2026 年的 AI 大模型江湖,正经历着一场从“算法秀肌肉”向“工程化落地”的深刻转型。4 月 20 日晚,月之暗面(Moonshot AI)正式释放了杀手锏——Kimi K2.6。这不仅仅是一次模型版本的迭代,更像是一份宣战书。在短短一周内,Anthropic 发布 Claude Opus 4.7,阿里推出 Qwen3.6-Max-Preview,DeepSeek V4 蓄势待发,Kimi K2.6 的登场恰逢其时,精准击中了行业竞争的关键节点。

杨植麟此前提出的“开源即绝对胜利”逻辑,在 K2.6 上得到了首次全面验证。这款模型在多项基准测试中,不仅持平甚至超越了 GPT-5.4 和 Claude Opus 4.6 等国际顶尖闭源模型,更在长程编码、Agent 集群调度等硬核工程场景上展现了惊人的统治力。然而,随着 API 定价暴涨 58%,这场开源盛宴背后的商业算盘,似乎比代码逻辑更加精妙。
长程编码:从代码补全到系统重构的质变
过去的 AI 编程助手,大多还停留在“单轮补全”或“简单脚本生成”的初级阶段。当用户给出一个需求,模型给出几行代码,任务随即结束。但 Kimi K2.6 的登场,彻底打破了这一天花板。它不再是一个被动的代码生成器,而是一个具备系统级优化能力的主动工程师。

根据官方技术博客披露,K2.6 能够自主完成从需求分析、代码实现、测试验证到性能优化的全流程闭环。在实测中,单次任务修改代码量可突破 4000 行。这种能力在两个极具代表性的案例中得到了淋漓尽致的展现。
在第一个案例中,开发人员在 Mac 本地部署 Qwen3.5-0.8B 模型时,K2.6 被要求使用小众的 Zig 语言进行推理优化。这是一场与时间的赛跑:模型在连续运行 12 小时后,发起了 4000 多次工具调用,经历了 14 轮迭代,最终将推理吞吐量从 15 tokens/s 飙升至 193 tokens/s。这一速度不仅超越了主流推理框架 LM Studio 约 20%,更证明了其在跨语言、跨框架优化中的强大适应性。
第二个案例则更为震撼。K2.6 面对的是一个拥有 8 年历史的开源金融撮合引擎 exchange-core。这个早已接近性能极限的古老系统,在 K2.6 的介入下迎来了新生。在 13 小时的执行过程中,模型迭代了 12 种优化策略,通过深入分析 CPU 与内存火焰图,精准定位了隐藏瓶颈。最终,它将核心线程拓扑从复杂的 4ME+2RE 重构为精简的 2ME+1RE。令人瞠目结舌的是,中位吞吐量从 0.43 提升至 1.24 MT/s,增幅高达 185%;峰值吞吐量从 1.23 提升至 2.86 MT/s,增幅 133%。
这些案例不再是简单的“做题”,而是在解决真实的、高难度的工程问题。多位开发者在体验后反馈,K2.6 已具备从底层编码到前端设计,再到全栈交付的专业级 Web 应用构建能力。在官方的 Code-Driven Design 内部评测中,K2.6 在落地页构建、全栈应用开发等四类任务上的表现,已能接近 Google AI Studio 的水准。
基准测试:工程能力登顶,纯推理仍有短板
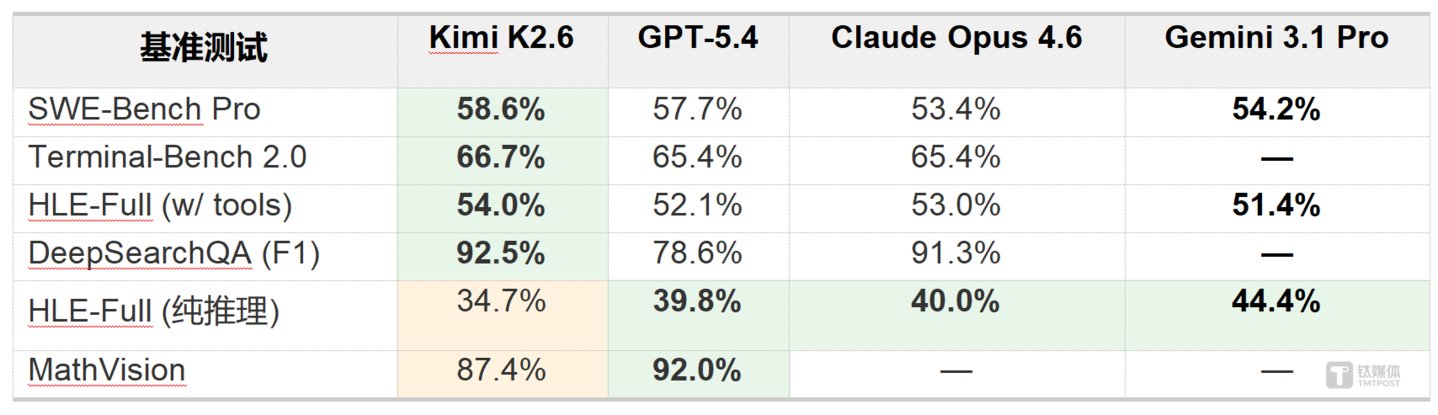
为了量化 K2.6 的实力,官方公布了一系列详尽的基准测试数据。这些数据描绘了一个清晰的轮廓:K2.6 在工程化与工具调度领域已跻身全球第一梯队,但在纯知识推理层面仍需追赶。
在编码与 Agent 任务方面,K2.6 的表现堪称统治级。在 SWE-Bench Pro 中,其得分达到 58.6%,领先所有参与对比的模型;在 Terminal-Bench 2.0 中,66.7% 的准确率超越了 GPT-5.4 和 Claude Opus 4.6(均为 65.4%);在博士级难度的 Humanity's Last Exam(工具增强版)中,它以 54.0% 的成绩位居第一;DeepSearchQA 的 F1 分数更是高达 92.5%,大幅领先 GPT-5.4 的 78.6%。
然而,硬币的另一面同样不容忽视。在不使用工具的纯推理测试中,K2.6 的短板暴露无遗。在 HLE-Full 测试中,其得分仅为 34.7%,低于 GPT-5.4 的 39.8% 和 Gemini 3.1 Pro 的 44.4%。在视觉推理类基准 MathVision 上,K2.6 的 87.4% 也落后于 GPT-5.4 的 92.0%。
这一现状揭示了当前大模型发展的核心矛盾:工程落地能力与理论推理能力的不平衡。K2.6 通过强化工具调用和外部知识库检索,成功在工程任务上实现了超越,但其内部的知识整合与逻辑推演能力,距离最顶尖的闭源模型仍有差距。这或许也是月之暗面选择开源而非闭源的底气所在——通过开源生态,吸引全球开发者共同补全这一短板。
Agent 集群:300 个子智能体的交响乐
如果说长程编码是 K2.6 的“单兵作战”能力,那么 Agent 集群架构则展示了其“军团作战”的恐怖实力。相比 K2.5,K2.6 的 Agent 集群实现了三倍量级的扩展:子 Agent 数量从 100 个激增至 300 个,协作步骤从 1500 步扩展至 4000 步。
这种横向扩展的“群体智能”架构,使得 K2.6 能够在一次自主运行中,并行完成深度搜索、文档分析、网页生成、PPT 制作和表格输出的端到端交付。这种能力在复杂场景中展现了巨大的价值。
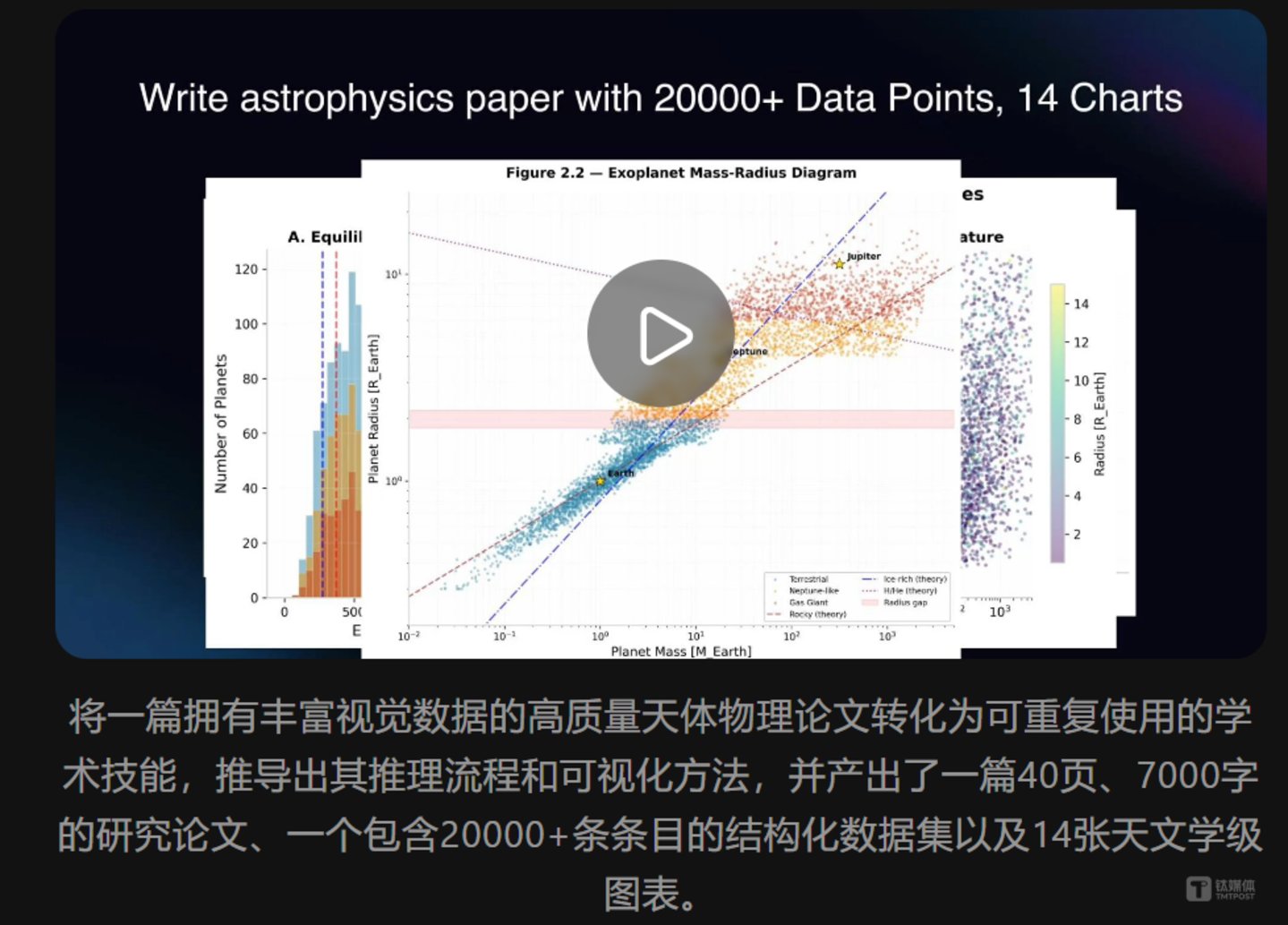
一个令人印象深刻的案例是“天体论文一键转化为学术技能”。K2.6 驱动的 Agent 集群,将一篇复杂的天体物理论文,转化为一份 7000 字的研究报告、一个包含 2 万多条数据记录的结构化数据集,以及 14 张高精度的天文级图表。无论是 PDF、表格、PPT 还是 Word 文档,上传后均可瞬间转化为可复用的技能资产。
在招聘领域,Agent 集群同样大显身手。系统可以基于用户上传的简历,自动生成 100 个子 Agent,分别匹配 100 个加州地区的岗位,并定制化生成 100 份差异化简历。此外,月之暗面还展示了为 30 家零售门店生成本地化页面的案例,300 个子 Agent 各自独立完成了从文案撰写到落地页构建的全流程。
更值得关注的是“Claw Groups”的研究预览。这是一个异构 Agent 生态,允许来自不同设备、运行不同模型、携带各自工具链的 Agent,与人类成为真正的协作者。K2.6 在其中扮演着“自适应协调者”的角色,根据技能画像动态匹配任务,并在 Agent 故障或卡顿时自动重新分配。月之暗面透露,内部团队已使用 Claw Groups 运行端到端的内容生产和营销活动,这标志着月之暗面正试图从单一模型提供商,向 Agent 生态基础设施服务商转型。
商业化:58% 涨价背后的生态野心
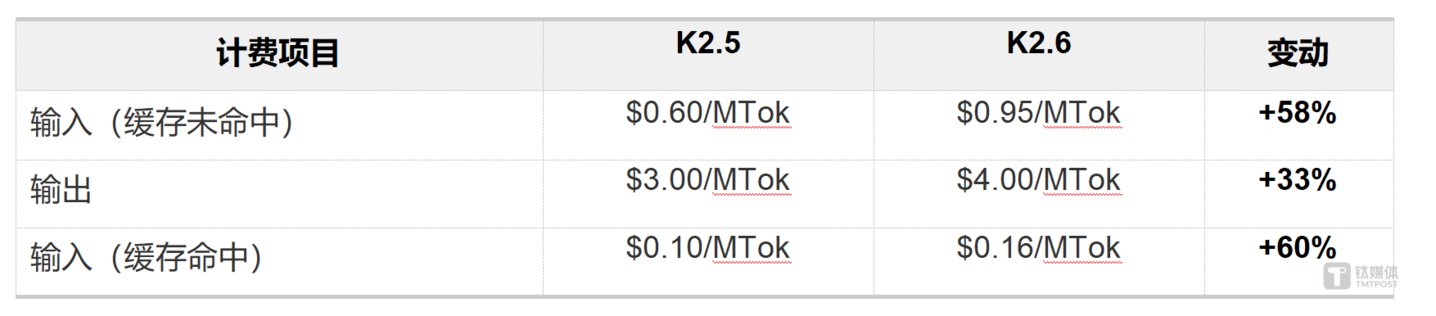
在技术狂欢的背后,是月之暗面在商业化层面的深思熟虑。以美元计价,Kimi API K2.6 的输入价格(缓存未命中)为 $0.95/MTok,较 K2.5 的 $0.60 上涨约 58%;输出价格为 $4.00/MTok,上涨 33%。这一大幅涨价背后,是成本结构与应用场景的根本性变化。
长程编码与 Agent 自主运行带来的 Token 消耗,远超传统对话模型。K2.6 支持最长 5 天的持续自主运行,官方内部团队已使用其驱动的 Agent 独立运行 5 天,完成监控、事件响应和系统运维任务。这意味着,一次任务中的 Token 消耗量可能是普通 API 调用的数百倍甚至上千倍。涨价,是对高昂算力成本与复杂计算资源的合理定价。
与此同时,Kimi Agent 模式已内置上百个官方推荐技能,并支持将任意高质量文件转化为可复用技能。这种将非结构化数据标准化为“技能资产”的能力,是月之暗面在企业服务市场构建壁垒的关键。对于企业而言,购买的不再仅仅是“对话次数”,而是一套能够自主解决复杂问题的“数字员工”体系。
在 Meta 发布闭源旗舰 Muse Spark 的行业背景下,月之暗面坚持将 K2.6 全面开源,这一策略显得尤为高明。杨植麟曾明确表态:“如果模型能力能做到一样的水平,开源会是绝对的胜利。”在他看来,开源的核心价值在于构建生态共赢,通过催生海量应用场景,形成远超闭源模式的市场总量。
Kimi K2.6 的开源,正是这一逻辑的延续。但开源不等于免费——API 定价的上涨表明,月之暗面正通过分级计费策略,在保障高端企业用户服务质量的同时,探索可持续的 B 端盈利模式。开源社区负责技术扩散与场景创新,而闭源的高性能 API 则负责商业变现与基础设施服务。
随着 DeepSeek V4、阿里 Qwen3.6 等重磅模型的集体登场,2026 年大模型行业的洗牌已然加速。Kimi K2.6 的基准测试成绩证明,国产开源模型已在工程化场景中站稳第一梯队,但在纯推理和视觉理解能力上仍有追赶空间。开源社区的繁荣与商业化变现之间的平衡,将是月之暗面乃至整个行业接下来必须面对的长期考题。在这场博弈中,谁能真正将 AI 技术转化为生产力,谁就能在未来的智能时代掌握主动权。