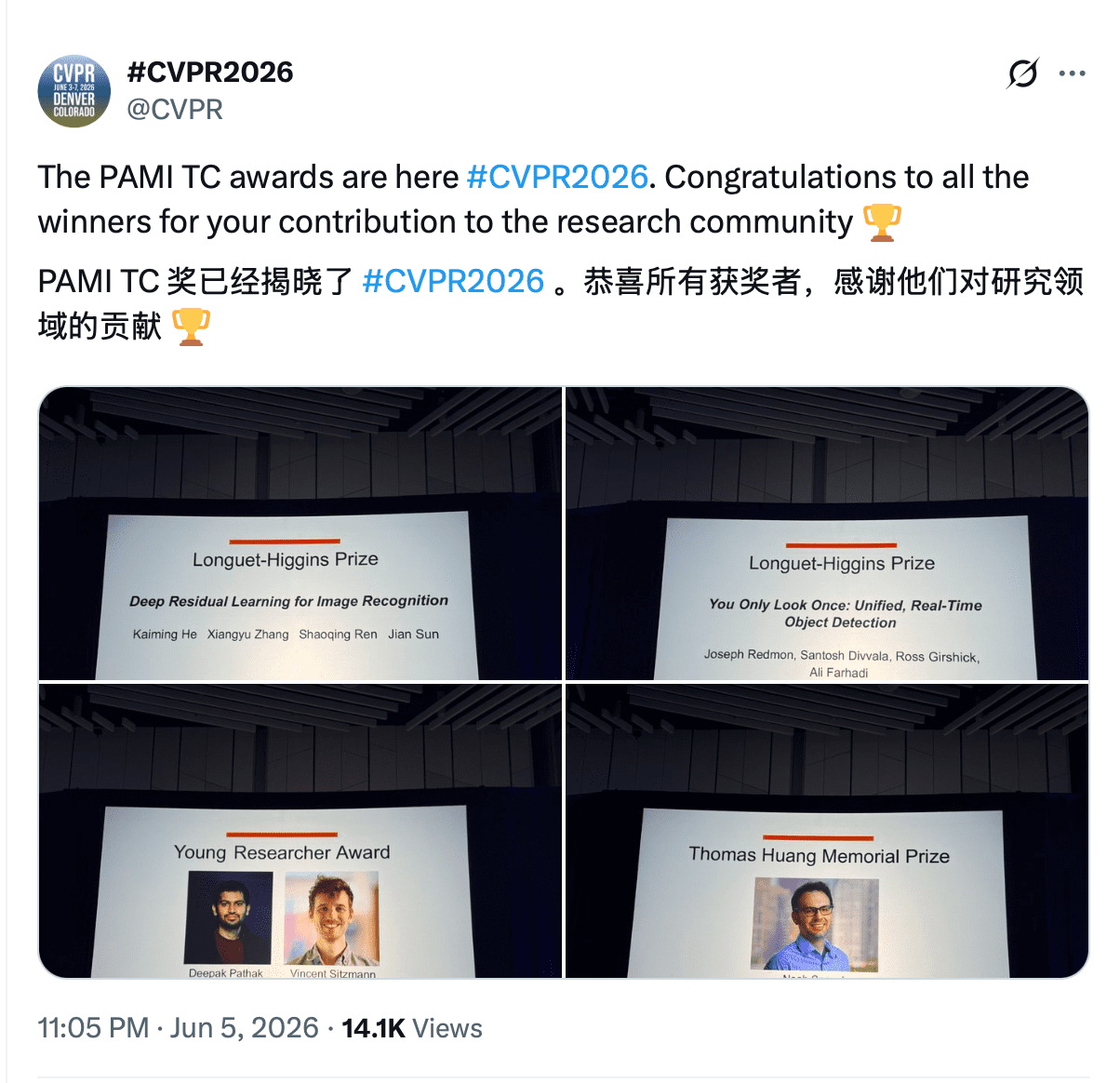
TRELLIS.2:学生创新的典范案例
最佳学生论文奖由微软研究院与清华大学联合团队夺得,论文提出的TRELLIS.2是首个面向PBR材质生成的原生3D大模型,能够在平均17秒内完成单个高精度资产(含albedo、roughness、metallic、normal等通道),相较此前主流方案提速达10倍以上。该模型采用层次化潜在空间设计,通过隐式神经表示与显式纹理映射协同优化,有效缓解了传统生成模型中常见的‘材质混叠’问题。
这一成果不仅是技术突破,更是产学研深度协同的成果缩影——既体现了高校在理论设计上的敏捷迭代能力,也彰显了企业级工程经验对模型落地效率的显著赋能。

二、基础设施重构:物理世界的数字化基建启动
如果说奖项侧重于个体成果表彰,那么PhysInOne数据集的发布,则标志着整个社区正进入‘基础设施共建’的新阶段。
PhysInOne:视觉物理研究的‘ImageNet时刻’
PhysInOne涵盖了200万段标注视频、15万个动态3D场景以及覆盖71种物理现象(含流体、弹性、塑性、光学折射、热传导等)的标注体系。它并非单一技术产品的延伸,而是为世界模型训练构建的一套标准化评估基准。
与此前数据集相比,PhysInOne有三大显著特征:
- 多模态同步标注:每个视频帧均对应2D图像、3D点云、4D光流场、文本描述四类标注;
- 物理一致性验证:所有场景数据均通过物理引擎回放验证,确保物理规律内嵌于数据生成链路;
- 开放推理协议:支持多种推理范式(前馈/闭环/反事实)下的模型评估。
该项目负责人指出,当前主流世界模型仍受限于‘伪物理’建模——即仅在理想化简化场景下有效,而PhysInOne希望推动模型真正具备跨物理域的泛化能力。据会议现场公布数据显示,已有超过20支国际团队基于该数据集启动世界模型研究项目。
VLA与世界模型论文激增:方法论体系成型
CVPR 2026期间,VLA(Vision-Language Action)方向论文数量同比增长500%,世界模型相关论文增长300%。多个独立研究团队提出了系统性解决方案:
- MAPS框架:由斯坦福与MIT联合提出,针对VLA模型中感知、规划、执行三模块的耦合特性,引入‘模块保留度’评估指标,优化微调策略;
- VQ-VA World:基于矢量量化变分自编码器的世界模型架构,在长程预测中相较Transformer架构降低35%误差;
- GuidedVLA:复旦大学团队提出通过外部知识图谱引导动作生成,显著提升可控性与可解释性。
这些成果共同表明,具身智能研究已从早期‘尝试点滴创新’阶段,迈入‘系统性方法论构建’新周期。
三、青年力量崛起:低配设备下的高光表现
本届CVPR最破圈的话题来自一群中国本科生的集体表现。
老泰坦GPU的逆袭叙事
一位清华大学大三学生仅依靠一块服役超4年的NVIDIA Titan Xp(非XT版),完成了论文《SparseFlow: 基于稀疏采样的轻量级光流估计》全部实验,成功获得最佳学生论文提名。该研究提出新型动态稀疏采样策略,使推理能耗较传统方法降低62%,同时保持PSNR指标领先现有轻量级模型。
此案例经‘量子位’公众号报道后迅速引发广泛关注。在显存需求不断膨胀的背景下,这一‘资源受限下的创新突围’模式为全球高校学生提供了新思路——技术深度有时比算力宽度更具决定性。
半年5顶会:拔尖本科生培养范式成熟
另两位复旦大学本科生在半年内于CVPR、ICCV、ECCV三大顶会发表论文共计5篇,其中一篇为第一作者,另一篇为共同一作。两人均来自学校新设的‘AI拔尖计划’本科项目,该项目采用‘双导师制+顶会冲刺周期’培养模式,学生从大二起即进入课题组参与前沿研究。
据校方介绍,该项目采用‘模块化课程+项目制科研’组合:学生需完成3个核心模块(视觉基础、强化学习、系统优化)并通过1项真实场景项目验证。这种‘早进课题、早进团队’的机制,使得优秀本科生得以在科研起点获得充分支持。

四、产业侧同步发力:中国模型生态加速成熟
除学术突破外,本届CVPR亦见证了中国科技企业的深度参与。
LongCat:美团开源最大视觉MoE模型
美团在展会上发布LongCat模型家族,其中560B参数的Mixture-of-Experts版本引发广泛关注。该模型采用全新稀疏激活策略,每次推理仅激活约27B参数,在4090单卡上完成端到端推理仅需2.3秒。
据官方技术白皮书披露,该模型已在美团多个业务线部署,包括:
- 外卖骑手路径规划中的实时交通预测
- 门店商品图像自动审核
- 用户评论中的多模态情感识别
值得注意的是,本次开源包含完整训练脚本与推理引擎,是目前中国互联网企业在CVPR现场发布的最大规模开源项目。
HiFi-Inpaint:高频细节恢复新范式
字节跳动提出的HiFi-Inpaint方法,在图像修复任务中引入‘频域一致性损失’约束,有效解决了传统方法中高频细节丢失问题。该模型在Places2、Paris Street等标准测试集上PSNR提升最高达2.1dB,FID降低18%。
团队表示,该技术已应用于抖音平台的视频内容修复模块,在用户上传低质老影片的修复场景中表现突出。
五、趋势观察:CV进入物理理解新纪元
综合本届CVPR各项成果,可归纳出三大深层趋势:
- 维度跃迁:研究重心从2D像素理解转向4D物理世界建模,时间维度与物理规则成为新变量;
- 范式融合:传统计算机视觉与具身智能、生成式AI、计算生物学等领域交叉日益紧密;
- 教育普惠:技术门槛下降(如模型蒸馏、稀疏计算)使更多高校学生具备冲击顶会条件。
PhysInOne数据集发布、TRELLIS.2的秒级生成能力、本科生用老旧GPU实现突破——这些事件看似分散,实则共同指向同一结论:计算机视觉正在从‘看懂图像’迈向‘理解世界’,而这场变革的 protagonista(主角),正从少数顶尖实验室扩展至更广泛的青年研究者群体中。
正如一位与会学者所言:‘当一位本科生能用十年前的显卡做出被全球关注的工作时,我们才真正理解——技术民主化的价值,不在于让更多人进入赛场,而在于让每个身处其中的人,都能发出自己的声音。’