
当Sam Altman那句“如同看到原子弹爆炸般眩晕瘫坐”的著名梗被反复调侃时,恐怕很少有人预料到,下一次让全球AI社区集体陷入类似震撼的,会是一款图像生成模型。GPT-Image 2的发布,并非一次简单的版本迭代,而是OpenAI对计算机视觉领域发出的一次代际跃迁宣言。其发布页首句“Images are a language, not decoration.”(图像是语言,而非装饰品)清晰地表明,图像生成正在被重新定义——从视觉装饰的附属品,升维为承载信息、逻辑与意图的独立表达体系。
过去一年,行业对AI绘图的评价仍主要停留在“像不像真人”、“是否符合审美”的层面。而GPT-Image 2的出现,彻底扭转了这一评价坐标系。它将竞争的焦点从“审美模仿”拉到了“逻辑正确”的智力层面。这意味着,模型优劣的评判标准,不再仅仅是输出结果的视觉保真度,更是其理解并执行复杂、多步骤指令的逻辑连贯性与准确性。

这种转变的核心驱动力,在于模型架构中引入的“思考模式”。传统图像生成模型的工作流程,可以粗略理解为根据提示词在潜在空间中寻找最匹配的像素分布并进行去噪合成。而GPT-Image 2的工作机制发生了根本性变化:在动笔生成第一个像素之前,模型会先在后台进行一次隐式的“思维建模”。这个过程类似于大语言模型进行推理时的思维链,只不过其输出目标不是文本,而是符合逻辑约束的视觉结构。
一个来自社区的实测案例极具说服力:模型生成的“雷军直播跑步”画面中,不仅人物面部特征高度还原,画面UI元素更是包含了“直播目标1313km”、“已跑425.7km”、“剩余887.3km”以及“当前海拔3658m”等数据。这些数字并非随机填充,它们之间存在着严密的数学关系(1313 - 425.7 ≈ 887.3),而3658米的海拔高度,恰好对应从北京进入藏区的典型海拔。
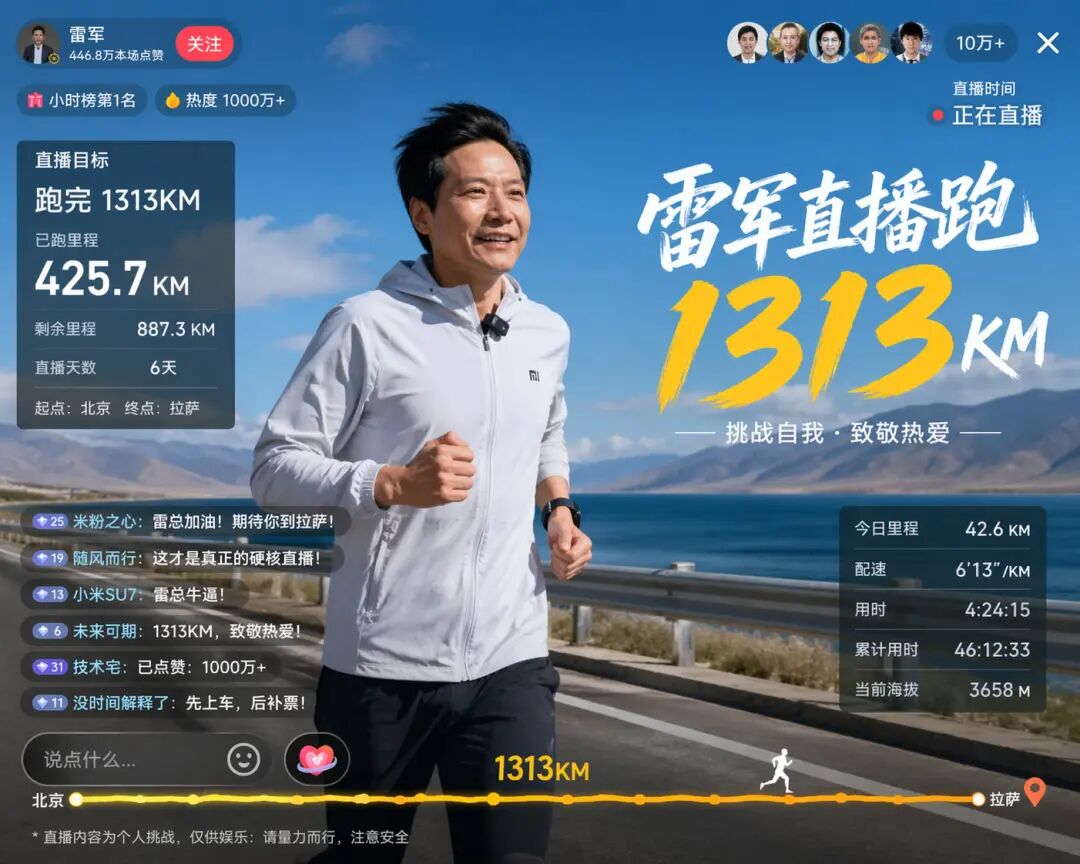
对于人类而言,完成这样的任务需要理解“跑步直播”的场景设定、掌握基本的算术减法、并具备一定的地理常识。而对于一个图像模型而言,这意味着它必须在像素合成阶段之前,就已完成对这些抽象概念及其相互关系的解析与整合。这不再是简单的模式匹配或风格迁移,而是具备了初步的“场景理解”与“逻辑推理”能力。这种能力,正是GPT-Image 2从“玩具”迈向“生产力工具”的关键分水岭。
当图像生成模型具备了逻辑思考的雏形,其应用场景便发生了质变。它不再局限于生成头像、艺术画或概念图,而是能够直接切入商业设计的核心流程。以海报设计为例,传统的流程涉及需求沟通、草图构思、多次修改与最终定稿,周期长、沟通成本高,且对设计师的个人审美与经验依赖极大。

GPT-Image 2展现出的能力,在于它能同时处理构图、光影、色彩搭配、品牌元素植入以及信息层级排版等多重任务。用户可以通过自然语言描述需求,例如“设计一张科技感十足的发布会海报,主色调为深蓝与荧光绿,突出产品‘极速’的特性,留出标题和日期位置”。模型不仅能生成符合要求的视觉稿,更能保证品牌调性的一致性与视觉元素之间的逻辑和谐。更重要的是,其试错成本极低。即使生成结果不完全满意,用户可以通过多轮对话进行精细化调整——“Logo再放大10%”、“背景增加一些流动的线条元素”、“把主角放在黄金分割点”——这些在传统设计中需要反复沟通、耗费数小时的修改,现在可能只需几分钟和几美分的计算成本。
开发者文档中频繁出现的“model: ‘gpt-5.4’”引用,暗示了GPT-Image 2与下一代大语言模型深度集成的战略定位。它很可能不是孤立的视觉模型,而是作为多模态AI系统的“视觉终端”存在。通过新的Responses API,生图过程被无缝嵌入到与大模型的对话流中,使得“用语言描述并迭代视觉内容”变得像聊天一样自然。这种交互模式,极大地降低了专业设计工具的使用门槛,让非专业用户也能高效地产出高质量视觉内容。
对于中文世界用户而言,GPT-Image 2带来的惊喜尤为显著。长期以来,中文文本渲染是AI生图领域的顽疾,生成的汉字常常是笔画错乱、结构扭曲的“伪文字”。而GPT-Image 2在这一方面的表现堪称飞跃。从社区分享的生成图中可以看到,无论是模拟罗永浩与王自如辩论场景中的对话字幕,还是“马斯克直播带货老干妈”的广告牌文字,亦或是手写药方上的潦草笔迹,其文字的清晰度、字体的一致性与排版的合理性都达到了前所未有的高度。
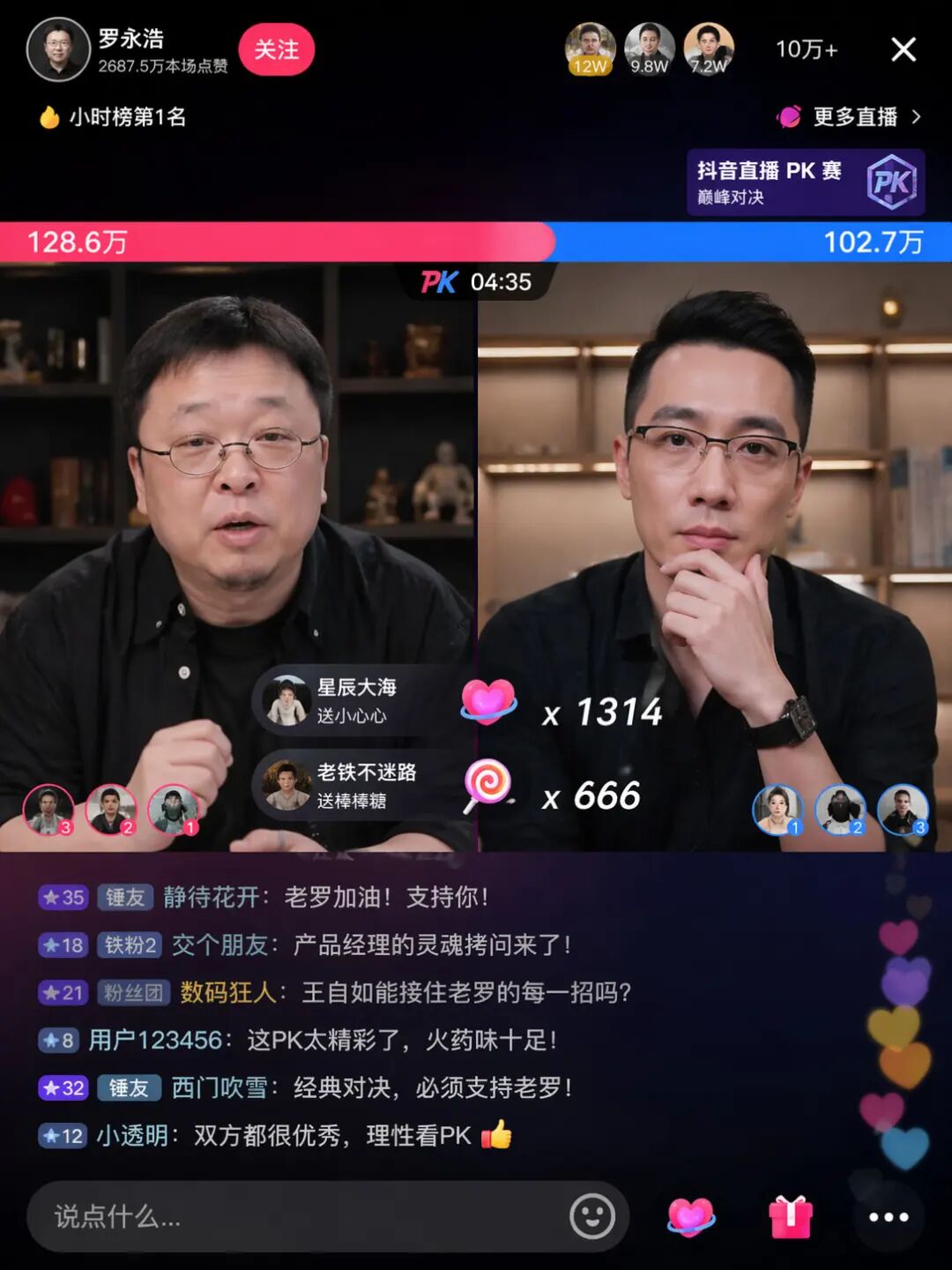

这显然得益于OpenAI在训练数据中大规模引入了高质量的中文图文语料,并进行了针对性的优化。对比测试清晰地展示了这种进步:前代模型生成的菜谱,文字部分几乎无法辨认;而GPT-Image 2生成的相同主题图片,不仅步骤文字清晰可读,图文对应关系也相当准确。

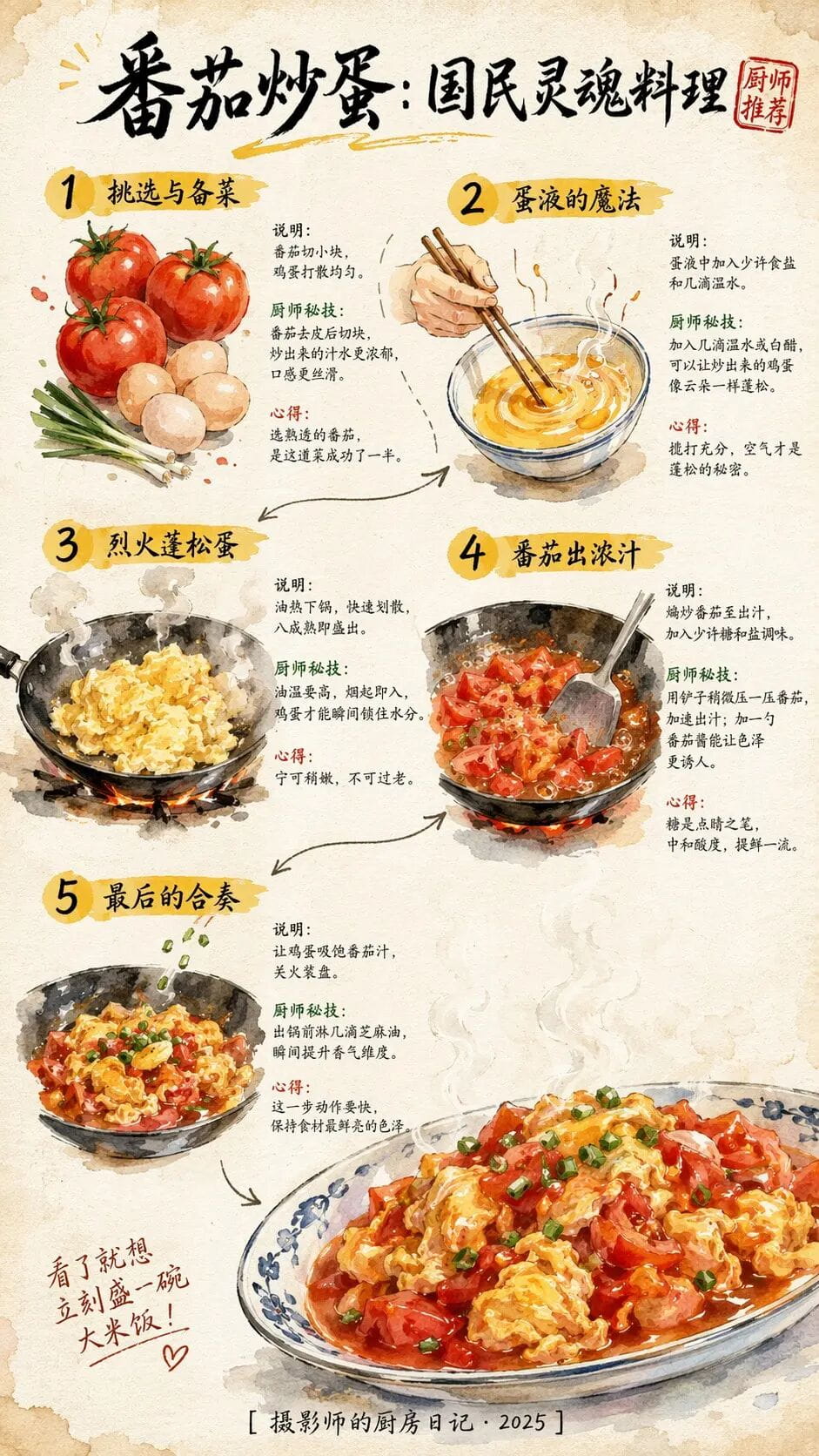
然而,必须清醒认识到,这种“完美”可能更多是统计意义上的逼近,而非真正的“理解”。图像模型的底层逻辑依然是像素概率预测。当它生成“蒙牛”和“王老吉”商标时,它并非理解了这两个品牌字符的语义,而是从海量训练数据中记住了这两个特定像素组合的高频出现模式。因此,在细节处,尤其是非常用字体、极小字号或复杂背景下的文字,模型仍可能产生模糊或错误的渲染,暴露出其作为像素生成器而非字符渲染器的本质局限。

尽管存在局限,GPT-Image 2在绝大多数商业应用场景中展现的实用性已足够强大。它的出现,正在重新划分设计工作的价值链条。那些高度依赖标准化、模板化、重复性视觉内容生产的岗位(如基础Banner设计、社交媒体配图、简单信息图表制作)将首当其冲受到冲击。AI能以近乎零边际成本的方式,批量生成大量符合要求的备选方案,这在效率上是人类设计师无法比拟的。
与此同时,GPT-Image 2也暴露了当前技术范式下的一些固有缺陷。其“思考模式”在应对极度复杂、逻辑嵌套或完全虚构的指令时,可能会陷入长时间的推理循环甚至失败。此外,生成高分辨率图像(如2K、4K)所带来的巨大token消耗和计算延迟,也是实际应用中需要权衡的成本问题。用户必须在输出质量与响应速度之间找到适合自己的平衡点。
更深远的影响在于伦理与社会层面。GPT-Image 2在人物生成上的高保真度,使得制作以假乱真的“深度伪造”内容变得前所未有的容易。当任何人的面孔都可以被轻易置入任何场景,且几乎毫无破绽时,社会赖以运行的视觉信任基础将受到严峻挑战。这对新闻真实性、司法证据、个人隐私保护等领域提出了亟待解决的新问题。技术开发者、平台方、立法机构与社会公众需要共同构建新的鉴别标准、技术水印与法律框架,以应对这场即将到来的信任危机。
对于设计行业从业者而言,焦虑与机遇并存。单纯掌握软件操作技能和基础美学原则的设计师,其竞争力正在被快速稀释。未来的设计价值将更多地向上游迁移:定义问题、制定策略、把握品牌内核、进行创造性构思,以及驾驭AI工具实现复杂视觉叙事的能力。设计师的角色可能从“执行者”转变为“导演”或“策展人”——他们更需要的是深刻的洞察力、跨领域的知识储备、以及将抽象概念转化为精确AI指令的能力。
GPT-Image 2的发布,是一个清晰的信号:AI在视觉创作领域,正从辅助人类的“画笔”,进化为具备一定自主性的“合作者”。它迫使整个行业重新思考“设计”的本质——当构图、配色、排版这些执行层工作可以被自动化高效完成时,人类创造力的护城河究竟在哪里?答案或许在于对人性、文化、情感与复杂系统更深层次的理解与连接,在于提出那些AI尚未学会提出的、真正独特而深刻的问题。
视觉创作的“奇点”或许尚未完全到来,但通往那里的路径已经变得清晰可见。图像,作为一种语言,正在被AI以我们未曾预料的方式流利地“书写”出来。这场变革将不限于设计行业,它将重塑广告、媒体、教育、娱乐乃至所有依赖视觉传达的领域。拥抱变化、更新技能、并深入思考技术在人类创造性活动中应处的位置,是每个相关领域参与者当下的必修课。










