从审美竞赛到生产工具:图像生成技术的范式转移
过去几年,文生图行业的主旋律一直是审美竞赛。各大模型争相比拼谁能拍出更有氛围感的大片,谁能在社交媒体上制造更惊艳的瞬间。然而,真正卡住商业落地的,从来不是“像不像艺术”,而是“能不能交付”。
海报里的字写不对,包装上的品牌名不一致,信息图只能远看不能细读,局部编辑一改就整张图重画,角色一致性一到多张图就崩,复杂版式一上密度就失真。这些问题让许多模型长期停留在“适合演示,不适合生产”的阶段。设计团队在展示环节惊艳全场,却在落地执行时因细节失真而频频受挫。

OpenAI刚刚发布的Images 2.0,正是为了打破这一僵局。它不只是“图片更好看了”,更重要的是图像生成第一次更像一个能进入真实工作流的生产系统。通过更强的真实世界知识、更稳的复杂指令遵循、更高密度的文字渲染,以及更接近“先理解任务、再组织画面”的思考工作流,Images 2.0让品牌、内容、电商、产品这些原本对准确性要求极高的团队,第一次看到了图像模型进入正式流程的可能。
高密度文字海报:从装饰性假字到真实交付
在传统的图像生成任务中,文字往往是重灾区。早期模型非常擅长制造“像海报的东西”,但一旦放大细节,文字内容便显得不可信:字母残缺、数字错位、中英混杂、排版层级崩塌。这并非审美问题,而是模型在图像空间里对文字这种离散符号的控制力不足。
Images 2.0的突破点在于对密集文字(dense text)和指令遵循(instruction following)的深刻理解。它不再只是“画出字的形状”,而是在一定程度上理解“这里必须是精确的标题、日期、地点、列表”。
实战提示词策略:
“请生成一张面向科技行业观众的大会主视觉海报,尺寸为竖版4:5,整体风格极简、克制、偏高级发布会视觉。背景为温和的米白色纸张质感,中央有一块深灰色矩形信息区。请准确排版以下文字,所有文字必须清晰、可读、无乱码、无错字: 主标题:AI WORKDAY 2026 副标题:Agents, Memory, Tools, and the Future of Real Work 日期:2026年6月18日 地点:上海西岸艺术中心B馆 ... 右下角有一个二维码占位框,框下写Register Now。 要求中英混排自然,字距和层级像真实设计师排版,不能出现随机拼写,不能丢字,不能把文字做成装饰性假字。整体像能直接用在公众号头图和活动落地页首屏的正式KV。”

提升成功率的关键:
- 逐行明确: 不要笼统地说“做一个有会议信息的海报”,而是将主标题、副标题、日期、列表、按钮分别列出。
- 层级约束: 清晰定义信息层级,并明确告知模型“不要装饰性假字”、“必须可读”。
- 交付标准: 补充“像真实设计交付而不是概念图”的指令,这会显著提升结构感。
复杂信息图与UI界面:结构能力与语义理解的双重考验
信息图是生成任务中的高难度领域。它考察的不是绘画能力,而是结构能力。模型需要同时理解布局、层级、颜色、标题、段落、时间轴、图标和整页的阅读路径。过去的模型一旦信息量上来,就容易变成“看起来像PPT截图”,但内容无法真正阅读,更不用说保持严谨的视觉逻辑。
Images 2.0在此类任务上展现出了极强的规划能力。它理解四个阶段之间存在顺序关系、对比关系和信息密度差异。Thinking mode在这种场景下尤其有价值,它会让模型先组织结构,再落图,而不是边猜边画。
对于UI界面设计,旧模型最大的问题是“懂长相,不懂功能”。它知道仪表盘应该有侧边栏、卡片、按钮,但不知道哪些信息应该放在哪。而新一代模型凭借对世界知识的掌握,能够理解企业软件的产品语义,知道客户列表、AI建议面板的标准布局。
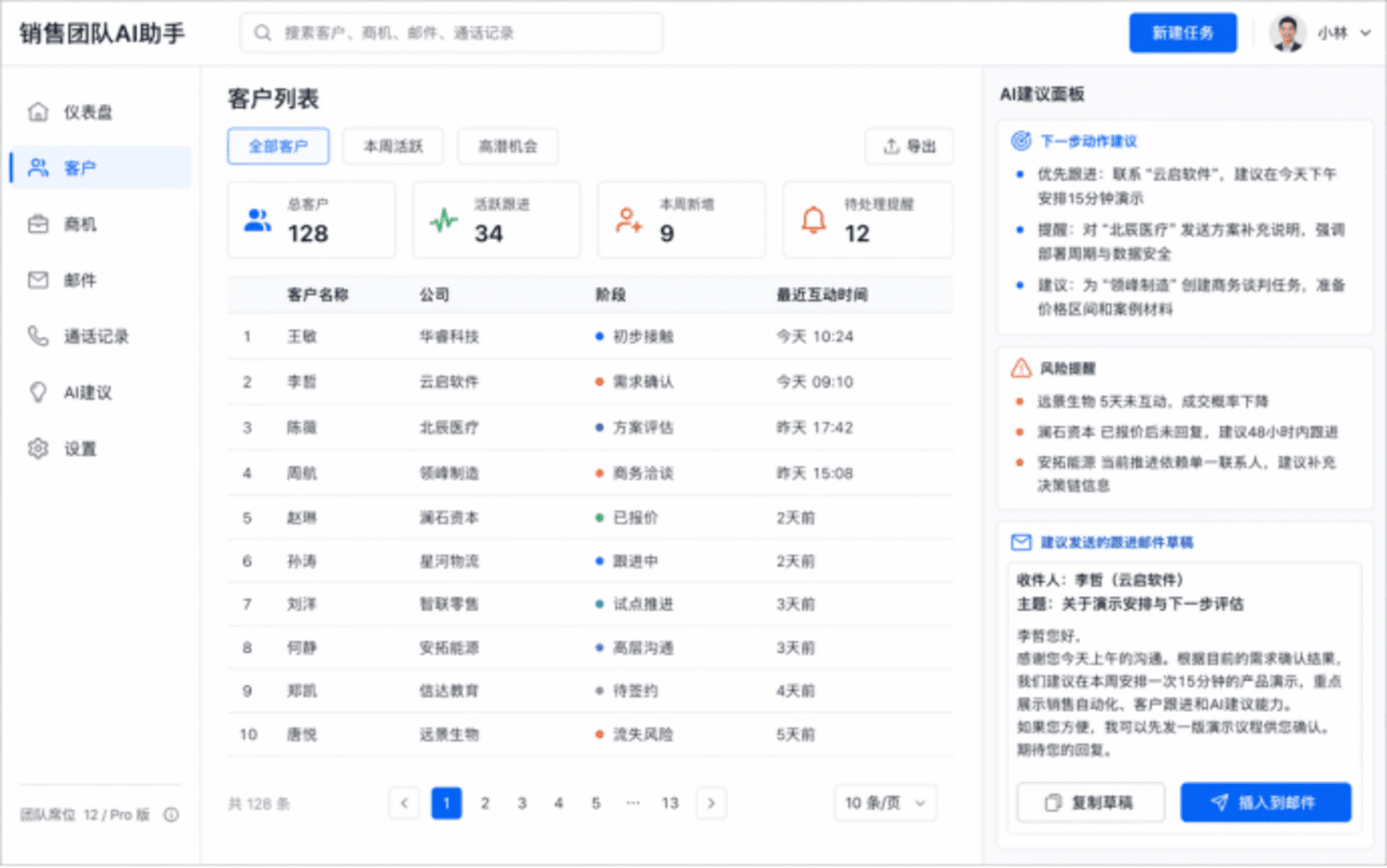
实操建议:
- 结构先行: 将每个模块的标题、说明和相对位置写清楚。例如:“画面横版,分成四列,每列一个阶段卡片...底部有一条时间轴”。
- 风格约束: 指定“像麦肯锡或红杉资本会使用的报告图表,清晰、可读、可用于演讲材料”。
- 参考系: 对于UI,可以补充“以Salesforce、HubSpot风格的专业度为参考,但不要直接复制品牌”,并指定“浅色主题、12栏栅格”。
包装设计与多对象控制:一致性系统的构建
包装设计的难点在于“多约束同时成立”。既要统一品牌系统,又要让不同SKU有区分,既要好看,又要信息真实,还要保证品牌名拼写一致。旧模型经常能画出漂亮的罐子,但品牌名每个角度都不一样,净含量像乱码。
Images 2.0展现了惊人的一致性、文字稳定性和风格系统能力。它不只是做一张图,而是在做一个小型品牌体系。同样,在多对象精确绑定的任务中,模型开始更能把“对象A的颜色、对象B的位置、对象C的材质”分别绑定起来,解决了早期模型计数失败、顺序错乱、属性串位的经典弱点。
包装与多对象提示词技巧:
“设计一套精品冷萃咖啡的包装系统,品牌名为North Canal Coffee。请同时展示三罐产品:Ethiopia Light Roast、House Blend、Dark Night Espresso。要求品牌名拼写一致,小字尽量可读,三款产品家族感强...不要华而不实。”
“制作一张俯拍静物图...从左到右、从上到下分成三行四列,每个物体都不同,且必须严格对应以下顺序:第一行:红色三角尺、蓝色钢笔...第三行:透明胶带。不得增加额外物体。”


成功策略:
- 核心字段独立: 将品牌名、SKU名、净含量等核心字段单独列出强调。
- 严格约束: 明确“品牌名全图一致”,“像真实消费品而不是概念渲染图”。
- 顺序定义: 在多物体任务中,明确“从左到右、从上到下”的顺序,必要时指定“像电商平铺目录图”。
角色一致性与场景细节:从单张图到叙事与真实世界
跨帧一致性是生成模型最实用也最难的一块。在四格漫画或连续故事中,过去模型常在第2、3格改变角色特征。Images 2.0通过更强的身份连续性能力,能够维持一个“角色对象”的稳定存在。对于漫画、广告脚本、视频分镜,这种能力是质的飞跃。
此外,在写实摄影场景中,模型对城市语义、透视、密集文字、局部细节的理解也大幅提升。它不仅能画出“纽约味道”,更能画出“纽约规则系统”,将真实的市政标识、停车规则等细节完美融入街景。


优化建议:
- 角色拆解: 将人物外观拆成清单(发型、眼镜、服装),并明确“同一个人,不能换脸”。
- 场景真实: 指定“35mm documentary photography”,并强调标牌需“像真实存在于同一条街上”。
局部编辑与推理构图:尊重原图与深度理解
旧模型在编辑任务中常产生“灾难性重绘”,用户只想换个沙发,结果墙变了、光线也变了。Images 2.0在编辑可控性上表现出色,能够尊重原图,仅对指定区域进行修改。
更值得注意的是“推理型构图”能力。面对抽象命题,旧模型会退回到模板化视觉符号(如机器人脑袋、电路板)。而Images 2.0能先理解文章观点,再决定用什么视觉隐喻,实现了“理解并且回答一个命题”的生成过程。


操作指南:
- 反向约束: 把“不允许改变”的内容写得比“允许改变”的内容还清楚。
- 理解优先: 提示词中加入“请先理解这个标题的含义,再构思...传达观点”。
- 风格规避: 明确列出不要的元素,如“不要机器人脸、不要蓝色电路板”。
多图生成与系统化探索:A/B测试的自动化
在社媒运营中,通常需要同一信息的多版本视觉表达。旧模型在多方案生成时,容易信息丢失、文案漂移。Images 2.0展现了多图生成和系统化视觉探索的能力,让模型参与思考过程,理解“同一信息,不同表达”的逻辑。
提示词范例:
“请一次生成4张风格不同但信息相同的社交媒体新闻图卡...四张图信息一致,但视觉表达明显不同(极简科技媒体风、商业杂志封面风、轻信息图风、摄影拼贴风)。要求所有文字可读,中英混排自然,像真实内容团队在做传播A/B测试。”

结语:迈向可交付的AI创作新时代
Images 2.0的发布不仅仅是技术指标的提升,更是行业工作流的变革。它证明了图像生成模型已经具备了处理复杂指令、保持高精度细节、维护跨帧一致性以及理解抽象逻辑的能力。从演示环节到正式交付,AI绘图终于跨越了“可用”到“好用”的鸿沟。对于追求效率与质量的企业而言,这不仅是多了一个工具,更是开启了一种全新的生产范式。