模型参数破万亿,数据合规成瓶颈:AI时代的“脏数据”危机
算力狂飙背后的隐忧:当大模型遇到“数据荒”
当我们沉浸在ChatGPT、Claude乃至Sora带来的技术震撼中时,一个常被忽视却致命的现实摆在面前:我们的数据准备好了吗?
当前,AI行业的竞争焦点似乎完全集中在算力规模和模型参数上。千亿、万亿参数的模型如雨后春笋般涌现,硬件迭代的速度令人目不暇接。然而,支撑这些超级大脑运转的“燃料”——数据,却常常处于一种混乱、低质甚至违规的状态。
许多企业盲目追求模型架构的创新,却在数据源头忽略了最基本的清洗与合规性审查。那些从互联网海量爬取的杂乱文本、版权归属模糊的图片、以及格式破碎的PDF文档,构成了大模型训练的“原材料”。这种“Garbage in, garbage out”(垃圾进,垃圾出)的现象在深度学习时代被指数级放大。如果输入端的数据存在噪声、偏见或法律风险,无论底层算力多么强大,最终输出的结果不仅价值有限,更可能引发严重的合规危机。

中国大模型产业的数据三重困境
在中国大模型快速发展的背景下,数据问题不仅仅是技术问题,更是合规与效率的双重挑战。具体而言,行业主要面临三大核心痛点。
1. 合规数据的高墙
数据合规是AI发展的底线。目前,公开网络数据的版权界定依然模糊,直接使用存在极高的法律风险。同时,开源数据集往往同质化严重,缺乏针对特定行业垂直领域的深度数据。对于医疗、金融、法律等专业领域,高质量的专业数据稀缺且分散,如何获取既合法又具备高信息密度的数据,成为企业的一大难题。
2. 数据质量的参差不齐
即便获得了数据,其质量也令人担忧。网页文本中充斥着广告、重复内容和无关噪音;多模态数据的标注往往粗糙且不一致;特别是PDF等复杂格式,传统的提取方式极易造成信息丢失或结构错乱。这些低质数据直接导致模型训练效果不佳,出现“幻觉”现象频发。
3. 处理效率低下
从原始数据到可训练数据集,中间需要经历清洗、去重、结构化、标注等一系列复杂流程。缺乏自动化工具导致大量依赖人工介入,耗时耗力。许多团队花费数月时间整理数据,却仍难以保证数据的一致性和准确性,严重拖慢了模型迭代的速度。
数据治理的新范式:从“粗加工”到“精智治”
要解决上述问题,必须建立一套系统化、智能化的数据治理体系。这不仅仅是简单的去噪,而是对数据进行深度挖掘和价值重塑。
1. 构建合规基石
数据来源的清晰性和版权授权的完整性是首要任务。基于上海数据交易所、深圳数据交易所等权威机构的认证,建立全链路合规保障机制,确保每一字节的数据都“来路正、去路清”。这不仅是合规要求,更是企业长期可持续发展的基石。
2. 精细化处理流程
高效的数据处理需要技术与人工的深度融合。标准的处理流程包括:
- 清洗解析: 利用NLP技术精准抽取有效信息和关键词,去除无关噪声。
- 智能去重: 结合专家规则与算法,实现双重去重,确保数据的唯一性。
- 结构化重构: 通过机器学习将非结构化数据转化为机器可理解的结构化格式。
- 知识关联: 利用知识图谱技术建立数据间的深层关联,提升数据的语义价值。
- 交叉验证: 引入人工专家进行针对性补充与校验,确保数据的绝对准确。
这种“技术+人工”的双重校验机制,能够显著提升数据集的质量和可用性,为模型训练提供高质量的“燃料”。

3. 攻克PDF解析难题
在大模型训练语料中,PDF格式的论文、报告和书籍占据重要比例。传统的OCR识别难以处理复杂的排版和图表。先进的PDF智能提取方案能够原生识别字符、单词、字体、图像及其位置,输出结构化的JSON或XML数据。同时,基于Document AI的智能分类能力,可以按照自然阅读顺序区分标题、表格、页眉页脚和段落,大幅提升信息提取的准确度。
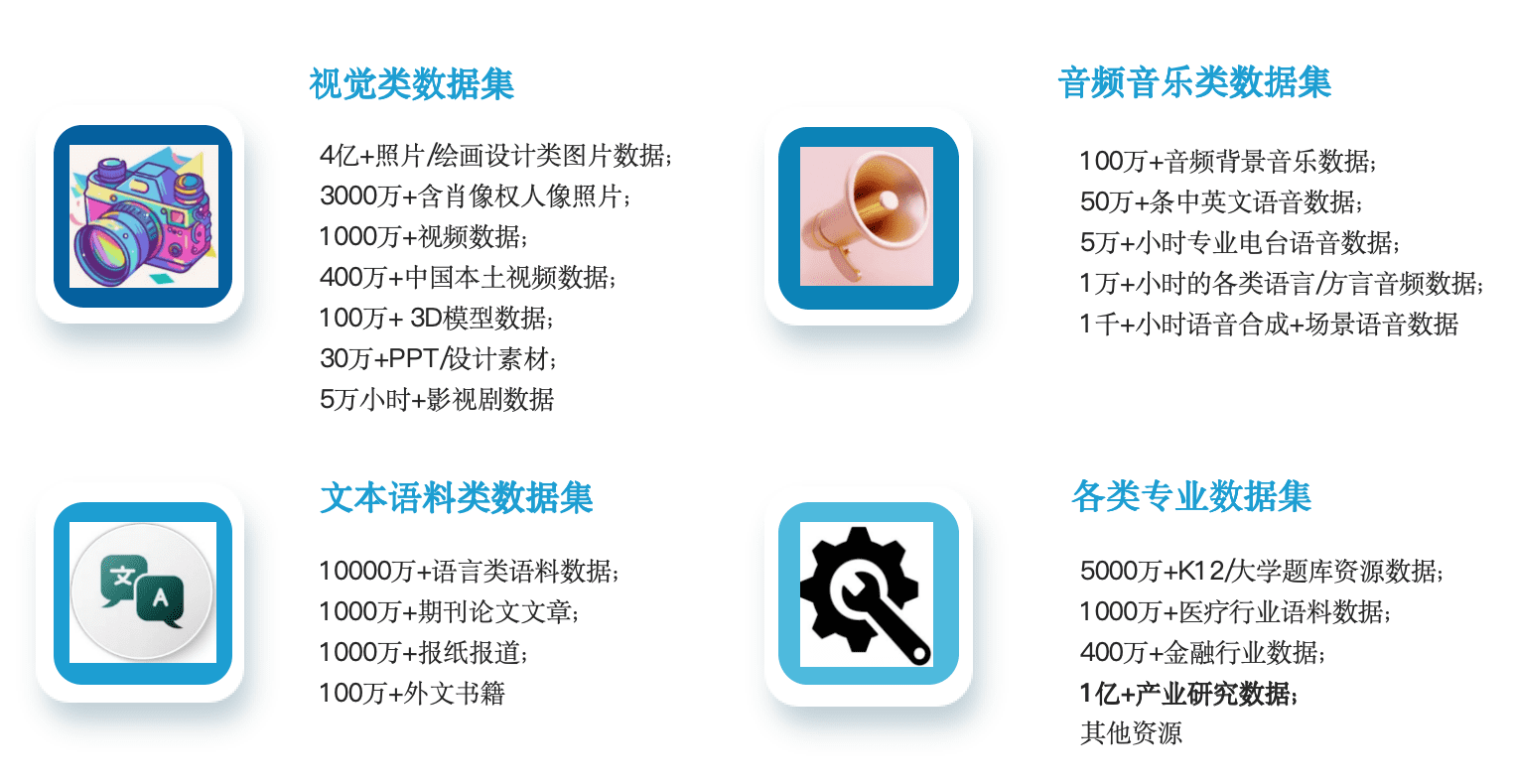
行业验证:头部企业的选择逻辑
为何智谱、商汤、字节跳动等头部AI企业纷纷选择专业的数据服务提供商?
在严格的评估体系中,通用语料的性价比、数据形式的多样性、以及合规可靠性成为关键决策因素。头部客户深知,数据成本虽在模型总成本中占比不高,但其对模型最终效果的边际贡献巨大。
亿欧数据通过打造“语料超级工厂”,联合上海库帕思等生态伙伴,构建了“1+N”的语料运营格局。通过扮演数据标注施工队、语料处理总包商和语料专业开发商三重角色,致力于实现大模型语料产业的提质、增效、降本。这种生态化的合作模式,不仅解决了数据供给问题,更通过专业化运营提升了数据价值。

从“拥有数据”到“驾驭数据”
AI工具的进化仍在继续,明年或许会有更强大的模型问世。但如果忽视数据合规与质量,这些进步将与使用者无关。正如使用最新款智能手机却只用来打电话,既浪费功能,又潜在风险。
数据已不再是技术的附属品,而是AI时代的核心生产资料。合规、高质量、大规模的数据,构成了AI企业真正的护城河。
面对这一现状,企业应立即行动:
- 全面审查数据合规性: 确保所有训练数据拥有合法授权,规避法律风险。
- 提升数据处理效率: 引入自动化工具,缩短从原始数据到训练集的生产周期。
- 满足定制化需求: 针对垂直领域特点,生产定制化的高质量训练数据集。
在AI的下半场竞争中,胜负手不再仅仅是算力的堆砌,更是对数据这一核心生产资料的精细化驾驭能力。只有解决了“脏数据”和“数据荒”的问题,AI的潜力才能真正被释放。