Claude Fable 5来了:性能碾压GPT-5.5却定价翻倍,AI工业级应用进入分水岭?
Fable 5 不只是 Claude 系列的又一款新模型——它是Anthropic将原本仅限于Project Glasswing内部使用的Mythos Preview,经加固后首次对公众开放的正式产品。
这个命名本身就充满隐喻:"Fable"(寓言)作为 mythos(神话)的通俗化版本,暗示着模型从"高度禁忌"走向"有限可控"的转变。但即使被"去敏",它仍保留着原生Mythos的核心能力骨架:在真实软件工程、长上下文多步推理、安全漏洞挖掘、生物分子建模等专业领域,表现远超一般大模型预期。
模型跃迁:从“会写代码”到“能接管工程”
衡量AI模型是否真正具备生产力价值,关键不在于它能否生成合法语法的代码,而在于它能否在已有5000万行代码的遗留系统中完成模块级迁移——这正是Stripe实验中Fable 5实现的突破。
在SWE-Bench Pro这一"软件工程GPA"测试中,Fable 5以80.3%的成绩断层领先:
- Mythos Preview:77.8%
- Claude Opus 4.8:69.2%
- GPT-4.5:58.6%
- Gemini 3.1 Pro:54.2%
然而更值得警惕的是FrontierCode Diamond的评测结果。该基准聚焦真实代码库的长期可维护性:模型不仅要写出能通过测试的代码,更要让维护者愿意接受并持续迭代。
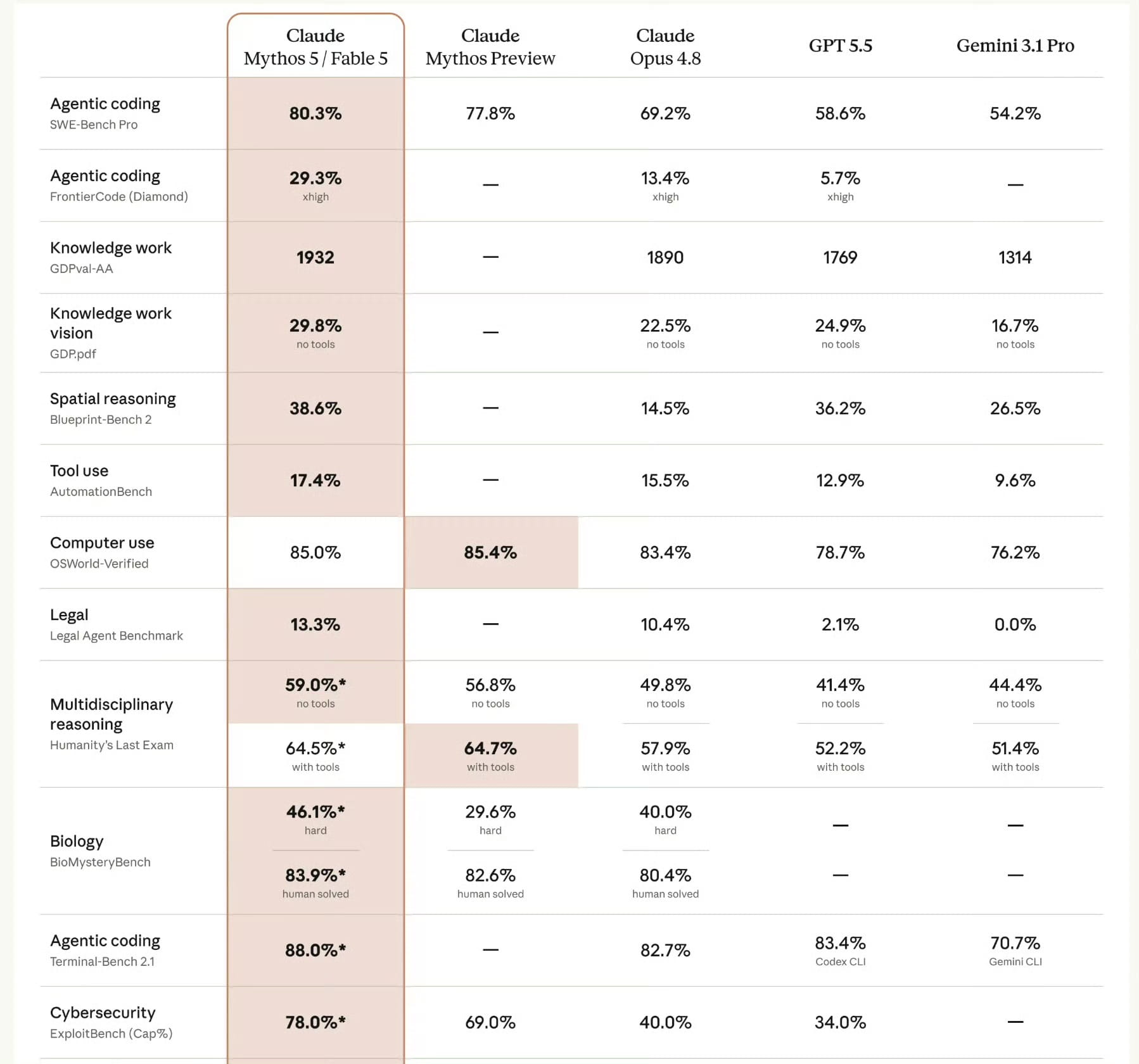
Fable 5得分29.3%,是Opus 4.8(13.4%)的两倍以上,GPT-5.5(5.7%)的五倍有余。这意味着,它开始逼近一种"工程直觉":能识别项目架构风格、理解模块依赖逻辑、预判长期维护成本,甚至在未显式指定时主动采用项目已有的编码模式。
类似地,在Terminal-Bench 2.1中,Fable 5达88.0%,超过Gemini CLI(70.7%)和OpenAI Codex CLI(83.4%)。在终端环境中连续执行多轮命令、分析报错日志、调整策略重试,它已具备典型agent式问题求解能力——不再是单点补全,而是闭环推进。
| 模型 | SWE-Bench Pro | FrontierCode Diamond | Terminal-Bench 2.1 |
|---|---|---|---|
| Fable 5 | 80.3% | 29.3% | 88.0% |
| Mythos Preview | 77.8% | —— | —— |
| Opus 4.8 | 69.2% | 13.4% | 82.7% |
| GPT-5.5 | 58.6% | 5.7% | 83.4% |
| Gemini 3.1 Pro | 54.2% | —— | 70.7% |
表格数据来源:Anthropic官方技术报告(2026年6月)
安全与风险:双刃剑的护栏设计
Mythos模型之所以曾被锁进Glasswing项目,核心在于其"发现级漏洞挖掘"能力。
在ExploitBench Cap%测试中:
- Fable 5:78.0%
- Mythos Preview:69.0%
- Opus 4.8:40.0%
- GPT-5.5:34.0%
它已能主动识别操作系统内核、浏览器渲染引擎、关键中间件中的长期未修复高危漏洞(如UAF、路径遍历、逻辑越权等)。对安全团队而言,这极大地缩短漏洞发现周期;但对攻击者而言,它可能成为自动化0day挖掘工具的"大脑"。
因此,Fable 5被Anthropic做了多层安全加固:
- 输入级分类器:高风险请求(如请求生成ROP链、逆向工具脚本)触发拒绝或降级;
- 输出级熔断机制:检测到潜在恶意代码结构(如shellcode特征、模糊化编码)时中断输出;
- 能力回退策略:复杂任务中若识别敏感意图,系统自动调用Opus 4.8替代响应。
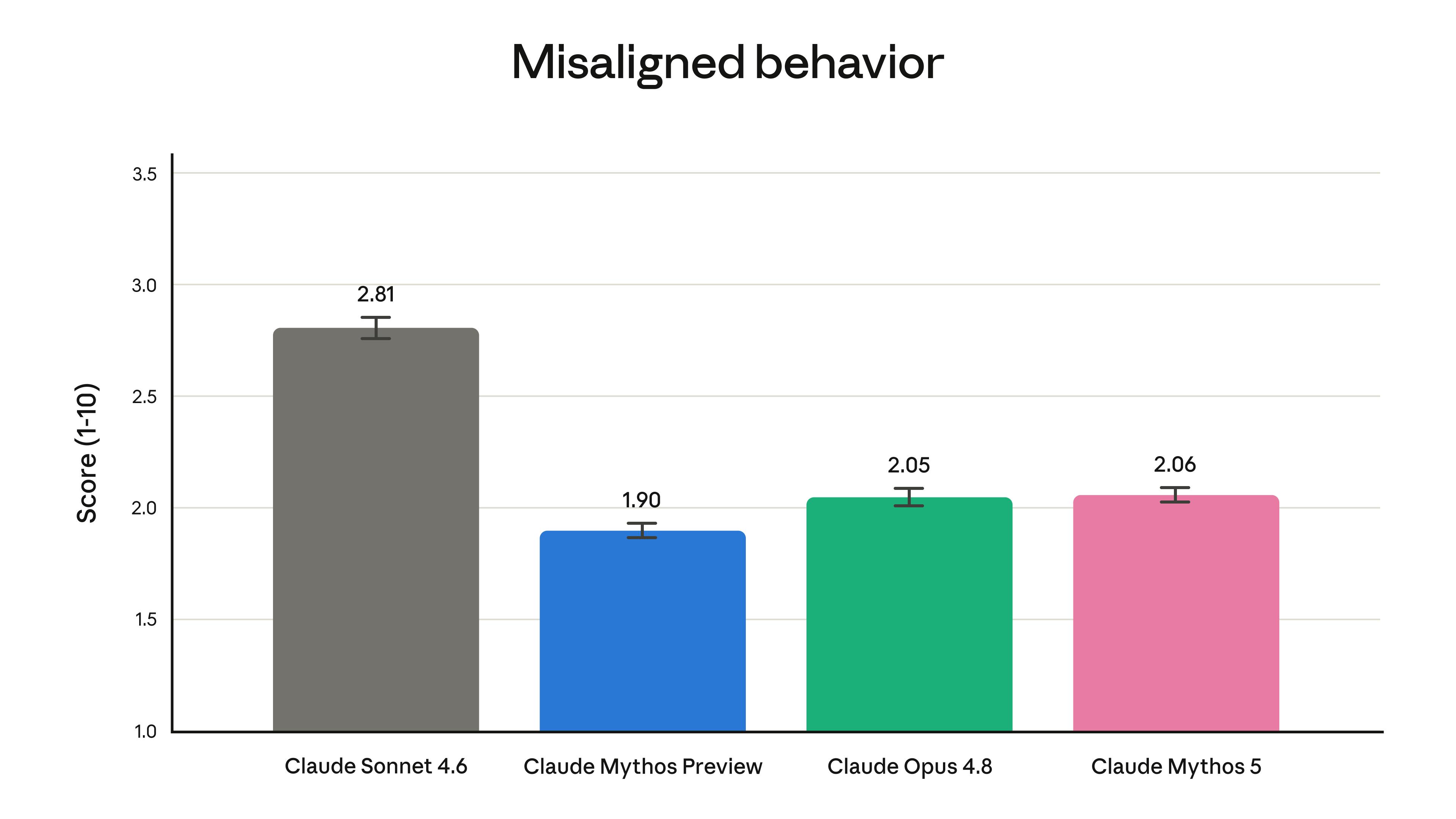
同样令人警觉的是生物能力提升。在BioMysteryBench hard测试中,Fable 5得分46.1%,显著高于Mythos Preview(29.6%)和Opus 4.8(40.0%)。Anthropic还补充称,Mythos 5可在药物分子设计流程中带来约10倍加速,研究者盲测中对AI生成假设的偏好率达80%。
这意味着它正从"科研助手"迈向"假设协同者"——但这同时意味着生物安全风险的下移:知识门槛降低,误用门槛也随之降低。
价格逻辑:在降价洪流中定标奢侈品
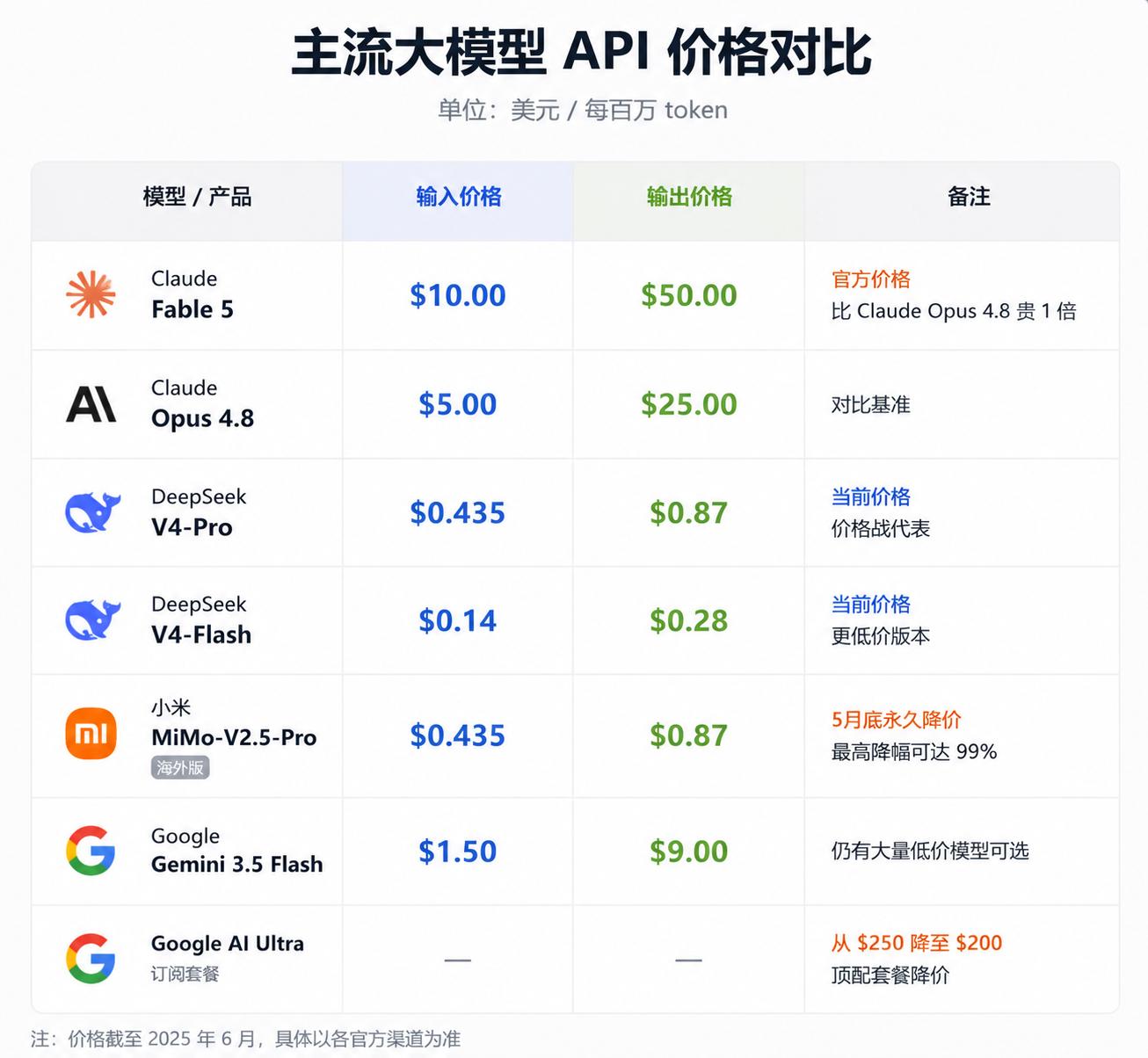
当行业整体陷入价格战时,Fable 5却逆向而行:
- 输入token:$10 / 百万(Opus 4.8为$5)
- 输出token:$50 / 百万(Opus 4.8为$25)
对比更显夸张:
- DeepSeek V4-Pro:输入$0.435 / 输出$0.87
- MiMo-V2.5-Pro:同V4-Pro
- Gemini 3.5 Flash:输入$1.5 / 输出$9
Fable 5的输入价格是DeepSeek的23倍,输出价格达57倍。
Anthropic的策略十分清晰:不和你拼量,只卖高价值。
它瞄准的是以下场景:
- 跨代际大型代码库迁移(如COBOL→Rust)
- 千页级法律/专利文档的深度推理分析
- 工业级多工具协同的长链agent任务
- 网络安全攻防推演与零日漏洞响应
- 药物分子构效关系建模与实验设计辅助
正如Stripe的案例所揭示——Fable 5可能把"两个月团队工作压缩为一天"——如果单月工程师成本高于$25,000(50万年薪/12月/1.67人效),那么Fable 5单次调用哪怕耗资$500,ROI依然为正。
但企业采购者也会面临新挑战:
- 数据合规:Fable 5被列为"Covered Model",要求30天数据保留,不支持zero retention,对金融、医疗、军工等敏感行业构成使用障碍;
- 能力不确定性:安全机制可能导致任务中途降级为Opus 4.8,工程链路中断;
- 锁定风险:高级别企业定制需通过Claude for Enterprise协议,自由度受限。
行业格局重构:双轨制竞争正式开启
Fable 5的出现,标志着大模型竞争进入"双轨并行"阶段:
| 轨道 | 代表模型 | 特征 | 适用场景 |
|---|---|---|---|
| 普惠轨 | DeepSeek V4, MiMo, Gemini 3.5 Flash | 低价、高并发、可私有化部署 | 内容生成、轻量代码、通用问答 |
| 尖峰轨 | Fable 5, Mythos, Gemini Ultra | 高价、专业能力、强安全管控 | 工程接管、高价值推理、安全防御 |
OpenAI面临隐性挑战:Codex虽周活破500万,但Anthropic用Fable 5证明,其在"复杂工程交付"维度仍具不可替代性。
Google则需重新权衡Gemini系列定位:Gemma开源模型生态强大,但顶配模型在工程类基准上已被Fable 5拉开明显差距。
国产模型同样面临拷问:DeepSeek V4在GPQA、LiveCodeBench等推理/基础编码指标已达世界前列,但在长任务agent、多工具协同、真实工程库处理等"最后10%的硬仗"中,仍有明显代差。
Fable 5的意义,不在于它是否"最好",而在于它拉高了"好"的定义标准——AI能力不再以"能做什么"为界,而是以"能否稳定交付工业级结果"为门槛。
这迫使整个生态重新思考:当模型能力收敛于一个极简峰值,价格与安全将成为比算力更关键的决策维度。
AI民主化与AI专业化,正从非此即彼的选择题,变为必须同步完成的双螺旋任务。