随着2026年时间的推移,DeepSeek V4的发布窗口从最初预想的农历新年推迟至春季,最终确认将在数周内面世。这一看似寻常的产品延期,却在科技圈引发了远超预期的涟漪。它不再仅仅是一个大型开源模型的时间表调整,而是一场关于中国AI底层技术路线的深刻压力测试。在这场测试中,核心矛盾聚焦于一个尖锐的问题:是继续沿着兼容CUDA的路径艰难前行,还是彻底切断依赖,构建完全自主的AI生态体系?
DeepSeek V4作为一款预计参数规模达到万亿级、支持百万token上下文的多模态开源模型,其技术野心不言而喻。为了实现这一目标,DeepSeek工程团队不得不面对一个严峻的现实挑战:如何将原本为英伟达CUDA生态量身定制的庞大代码库,系统性迁移至华为昇腾芯片及CANN框架之上。这不仅仅是一次简单的代码移植,更是对底层硬件拓扑、通信协议以及软件栈成熟度的极限挑战。
工程层面的“硬骨头”:从纯计算到系统调度的跨越
深入分析DeepSeek V4的技术架构,我们可以发现其采用了更为激进的MoE(专家混合)架构。这种架构虽然在理论上通过“按需激活专家”的方式降低了单次推理的计算量,但对系统的整体调度能力提出了极其苛刻的要求。它不再仅仅是CPU或GPU在“算得快”,而是需要内存带宽、芯片间互联(Interconnect)以及KV Cache管理达到极致的协同。
在英伟达的生态闭环中,这套问题有着相对成熟的解决方案。基于H100或B200等硬件,通过NVLink与NVSwitch构建的高带宽互联网络,能够以TB/s级别的单节点GPU间带宽,形成一个近似“全连通”的计算网络。数据在芯片间的流动如同在高速公路上飞驰,延迟与同步成本被压缩到了物理极限。然而,当DeepSeek试图将这套精密体系迁移至华为昇腾平台时,面对的是完全不同的物理现实。
尽管昇腾芯片近年来进步显著,但在超大规模集群的“全连通能力”上,与英伟达仍存在不可忽视的物理层差距。受制于制程工艺与SerDes IP(知识产权)能力的限制,昇腾更多依赖光模块进行跨节点扩展。这种“以空间换带宽”的方案虽然在逻辑上行得通,却引入了更长的物理链路,从而带来了信号延迟增加、同步开销变大以及功耗与散热管理复杂等一系列连锁反应。
与此同时,软件层面的差距同样严峻。昇腾的CANN框架在算子覆盖的广度、自动并行的智能化程度、内核融合的深度以及分布式通信的调度效率等方面,整体成熟度仍落后于CUDA生态。这意味着DeepSeek的工程团队需要在大量底层细节上进行针对性优化,甚至需要手动重写关键算子。这种落后往往不是线性的,而是系统性的。一个算子的性能下降,可能像蝴蝶效应一样影响整条计算链路;一次通信效率的降低,可能导致整体吞吐量出现剧烈波动。最终的结果往往是模型虽然能够运行,但距离稳定、高效、可规模化的工业级应用还有很长的路要走。
从这个角度看,DeepSeek V4的延期,并非简单的产品节奏管理问题,而是中国顶尖算法团队与国产芯片体系之间深度磨合的必然代价。这一过程虽然艰难,却释放出一个清晰的信号:AI的竞争,正在从单纯的“模型能力比拼”,转向“系统工程能力比拼”。在这一阶段,谁能更快把模型“跑起来、跑稳定、跑便宜”,谁才真正接近产业级的竞争优势。
CUDA的垄断壁垒:为何迁移如此艰难?
如果将视线从DeepSeek V4的适配困难中抽离,我们会发现一个更本质的疑问:为什么只是把模型从一个算力平台迁移到另一个平台,会变得如此困难?这并非技术细节的简单叠加,而是生态锁定的结果。
回看PC时代,Wintel联盟虽然垄断了市场,但微软与英特尔之间存在利益博弈,这为后来Linux、AMD乃至苹果系统的崛起预留了空间。然而,英伟达在AI领域建立的是一种“单体垂直垄断”,其本质是微软与英特尔的合体。在硬件层面,英伟达定义了SM(流式多处理器)的物理结构和Tensor Core的计算逻辑;在软件层面,CUDA提供了与之1:1完美契合的闭源库,如cuBLAS、cuDNN等。
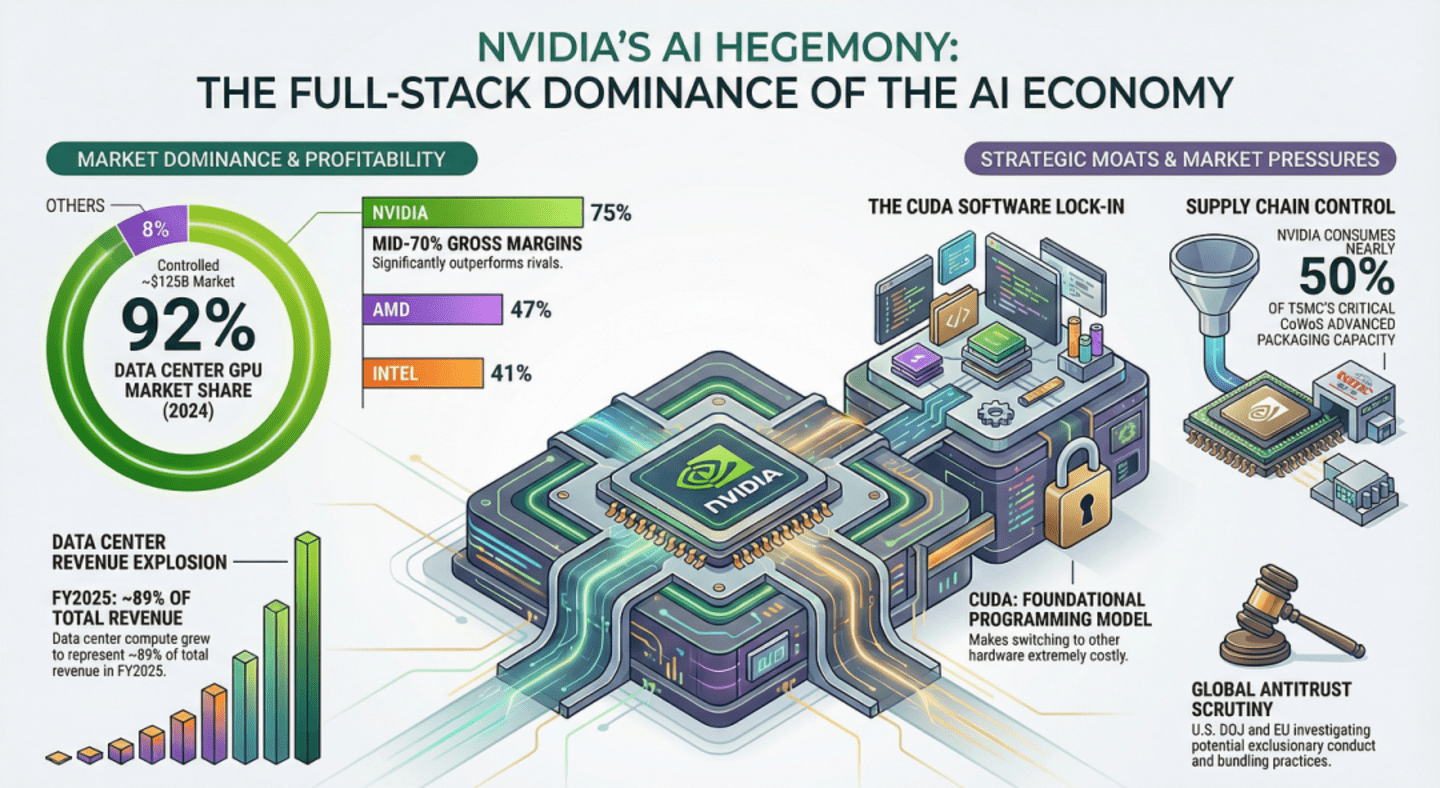
这种软硬一体化的设计,导致了一个极其恐怖的现实:全球600万以上的开发者围绕cuBLAS、cuDNN、NVLink/NVSwitch优化算法,框架(如PyTorch、TensorFlow)优先实现CUDA版本,甚至AWS Trainium与Cerebras WSE的“反NVIDIA”异构集群,在KV缓存迁移时仍需依赖NVIDIA NIXL软件和AWS EFA。这已不是单点的技术细节问题,而是生态的惯性。模型可移植性失效前,开发者“用英伟达硬件特性语言思考”已成为一种思维定势。正是这种生态惯性,让英伟达像一个巨大的黑洞,吸纳了全球90%以上的创新红利。
在上述背景下,作为其最强有力竞争者的华为CANN,最初确实试图走一条相对独立的路线。但随着大模型时代的到来,这种完全自立的路径逐渐显露出问题。开发者不愿迁移,企业不敢承担风险,生态增长缓慢。加之大模型快速迭代的时间压力,完全独立的路径变得不再现实。基于此,CANN逐步引入了类似CUDA的抽象层设计。例如在CANN Next中,尝试对标cuBLAS、cuDNN接口,实现高比例的兼容性,使模型迁移成本从“数周甚至数月”压缩至“小时级”。在架构层面,新近发布的950PR异构架构(预填充/解码解耦)也刻意模仿英伟达的解耦式服务,而非谷歌TPU的彻底异构路线。
这种“兼容优先”的策略在短期内是成功的。它降低了门槛,使昇腾迅速在国内市场获得应用基础,让像DeepSeek、腾讯、字节跳动等公司能够以较低的门槛尝试国产算力。CANN Next通过SIMT编程模型实现了高达95%以上的CUDA兼容性,已帮助多家企业将迁移时间大幅缩短至小时级,加速了实际落地。
兼容的陷阱:短期生存与长期发展的博弈
然而,随之而来的挑战是,一旦涉及前沿创新,兼容层就会变成“天花板”。当开发者真正深入使用昇腾平台时,会发现虽然常见路径已经被铺平,但一旦涉及一些冷门、创新的底层算子,CANN的支持度就会下降,性能抖动剧烈。
DeepSeek V4在适配过程中遇到的困难,很大程度上是因为其在尝试引入SSM(状态空间模型)或Mamba这类非Transformer结构的混合架构时,发现CANN的底层优化仍主要向矩阵乘法(GEMM)倾斜。这种困境,很大程度上是因为其在尝试超越常规的算法优化时,撞到了CANN兼容层的“边界”。更深层的问题在于,一旦选择兼容,就意味着默认CUDA仍然是隐形标准。你可以替换硬件,但在软件语义和开发范式上,仍然在沿用对方定义的规则。这既是捷径,也是限制。
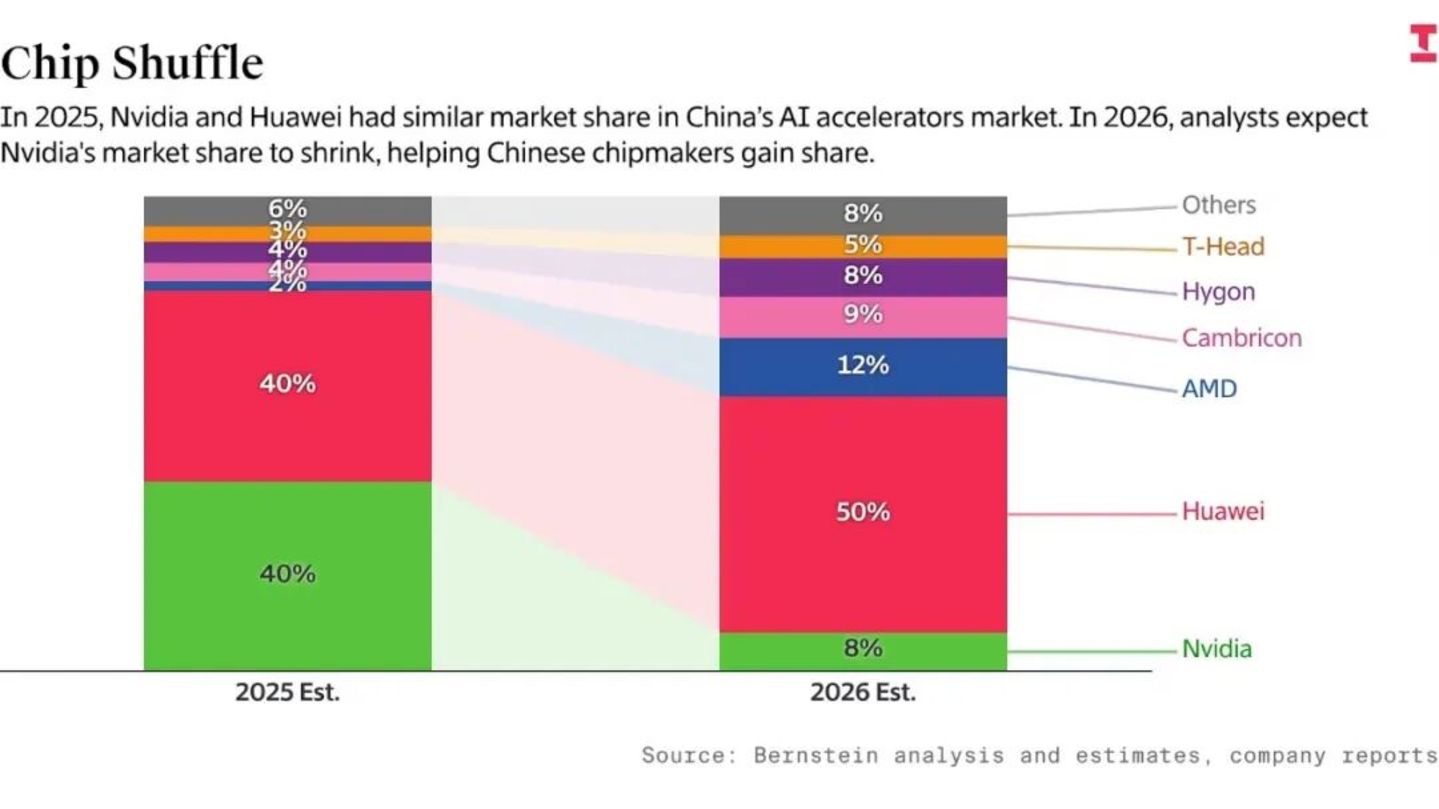
从短期来看,兼容几乎是必然结果,这是效率与现实的选择。但从长期来看,这条路径隐藏着不容忽视的风险。当一个系统(如CANN)为了兼容另一个系统(如CUDA)而设计时,它不可避免地会继承对方的局限性。事实是,目前全球大部分开源算法都是围绕英伟达架构开发的。如果为了利用这些存量资产而一味追求1:1兼容,那么国产芯片在硬件设计上就会陷入“模仿者陷阱”。
这种陷阱表现为:一旦英伟达的硬件架构在未来某个节点面临范式转型,例如从Transformer转向某种不需要大规模矩阵乘法、而是更依赖异步逻辑的新架构时,一直处于“影子状态”的国产算力栈可能会面临瞬间的技术断层。这种“Bug对Bug兼容”的死胡同,无疑让底层创新始终笼罩在别人的阴影之下。
更深层的风险在于“时间差”。根据伯恩斯坦和Epoch AI的统计数据,虽然华为在国内份额激增,但在全球AI算力总量中,国产芯片的占比仅为5%,仍属相对有限。这种绝对规模的差距,导致了严重的“研发效率摩擦”。美国AI巨头可以利用Blackwell强大的通信带宽,在18个月内跑通10T参数的Scaling Laws,而中国的顶尖人才却不得不将50%以上的科研产能消耗在“如何解决老旧芯片的信号衰减”和“适配不成熟的编译器”等问题上。
需要说明的是,上述时间上的错位,在瞬息万变的AI时代会被无限放大。当我们的人才还在忙于“填坑”时,对手可能已经完成了模型能力的指数级复利。这导致对手一年模型的领先,在模型能力、数据飞轮、安全对齐等均呈指数复合增长叠加后,演变为我们在模型能力上与对手形成不止一年的鸿沟。
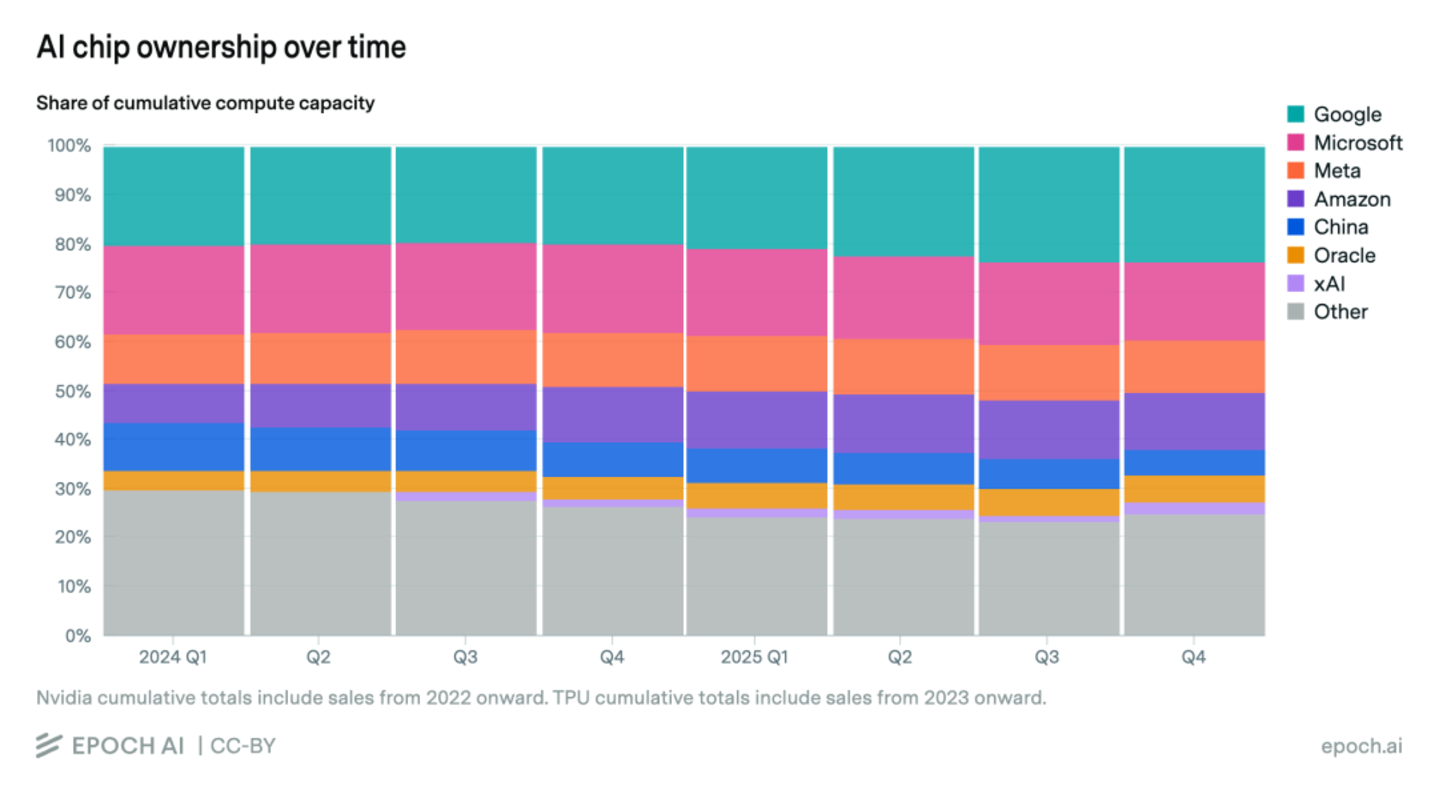
当然,挑战往往蕴含着机遇。DeepSeek V4若成功发布,将证明“国产全栈”的可行性,加速CANN生态的成熟,吸引更多开发者跟进。加之全球“天下苦英伟达久矣”的情绪,业内对CANN的支持或将超出预期。如果华为昇腾等后续芯片能达到H100的80%-90%推理性能,叠加CANN Next的兼容红利,中国AI供应链的临界规模有望在1-2年内形成。
但需要清醒认识的是,兼容只能解决“活下来”的问题,真正的自立,才能决定“走多远”。未来3-5年,将是一个关键窗口期。如果我们能够在保持兼容的同时,逐步建立独立的编程模型、算子体系与系统架构,中国AI生态仍有机会实现从跟随到定义规则的跃迁。否则,中国AI或将陷入“粗糙复制列车”的轨道,长期在别人的规则下跳舞。
DeepSeek V4的延期发布,看似偶然的“跳票”,实则揭示了一个更深层的现实:AI竞争早已不只是模型之争,而是底层生态与系统能力的全面较量。兼容CUDA固然是通往现实的最短路径,但若止步于此,也可能锁定未来的天花板。真正的挑战,不在于能否替代一套技术,而在于能否摆脱对既有范式的依赖,构建属于自己的规则体系。接下来的3-5年,将决定中国AI是成为全球生态中的重要一极,还是长期停留在“高水平跟随”的位置。在追求自立的同时,也需警惕封闭生态可能对全球开发者吸引力的潜在影响,以确保生态的开放性和长期国际竞争力。