芯片型号跳跃背后的行业变局
当华为昇腾芯片从910C迅速跃升至950时,外界往往只关注序号的变化,却忽略了这背后所折射出的AI产业深刻变革。从2019年的910A到2023年的910B,四年时间跨度反映了美国制裁下的艰难突围;而2025年910C到950的跨越,则标志着中国AI算力从"追赶"走向"重构"的关键转折。
这种型号命名的逻辑断裂并非技术断层,而是市场需求发生根本性转变的结果。当DeepSeek R1横空出世,彻底改变了大模型开发的商业模式,使得单纯追求训练算力的竞赛变得不再具有商业价值。企业不再盲目投入数亿元训练不如DeepSeek的模型,而是转向追求更高效的推理部署和更低的运营成本。

在这一背景下,昇腾芯片的战略定位发生了根本性调整。910B、910C、910D这些原本定位为全能型训练芯片的产品,实际上是920、930、940的变体,它们的存在更多是为了应对过渡期的特殊需求。随着推理成为主流,华为顺势推出了真正面向推理场景的950系列,让芯片型号回归到符合技术演进逻辑的连续编号体系。
推理时代的芯片架构创新
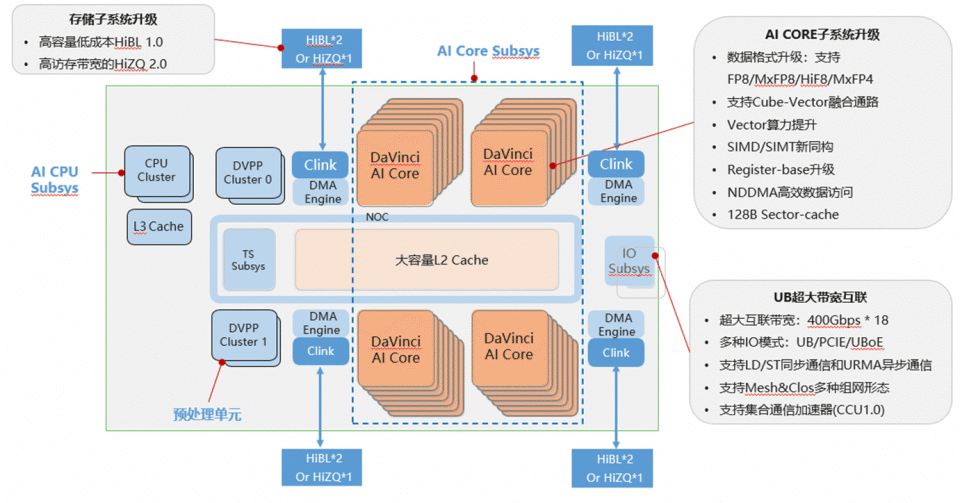
昇腾950的问世标志着AI芯片设计进入了一个全新的时代。与以往追求单一高性能通用芯片不同,950系列采用了PD分离(Prefill-Decode Separation)架构设计,这是针对推理场景特点做出的精准优化。
推理过程被拆解为两个截然不同的阶段:预填充阶段需要处理大量输入数据和上下文,对算力要求极高但显存压力较小;而解码阶段则需要频繁读取显存中的KV Cache数据,对显存带宽和容量提出极高要求。这种技术特性决定了单一芯片难以同时优化两个阶段。

昇腾950PR专攻预填充阶段,提供1.56-2PFLOPS的FP4算力,配备128-144GB自研HiBL1.0内存,内存带宽达到1.6TB/s。而950DT则专注于解码环节,虽然算力降至2PFLOPS,但通过HiZQ2.0内存将带宽提升至4.0TB/s,完美匹配解码阶段的高频数据读取需求。
这种分工设计并非华为独有,英伟达Rubin架构也采用了类似思路。但在内存成本控制上,华为展现了更大的灵活性——在预填充芯片中采用相对便宜的消费级内存,而在解码芯片中使用高带宽内存,有效降低了整体系统成本。
系统级突围应对单卡差距
单从参数对比来看,昇腾950与英伟达Rubin R200确实存在代差。R200的算力是950DT的16倍,HBM4带宽更是达到HiZQ2.0的5倍。然而,在AI推理领域,单卡性能并非决定性的竞争要素。
华为选择了一条不同的技术路线:通过超节点策略构建集群优势。节点规模从384提升至8192,意味着单个集群可容纳65536颗950芯片协同工作。这种"以量补质"的策略,使得系统在整体吞吐能力上能够与英伟达的GB200 NVL72形成有效竞争。
当然,这种策略也带来了新的挑战。超大规模集群需要解决散热、功耗、网络互联等一系列工程难题。占地面积的扩大和能耗的增加,使得数据中心建设成本显著上升。但这正是国产芯片必须面对的现实——在技术追赶过程中,需要在性能、成本、功耗之间做出艰难的平衡。
从实际应用效果看,这种集群化方案在特定场景下已经展现出竞争力。特别是在推理需求量大、对延迟不极端敏感的企业级应用中,昇腾950集群能够提供可接受的推理性能,同时大幅降低硬件采购成本。
DeepSeek引领的生态重构
DeepSeek V4明确表示支持昇腾950,这不仅是技术兼容的体现,更是中国AI产业链自主可控的重要里程碑。当一家头部大模型公司选择完全拥抱国产算力时,意味着整个生态的转折点已经到来。
这种选择的背后有着深刻的战略考量。过去,中国AI企业不得不依赖英伟达芯片,这不仅带来供应链风险,更受制于CUDA生态的锁定。而通过北京大学TileLang语言的开发,深度求索成功绕开了CUDA绑定,实现了对国产芯片内核的深度优化。

这一突破具有多重意义。首先,它证明了国产芯片在软件层面的可操作性,打破了"国产芯片只能用"到"国产芯片好用"的认知壁垒。其次,它建立了完整的模型训练、推理部署到芯片制造的闭环,使得中国AI产业不再受制于外部技术封锁。
更重要的是,这种合作模式为行业树立了新的标准。当国产芯片与国产大模型深度绑定后,双方可以共同优化,形成"1+1>2"的协同效应。这种生态构建的速度和深度,是单纯依赖硬件参数无法比拟的。
时间维度下的技术成熟
任何技术路线的成熟都需要时间的沉淀。昇腾950虽然在参数上仍有差距,但中国AI产业已经不再被"卡脖子"的焦虑所困扰。有了DeepSeek这样的一流模型,有了昇腾这样持续迭代的芯片,剩下的核心问题是如何加速生态建设。
开发者工具链的完善、框架适配的优化、应用案例的积累,这些都是需要时间投入的工作。但与过去不同,现在这些工作不再是被迫的生存需求,而是主动的技术升级。企业可以从容地选择国产芯片,因为它们已经证明了自己的可用性和可靠性。
从产业角度看,这种转变标志着中国AI算力从"可用"走向"好用"的关键跨越。虽然单卡性能仍有提升空间,但系统级的整体解决方案已经具备了与国际主流产品竞争的能力。更重要的是,这种竞争力建立在自主可控的基础之上,不受外部制裁影响。
未来的竞争将不再是单纯的性能比拼,而是生态完整性和持续迭代能力的较量。中国AI产业已经迈出了最关键的一步,剩下的就是沿着既定的技术路线稳步前行。在这个充满不确定性的时代,确定性将成为最大的竞争优势。
产业闭环的战略价值
昇腾950与DeepSeek V4的结合,构建了一个相对完整的AI技术闭环。这个闭环的价值不能简单用单卡算力来衡量,它的意义在于打破了技术依赖的恶性循环。
从芯片设计、制造、封装,到操作系统、编译器、框架,再到应用模型、推理部署,每个环节都实现了自主可控。这种全链路的国产化,使得整个产业在面对外部环境变化时具有极强的韧性。即使某个环节出现波动,其他环节依然能够维持系统运转。
这种闭环生态的构建,为中国AI产业赢得了宝贵的战略时间。不必再受制于外部技术封锁,企业可以专注于技术创新和商业模式探索,而不是将大量资源投入到供应链安全的被动防御中。
当国产芯片与国产大模型形成良性互动时,创新的正反馈循环就开始运转。芯片厂商根据实际应用场景优化硬件设计,模型厂商根据硬件特性改进算法结构,双方共同推动技术进步。这种协同效应,是单纯的技术引进无法实现的。
从长远来看,这种自主可控的产业链优势,将成为中国AI产业在国际竞争中最核心的竞争力。当全球AI技术进入深水区,生态完整性和持续迭代能力将比单一参数更重要。中国AI产业已经找到了属于自己的发展路径,这条路径虽然充满挑战,但方向明确且充满希望。